- Ceph数据恢复方案–分布式文件系统删除数据的恢复
San结构数据恢复
数据恢复相关ceph
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录前言一、Ceph的三种存储结构二、Ceph中删除数据的恢复提取1.本次案例情况简介:2.数据分析:2.1:BlueStore架构2.2分布式存储中元数据概述2.3提取元数据2.3.2:获取meta_data2.3.4.元数据整理2.3.5.计算数据地址3.数据恢复提取总结前言什么是分布式文件系统分布式文件系统(Distribu
- 【服务器数据恢复】数据中心存储服务器VMware vSAN分布式存储架构数据恢复解析
海境超备
服务器分布式架构网络安全系统安全运维
随着企业数据中心的数据量的不断增加,数据存储和恢复成为了企业必须面对的重要问题。vSAN(VirtualStorageAreaNetwork)分布式存储架构是一种新型的存储技术,它可以有效地解决企业数据存储和管理方面的问题。本文将详细介绍vSAN分布式存储架构的原理和特点,并解析其数据恢复的原理和方法。分布式文件系统(DistributedFileSystem,DFS)是一种能够在多台计算机之间共
- Fastdfs-V5.11使用docker部署集群(X86)
礁之
Linux系列dfsjavadocker
文章目录一、Fastdfs介绍二、部署信息三、步骤tracker/storage机器的compose内容storage机器的composetracker与storage启动目录层级与配置文件client.confstorage.conf查看集群信息测试测试集群扩容与缩减nginx配置一、Fastdfs介绍FastDFS是一款高性能的分布式文件系统,特别适合用于存储和管理大量的文件二、部署信息使用d
- 数据中台(二)数据中台相关技术栈
Yuan_CSDF
#数据中台
1.平台搭建1.1.Amabari+HDP1.2.CM+CDH2.相关的技术栈数据存储:HDFS,HBase,Kudu等数据计算:MapReduce,Spark,Flink交互式查询:Impala,Presto在线实时分析:ClickHouse,Kylin,Doris,Druid,Kudu等资源调度:YARN,Mesos,Kubernetes任务调度:Oozie,Azakaban,AirFlow,
- Hadoop相关面试题
努力的搬砖人.
java面试hadoop
以下是150道Hadoop面试题及其详细回答,涵盖了Hadoop的基础知识、HDFS、MapReduce、YARN、HBase、Hive、Sqoop、Flume、ZooKeeper等多个方面,每道题目都尽量详细且简单易懂:Hadoop基础概念类1.什么是Hadoop?Hadoop是一个由Apache基金会开发的开源分布式计算框架,主要用于处理和存储大规模数据集。它提供了高容错性和高扩展性的分布式存
- Flink读取kafka数据并写入HDFS
王知无(import_bigdata)
Flink系统性学习专栏hdfskafkaflink
硬刚大数据系列文章链接:2021年从零到大数据专家的学习指南(全面升级版)2021年从零到大数据专家面试篇之Hadoop/HDFS/Yarn篇2021年从零到大数据专家面试篇之SparkSQL篇2021年从零到大数据专家面试篇之消息队列篇2021年从零到大数据专家面试篇之Spark篇2021年从零到大数据专家面试篇之Hbase篇
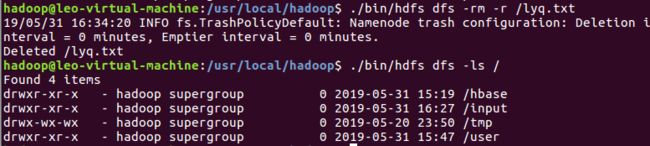
- Hadoop 实战笔记(二)-- HDFS 常用 shell 命令总结
dazhong2012
Hadoophdfshadoop
