版权申明:本文为博主窗户(Colin Cai)原创,欢迎转帖。如要转贴,必须注明原文网址 http://www.cnblogs.com/Colin-Cai/p/9717119.html 作者:窗户 QQ/微信:6679072 E-mail:[email protected]
看过我其他一些文章的人,可能想象不出我会写一篇关于斐波那契数列的文章。因为可能会感觉1,1,2,3…这样一个数列能讲出什么高深的名堂?嗯,本篇文章的确是关于斐氏数列,但我的目的还是为了说一些应该有95%以上程序员不明白的东西。如果能够跟着我弄明白文中分析的手法,其好处是不言而喻的。请听我细细道来。
斐波那契数列
什么叫斐波那契数列(Fibonacci Sequence)呢?
数学家斐波那契在自己的著作中用兔子繁殖模型引入了这样一个数列:1,1,2,3,5,8,13…
这个数列的第1项和第2项都为1,以后的项都是前面两项之和。
写成递推公式如下:
f(n) = 1 n=1,2
f(n) = f(n-1)+f(n-2) n>2
通项公式
我们都知道对于斐波那契数列,随着n趋向于无穷大,f(n+1)/f(n)是存在极限的,我们在此略去在不知道通项公式的情况下对上述比值存在极限的数学证明(数学里的一切并不是想当然)。
假设有极限,我们知道
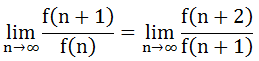
而f(n+2)=f(n+1)+f(n),所以
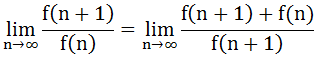
从而
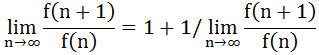
又因为这个极限大于0,解方程得
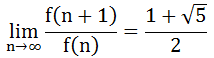
斐波那契数列不仅有递推公式,也有通项公式。
既然上述极限存在,我们完全可以猜测它是多个等差数列的和,然后用待定系数法算出来。
通项公式如下:
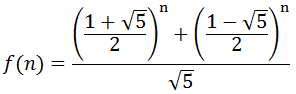
树递归
现在我们就开始本节的重点,如何计算斐波那契数列的第n项。
既然已经知道斐波那契数列的递推公式,那么很容易就给出一个递归函数的版本,因为涉及到大数,我们可以采用Python来描述,本文后续主要采用Python:
def f(n): if n<3: return 1 return f(n-1)+f(n-2)
JavaScript版本当然如下(只可惜不是自身支持大数,需要实现,否则我更愿意用js描述):
function f(n) { if(n<3) return 1; return f(n-1)+f(n-2); }
如果用Scheme或Common Lisp来表示除了前缀表达式古怪一点,看起来也差别不大:
(define (f n) (if (< n 2) 1 (+ (f (- n 1)) (f (- n 2))) ) )
上面是Scheme的描述;Common Lisp只要把开头的define改成defun。
我们用Python来计算一下数列的前40项:
print(map(f, range(1,41)))
运行好慢啊,我的机器上运行了1分多钟才出来了结果
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155]
运算量如此之大,这是怎么回事呢?

我们来看看机器是怎么计算这段递归的,我们就以f(5)的计算为例子:
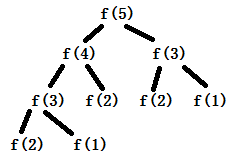
展开就是这么一个样子,树中的每个节点都在计算过程中出现,树的规模是指数级(f(6)比f(5)多了6个节点),也就是运算时间是指数级。
这个太夸张了,难怪这么慢!
带缓存的递归
我们发现上面计算f(5)的递归计算的树里,f(3)是重复展开计算了。从而推断,之所以树递归计算规模这么大,原因就在于出现了大量的重复计算。
于是我们自然就想到了,如何避免计算过的值再次递归展开重复计算呢?换句话说,怎么让计算机知道谁计算过了谁没有计算过?
其实我们只需要引入一段缓存,就可以解决这个问题,程序每当要计算一个值时,先到缓存里查一下就可以避免重复展开了。
我们用Python生成一个数组来做这段cache,没有计算过的是None。代码如下:
#http://cnblogs.com/colin-cai
def f2(n,cache): if cache[n]!=None: return cache[n] ret = f2(n-1, cache) + f2(n-2, cache) cache[n] = ret return ret def f(n): if n<3: return 1 cache = [0,1,1]+[None]*(n-1) return f2(n, cache)
当然,上面缓存刚产生的时候,第0个元为0其实没有用到,算是浪费了,其实去掉这个0再做一点点简单的修改就可以了,这个留给读者吧。
我们还是运算一下数列的前40个元素:
print(map(f, range(1,41)))
结果出的非常之快。
迭代
试想一下,如果让我们在黑板上写出斐波那契数列的前40项,我们会怎么做?