一、HDFS命令显示当前目录结构#显示当前目录结构hadoopfs-ls#递归显示当前目录结构hadoopfs-ls-R#显示根目录下内容hadoopfs-ls/创建目录#创建目录hadoopfs-mkdir#递归创建目录hadoopfs-mkdir-p删除操作#删除文件hadoopfs-rm#递归删除目录和文件hadoopfs-rm-R从本地加载文件到HDFS#二选一执行即可hadoopfs-p
- HarmonyNext实战:基于ArkTS的跨设备文件同步与冲突解决案例详解
harmonyos-next
HarmonyNext实战:基于ArkTS的跨设备文件同步与冲突解决案例详解在现代多设备协同的场景中,文件同步是一个常见的需求。然而,跨设备文件同步往往会面临冲突问题,例如同一文件在不同设备上被同时修改。HarmonyOSNext提供了强大的分布式文件系统和冲突解决机制,帮助开发者实现高效、可靠的跨设备文件同步。本文将深入探讨如何在HarmonyOSNext中使用ArkTS实现跨设备文件同步与冲突
- 【Go基础】Go入门与实践资源帖
小超人冲鸭
golang开发语言后端
看到好的持续更新……Go系统教程从语法讲起:李文周博客七天快速上手项目Go测试驱动开发博客孔令飞项目开发实战课程,孔令飞图文教程《Go语言高级编程》书籍Go算法刷题模板Go实战项目KV系统crawlab分布式爬虫平台seaweedfs分布式文件系统Cloudreve云盘系统gfast后台管理系统(基于GoFrame)alist多存储文件列表(基于Gin、React)Yearning开源SQL审核平
- 中电金信25/3/18面前笔试(需求分析岗+数据开发岗)
苍曦
需求分析前端javascript
部分相同题目在第二次数据开发岗中不做解析,本次解析来源于豆包AI,正确与否有待商榷,本文只提供一个速查与知识点的补充。一、需求分析第1题,单选题,Hadoop的核心组件包括HDFS和以下哪个?MapReduceSparkStormFlink解析:Hadoop的核心组件是HDFS(分布式文件系统)和MapReduce(分布式计算框架)。Spark、Storm、Flink虽然也是大数据处理相关技术,但
- Spark集群启动与关闭
陈沐
sparksparkhadoopbigdata
Hadoop集群和Spark的启动与关闭Hadoop集群开启三台虚拟机均启动ZookeeperzkServer.shstartMaster1上面执行启动HDFSstart-dfs.shslave1上面执行开启YARNstart-yarn.shslave2上面执行开启YARN的资源管理器yarn-daemon.shstartresourcemanager(如果nodeManager没有启动(正常情况
- 智慧社区2.0
陈陈爱java
java
项目亮点1.技术架构层面✅多数据源整合(MySQL+Redis+HDFS+OSS)核心亮点:不仅仅是单一数据库,而是根据数据特性使用MySQL(结构化数据)+Redis(缓存)+HDFS(大数据存储)+OSS(对象存储),提高了系统的数据存储效率和查询速度。面试时可以强调:Redis作为缓存,加速社区热点数据访问,减少MySQL压力。HDFS存储海量日志和AI任务数据,支持后续分析。OSS解决图片
- DeepSeek 3FS 与 JuiceFS:架构与特性比较
运维人工智能
近期,DeepSeek开源了其文件系统Fire-FlyerFileSystem(3FS),使得文件系统这一有着70多年历时的“古老”的技术,又获得了各方的关注。在AI业务中,企业需要处理大量的文本、图像、视频等非结构化数据,还需要应对数据量的爆炸式增长,分布式文件系统因此成为AI训练的关键存储技术。本文旨在通过深入分析3FS的实现机制,并与JuiceFS进行对比,以帮助用户理解两种文件系统的区别及
- Hadoop MapReduce 词频统计(WordCount)代码解析教程
我不是少爷.
Java基础hadoopmapreduce大数据
一、概述这是一个基于HadoopMapReduce框架实现的经典词频统计程序。程序会统计输入文本中每个单词出现的次数,并将结果输出到HDFS文件系统。二、代码结构packagecom.bigdata.wc;//Hadoop核心类库导入importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.Path;//数据类型定义
- hadoop集群关闭命令顺序_启动和关闭Hadoop集群命令步骤
氪老师
hadoop集群关闭命令顺序
启动和关闭Hadoop集群命令步骤总结:1.在master上启动hadoop-daemon.shstartnamenode.2.在slave上启动hadoop-daemon.shstartdatanode.3.用jps指令观察执行结果.4.用hdfsdfsadmin-report观察集群配置情况.5.通过http://npfdev1:50070界面观察集群运行情况.(如果遇到问题看https://
- Flume详解——介绍、部署与使用
克里斯蒂亚诺罗纳尔多阿维罗
flume大数据分布式
1.Flume简介ApacheFlume是一个专门用于高效地收集、聚合、传输大量日志数据的分布式、可靠的系统。它特别擅长将数据从各种数据源(如日志文件、消息队列等)传输到HDFS、HBase、Kafka等大数据存储系统。特点:可扩展:支持大规模数据传输,灵活扩展容错性:支持数据恢复和失败重试,确保数据不丢失多种数据源:支持日志文件、网络数据、HTTP请求、消息队列等多种来源流式处理:数据边收集边传
- hive-进阶版-1
数据牧马人
hivehadoop数据仓库
第6章hive内部表与外部表的区别Hive是一个基于Hadoop的数据仓库工具,用于对大规模数据集进行数据存储、查询和分析。Hive支持内部表(ManagedTable)和外部表(ExternalTable)两种表类型,它们在数据存储、管理方式和生命周期等方面存在显著区别。以下是内部表和外部表的主要区别:1.数据存储位置内部表:数据存储在Hive的默认存储目录下,通常位于HDFS(HadoopDi
- 大数据学习(67)- Flume、Sqoop、Kafka、DataX对比
viperrrrrrr
大数据学习flumekafkasqoopdatax
大数据学习系列专栏:哲学语录:用力所能及,改变世界。如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦工具主要作用数据流向实时性数据源/目标应用场景Flume实时日志采集与传输从数据源到存储系统实时日志文件、网络流量等→HDFS、HBase、Kafka等日志收集、实时监控、实时分析Sqoop关系型数据库与Hadoop间数据同步关系型数据库→Hadoop生态系统(HDFS、Hive、
- hive 数字转换字符串_Hive架构及Hive SQL的执行流程解读
weixin_39756416
hive数字转换字符串
1、Hive产生背景MapReduce编程的不便性HDFS上的文件缺少Schema(表名,名称,ID等,为数据库对象的集合)2、Hive是什么Hive的使用场景是什么?基于Hadoop做一些数据清洗啊(ETL)、报表啊、数据分析可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。Hive是SQL解析引擎,它将SQL语句转译成M/RJob然后在Hadoop执行。由Facebook开源,
- 在hadoop上运行python_hadoop上运行python程序
廷哥带你小路超车
数据来源:http://www.nber.org/patents/acite75_99.zip首先上传测试数据到hdfs:[root@localhost:/usr/local/hadoop/hadoop-0.19.2]#bin/hadoopfs-ls/user/root/test-inFound5items-rw-r--r--1rootsupergroup1012010-10-2414:39/us
- 大数据学习(60)-HDFS文件结构
viperrrrrrr
学习hdfshadoop
&&大数据学习&&系列专栏:哲学语录:承认自己的无知,乃是开启智慧的大门如果觉得博主的文章还不错的话,请点赞+收藏⭐️+留言支持一下博主哦一、体系结构HDFS是一个标准的主从(Master/Slave)体系结构的分布式系统;HDFS集群包含一个或多个NameNode(NameNodeHA会有多个NameNode)和多个DataNode(根据节点情况规划),用户可以通过HDFS客户端同NameNod
- HBase2.6.1部署文档
CXH728
zookeeperhbase
1、HBase概述ApacheHBase是基于Hadoop分布式文件系统(HDFS)之上的分布式、列存储、NoSQL数据库。它适合处理结构化和半结构化数据,能够存储数十亿行和数百万列的数据,并支持实时读写操作。HBase通常应用于需要快速随机读写、低延迟访问以及高吞吐量的场景,例如大规模日志处理、社交网络数据存储等。HBase特性列存储模型:HBase的数据是按列族存储的,适合高稀疏数据。行键分区
- Hadoop、Spark和 Hive 的详细关系
夜行容忍
hadoopsparkhive
Hadoop、Spark和Hive的详细关系1.ApacheHadoopHadoop是一个开源框架,用于分布式存储和处理大规模数据集。核心组件:HDFS(HadoopDistributedFileSystem):分布式文件系统,提供高吞吐量的数据访问。YARN(YetAnotherResourceNegotiator):集群资源管理和作业调度系统。MapReduce:基于YARN的并行处理框架,用
- Zookeeper+kafka学习笔记
CHR_YTU
Zookeeper
Zookeeper是Apache的一个java项目,属于Hadoop系统,扮演管理员的角色。配置管理分布式系统都有好多机器,比如我在搭建hadoop的HDFS的时候,需要在一个主机器上(Master节点)配置好HDFS需要的各种配置文件,然后通过scp命令把这些配置文件拷贝到其他节点上,这样各个机器拿到的配置信息是一致的,才能成功运行起来HDFS服务。Zookeeper提供了这样的一种服务:一种集
- 大数据与hdfs创建文件夹
猫猫头有亿点炸
大数据hdfshadoop
注意事项:在hdfs上操作的文件,创建文件的时候注意他与linux是不一样的(模式如下:)hdfsdfs-mkdir/test1错误示例:否则,无论如何hdfsdfs-ls/test1/都没有文件的
- doris:分析 S3/HDFS 上的文件
向阳1218
大数据doris
通过TableValueFunction功能,Doris可以直接将对象存储或HDFS上的文件作为Table进行查询分析。并且支持自动的列类型推断。提示使用方式更多使用方式可参阅TableValueFunction文档:S3:支持S3兼容的对象存储上的文件分析。HDFS:支持HDFS上的文件分析。这里我们通过S3TableValueFunction举例说明如何进行文件分析。自动推断文件列类型>DES
- Hadoop:分布式计算平台初探
dccrtbn6261333
大数据运维java
Hadoop是一个开发和运行处理大规模数据的软件平台,是Apache的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算。Hadoop框架中最核心设计就是:MapReduce和HDFS。MapReduce提供了对数据的计算,HDFS提供了海量数据的存储。MapReduceMapReduce的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释M
- Hadoop:全面深入解析
CloudJourney
hadoop大数据分布式
Hadoop是一个用于大规模数据处理的开源框架,其设计旨在通过集群的方式进行分布式存储和计算。本篇博文将从Hadoop的定义、架构、原理、应用场景以及常见命令等多个方面进行详细探讨,帮助读者全面深入地了解Hadoop。1.Hadoop的定义1.1什么是HadoopHadoop是由Apache软件基金会开发的开源软件框架,用于存储和处理大规模数据。其核心组件包括Hadoop分布式文件系统(HDFS)
- Hadoop介绍:什么是Hadoop?了解Hadoop的应用
Zzzxt007
hadoop大数据分布式
一、认识Hadoop框架Hadoop是一个提供分布式存储和计算的开源软件框架,使用Java语言编写,具有高扩展性、高容错性、无共享和高可用(HA)等特点,非常适合处理海量数据。它基于Google发布的MapReduce论文实现,并且应用了函数式编程的思想。Hadoop框架主要包括HDFS(HadoopDistributedFileSystem,Hadoop分布式文件系统)、MapReduce、YA
- hbase 默认目录_[HBase] HBase数据存储目录解析
weixin_39577422
hbase默认目录
Hbase在hdfs上的存储位置,根目录是由配置项hbase.rootdir决定,默认就是"/hbase"/hbase/WALs在该目录下,对于每个RegionServer,都会对应1~n个子目录/hbase/oldWALs当/hbase/WALs中的HLog文件被持久化到存储文件时,它们就会被移动到/hbase/oldWALs/hbase/hbase.id集群的唯一ID/hbase/hbase.
- 面向对象面向过程
3213213333332132
java
面向对象:把要完成的一件事,通过对象间的协作实现。
面向过程:把要完成的一件事,通过循序依次调用各个模块实现。
我把大象装进冰箱这件事为例,用面向对象和面向过程实现,都是用java代码完成。
1、面向对象
package bigDemo.ObjectOriented;
/**
* 大象类
*
* @Description
* @author FuJian
- Java Hotspot: Remove the Permanent Generation
bookjovi
HotSpot
openjdk上关于hotspot将移除永久带的描述非常详细,http://openjdk.java.net/jeps/122
JEP 122: Remove the Permanent Generation
Author Jon Masamitsu
Organization Oracle
Created 2010/8/15
Updated 2011/
- 正则表达式向前查找向后查找,环绕或零宽断言
dcj3sjt126com
正则表达式
向前查找和向后查找
1. 向前查找:根据要匹配的字符序列后面存在一个特定的字符序列(肯定式向前查找)或不存在一个特定的序列(否定式向前查找)来决定是否匹配。.NET将向前查找称之为零宽度向前查找断言。
对于向前查找,出现在指定项之后的字符序列不会被正则表达式引擎返回。
2. 向后查找:一个要匹配的字符序列前面有或者没有指定的
- BaseDao
171815164
seda
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class BaseDao {
public Conn
- Ant标签详解--Java命令
g21121
Java命令
这一篇主要介绍与java相关标签的使用 终于开始重头戏了,Java部分是我们关注的重点也是项目中用处最多的部分。
1
- [简单]代码片段_电梯数字排列
53873039oycg
代码
今天看电梯数字排列是9 18 26这样呈倒N排列的,写了个类似的打印例子,如下:
import java.util.Arrays;
public class 电梯数字排列_S3_Test {
public static void main(S
- Hessian原理
云端月影
hessian原理
Hessian 原理分析
一. 远程通讯协议的基本原理
网络通信需要做的就是将流从一台计算机传输到另外一台计算机,基于传输协议和网络 IO 来实现,其中传输协议比较出名的有 http 、 tcp 、 udp 等等, http 、 tcp 、 udp 都是在基于 Socket 概念上为某类应用场景而扩展出的传输协
- 区分Activity的四种加载模式----以及Intent的setFlags
aijuans
android
在多Activity开发中,有可能是自己应用之间的Activity跳转,或者夹带其他应用的可复用Activity。可能会希望跳转到原来某个Activity实例,而不是产生大量重复的Activity。
这需要为Activity配置特定的加载模式,而不是使用默认的加载模式。 加载模式分类及在哪里配置
Activity有四种加载模式:
standard
singleTop
- hibernate几个核心API及其查询分析
antonyup_2006
html.netHibernatexml配置管理
(一) org.hibernate.cfg.Configuration类
读取配置文件并创建唯一的SessionFactory对象.(一般,程序初始化hibernate时创建.)
Configuration co
- PL/SQL的流程控制
百合不是茶
oraclePL/SQL编程循环控制
PL/SQL也是一门高级语言,所以流程控制是必须要有的,oracle数据库的pl/sql比sqlserver数据库要难,很多pl/sql中有的sqlserver里面没有
流程控制;
分支语句 if 条件 then 结果 else 结果 end if ;
条件语句 case when 条件 then 结果;
循环语句 loop
- 强大的Mockito测试框架
bijian1013
mockito单元测试
一.自动生成Mock类 在需要Mock的属性上标记@Mock注解,然后@RunWith中配置Mockito的TestRunner或者在setUp()方法中显示调用MockitoAnnotations.initMocks(this);生成Mock类即可。二.自动注入Mock类到被测试类 &nbs
- 精通Oracle10编程SQL(11)开发子程序
bijian1013
oracle数据库plsql
/*
*开发子程序
*/
--子程序目是指被命名的PL/SQL块,这种块可以带有参数,可以在不同应用程序中多次调用
--PL/SQL有两种类型的子程序:过程和函数
--开发过程
--建立过程:不带任何参数
CREATE OR REPLACE PROCEDURE out_time
IS
BEGIN
DBMS_OUTPUT.put_line(systimestamp);
E
- 【EhCache一】EhCache版Hello World
bit1129
Hello world
本篇是EhCache系列的第一篇,总体介绍使用EhCache缓存进行CRUD的API的基本使用,更细节的内容包括EhCache源代码和设计、实现原理在接下来的文章中进行介绍
环境准备
1.新建Maven项目
2.添加EhCache的Maven依赖
<dependency>
<groupId>ne
- 学习EJB3基础知识笔记
白糖_
beanHibernatejbosswebserviceejb
最近项目进入系统测试阶段,全赖袁大虾领导有力,保持一周零bug记录,这也让自己腾出不少时间补充知识。花了两天时间把“传智播客EJB3.0”看完了,EJB基本的知识也有些了解,在这记录下EJB的部分知识,以供自己以后复习使用。
EJB是sun的服务器端组件模型,最大的用处是部署分布式应用程序。EJB (Enterprise JavaBean)是J2EE的一部分,定义了一个用于开发基
- angular.bootstrap
boyitech
AngularJSAngularJS APIangular中文api
angular.bootstrap
描述:
手动初始化angular。
这个函数会自动检测创建的module有没有被加载多次,如果有则会在浏览器的控制台打出警告日志,并且不会再次加载。这样可以避免在程序运行过程中许多奇怪的问题发生。
使用方法: angular .
- java-谷歌面试题-给定一个固定长度的数组,将递增整数序列写入这个数组。当写到数组尾部时,返回数组开始重新写,并覆盖先前写过的数
bylijinnan
java
public class SearchInShiftedArray {
/**
* 题目:给定一个固定长度的数组,将递增整数序列写入这个数组。当写到数组尾部时,返回数组开始重新写,并覆盖先前写过的数。
* 请在这个特殊数组中找出给定的整数。
* 解答:
* 其实就是“旋转数组”。旋转数组的最小元素见http://bylijinnan.iteye.com/bl
- 天使还是魔鬼?都是我们制造
ducklsl
生活教育情感
----------------------------剧透请原谅,有兴趣的朋友可以自己看看电影,互相讨论哦!!!
从厦门回来的动车上,无意中瞟到了书中推荐的几部关于儿童的电影。当然,这几部电影可能会另大家失望,并不是类似小鬼当家的电影,而是关于“坏小孩”的电影!
自己挑了两部先看了看,但是发现看完之后,心里久久不能平
- [机器智能与生物]研究生物智能的问题
comsci
生物
我想,人的神经网络和苍蝇的神经网络,并没有本质的区别...就是大规模拓扑系统和中小规模拓扑分析的区别....
但是,如果去研究活体人类的神经网络和脑系统,可能会受到一些法律和道德方面的限制,而且研究结果也不一定可靠,那么希望从事生物神经网络研究的朋友,不如把
- 获取Android Device的信息
dai_lm
android
String phoneInfo = "PRODUCT: " + android.os.Build.PRODUCT;
phoneInfo += ", CPU_ABI: " + android.os.Build.CPU_ABI;
phoneInfo += ", TAGS: " + android.os.Build.TAGS;
ph
- 最佳字符串匹配算法(Damerau-Levenshtein距离算法)的Java实现
datamachine
java算法字符串匹配
原文:http://www.javacodegeeks.com/2013/11/java-implementation-of-optimal-string-alignment.html------------------------------------------------------------------------------------------------------------
- 小学5年级英语单词背诵第一课
dcj3sjt126com
englishword
long 长的
show 给...看,出示
mouth 口,嘴
write 写
use 用,使用
take 拿,带来
hand 手
clever 聪明的
often 经常
wash 洗
slow 慢的
house 房子
water 水
clean 清洁的
supper 晚餐
out 在外
face 脸,
- macvim的使用实战
dcj3sjt126com
macvim
macvim用的是mac里面的vim, 只不过是一个GUI的APP, 相当于一个壳
1. 下载macvim
https://code.google.com/p/macvim/
2. 了解macvim
:h vim的使用帮助信息
:h macvim
- java二分法查找
蕃薯耀
java二分法查找二分法java二分法
java二分法查找
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 2015年6月23日 11:40:03 星期二
http:/
- Spring Cache注解+Memcached
hanqunfeng
springmemcached
Spring3.1 Cache注解
依赖jar包:
<!-- simple-spring-memcached -->
<dependency>
<groupId>com.google.code.simple-spring-memcached</groupId>
<artifactId>simple-s
- apache commons io包快速入门
jackyrong
apache commons
原文参考
http://www.javacodegeeks.com/2014/10/apache-commons-io-tutorial.html
Apache Commons IO 包绝对是好东西,地址在http://commons.apache.org/proper/commons-io/,下面用例子分别介绍:
1) 工具类
2
- 如何学习编程
lampcy
java编程C++c
首先,我想说一下学习思想.学编程其实跟网络游戏有着类似的效果.开始的时候,你会对那些代码,函数等产生很大的兴趣,尤其是刚接触编程的人,刚学习第一种语言的人.可是,当你一步步深入的时候,你会发现你没有了以前那种斗志.就好象你在玩韩国泡菜网游似的,玩到一定程度,每天就是练级练级,完全是一个想冲到高级别的意志力在支持着你.而学编程就更难了,学了两个月后,总是觉得你好象全都学会了,却又什么都做不了,又没有
- 架构师之spring-----spring3.0新特性的bean加载控制@DependsOn和@Lazy
nannan408
Spring3
1.前言。
如题。
2.描述。
@DependsOn用于强制初始化其他Bean。可以修饰Bean类或方法,使用该Annotation时可以指定一个字符串数组作为参数,每个数组元素对应于一个强制初始化的Bean。
@DependsOn({"steelAxe","abc"})
@Comp
- Spring4+quartz2的配置和代码方式调度
Everyday都不同
代码配置spring4quartz2.x定时任务
前言:这些天简直被quartz虐哭。。因为quartz 2.x版本相比quartz1.x版本的API改动太多,所以,只好自己去查阅底层API……
quartz定时任务必须搞清楚几个概念:
JobDetail——处理类
Trigger——触发器,指定触发时间,必须要有JobDetail属性,即触发对象
Scheduler——调度器,组织处理类和触发器,配置方式一般只需指定触发
- Hibernate入门
tntxia
Hibernate
前言
使用面向对象的语言和关系型的数据库,开发起来很繁琐,费时。由于现在流行的数据库都不面向对象。Hibernate 是一个Java的ORM(Object/Relational Mapping)解决方案。
Hibernte不仅关心把Java对象对应到数据库的表中,而且提供了请求和检索的方法。简化了手工进行JDBC操作的流程。
如
- Math类
xiaoxing598
Math
一、Java中的数字(Math)类是final类,不可继承。
1、常数 PI:double圆周率 E:double自然对数
2、截取(注意方法的返回类型) double ceil(double d) 返回不小于d的最小整数 double floor(double d) 返回不大于d的整最大数 int round(float f) 返回四舍五入后的整数 long round