我们会先把数列的第1项和第2项都写成1;
然后从第3项开始,每一项都用前两项相加,算出一项往黑板上写一项,一项一项往前推进,直到写完。
每一项的产生在是相互关联的,而我们之前用Python里的map函数生成数列的前40项,过程中每次调用f都是孤立的。
原来,如果我们的目的是生成斐波那契数列的前n项,刚才写黑板的算法就已经非常棒。用Python描述一下如下:
#http://cnblogs.com/colin-cai
def list_f(n): if n<3: return [1]*n a = [1,1]+[None]*(n-2) for i in range(2,n): a[i]=a[i-1]+a[i-2] return a
这个for循环就是从第3项起不断的算一项写一项的过程。
我们在黑板上写各项的过程中,每次写新项都只关心它前面两项,而在此之前的项根本不关心。我们要生成新的一项,只要每次保持住前面的两项即可。
我们每次都只需要记得当前是第几项,已写数列的最后两项是什么,然后算出新项,然后再只需要记得当前的项数以及最后两项……如此不断反复,直到写完。
这给了我们一个启示,我们其实是在不断的推进状态:
| 当前项数n |
第n-1项 |
第n项 |
| 2 |
1 |
1 |
| 3 |
1 |
2 |
| 4 |
2 |
3 |
| 5 |
3 |
5 |
| … |
… |
… |
我们要计算斐波那契数列的第n项,就不断的如此状态转换,直到当前项数达到我们的要求则停止计算。
于是就有了以下的Python迭代版本:
#http://cnblogs.com/colin-cai
def f(n): if n<3: return 1 stat = {"n":2, "f(n-1)":1, "f(n)":1}; while stat["n"]<n: stat["f(n-1)"],stat["f(n)"] = stat["f(n)"],stat["f(n-1)"]+stat["f(n)"] stat["n"] += 1 return stat["f(n)"]
这个看似有着不错的效率了。
上述迭代的效率
我们试图用上述迭代版本的f计算斐波那契的第1000000项,结果我的计算机花了半分钟以上。
版本中使用了字典,可能效率低一些。于是改用数组来代替字典如下:
#http://cnblogs.com/colin-cai
def f(n): if n<3: return 1 stat = [2,1,1] while stat[0]<n: stat[1],stat[2] = stat[2],stat[1]+stat[2] stat[0] += 1 return stat[2]
甚至于,有人可能觉得完全基于状态推演的迭代看起来不那么亲切,那么咱们换个写法:
#http://cnblogs.com/colin-cai
def f(n): if n<3: return 1 x,y = 1,1 for m in range(2,n): x,y = y,x+y return y
结果发现折腾来折腾去并没有明显的好转。
这个迭代的算法稍有算法功底的人就可以看的出来这是一个线性时间复杂度的算法。但是,我们之所以说是线性时间复杂度是建立在里面的所有加法、比较、赋值操作都是常数级时间。
然而,此处认为加法是常数级时间未必合适。在迭代的过程中,我们的stat[1]、stat[2]的长度应该是在上升的,准确的说,长度应该是线性的,也就是O(n)。从而,加法也是O(n)级的。我们基于此,可以认为整个迭代是O(n2)。于是,我们也就可以理解虽然1000000并不是大到离谱,但迭代计算时间却如此之慢了。
最终算法
我们回头去看看斐波那契数列的通项公式,是可以由两个等比数列合成。
关于求整数次幂显然有快速的算法,乘法的次数为对数级,这个我在之前好几篇博文里都有说到过,可以认为这个是基本算法。
an是n个a相乘,平凡的算法下我们要计算n-1个乘法。
但我们注意到如下的计算:
a×a=a2
a2×a2=a4
a4×a4=a8
a8×a8=a16
a16×a16=a32
a32×a32=a64
…
以上短短的几个乘法就得到了a2、a4、a8、a16、a32、a64 …这些指数都是2的整数次幂。
而我们所要算的幂的指数显然可以表示为二进制,从而表示为1、2、4、8、16、32、64…这些2的整数次幂的一部分之和。
例如我们要算a57,
57用二进制表示为111001,也就是
57=1+8+16+32
所以a57=a×a8×a16×a32
以上的分析表明,快速的求幂算法是存在的。当然,我们甚至没有必要把指数先展开成二进制方式,而是选择直接迭代就可以做出来。
其实,对于
b×an 当然,这里b不为0,n也为非负整数。
如果n=0,那么
b×an = b
此外如果n是偶数,那么
b×an = b×(a×a)n/2
剩下的情况,n是奇数,那么
b×an = (a×b)×(a×a)(n-1)/2
以上三条规则不断迭代1×an自然可以得到最后的解。
以上的分析写成Python如下:
#http://cnblogs.com/colin-cai
def exp(a,n): def exp2(b,a,n): if n==0: return b; elif n%2==0: return exp2(b,a*a,n/2) return exp2(a*b,a*a,(n-1)/2) return exp2(1,a,n)
既然乘方存在快速算法,那么我们就有理由怀疑斐波那契数列求项也存在快速算法。可惜,通项公式里那两个底数都是无理数,近似的算算没大问题,但是不能称之为真正解决的算法。而把幂展开来来推演算法实在太麻烦(悄悄地说,这个真的可行),在这里不作讲解。
我们把之前迭代中每一次向后推一项,状态的转换称之为T变换,也就是
T: (a,b)->(b,a+b)
这是一个函数,
状态我们就用一个元组(tuple)来表示,现在我们用Python改写一下最后出现的那个迭代版本,结果如下:
#http://cnblogs.com/colin-cai
def f(n): if n<3: return 1 T = lambda (a,b):(b,a+b) r = (1,1) for m in range(2,n): r = T(r) return r[1]
顺带说一句,Python就不能学学js那样,用箭头来表示lambda?多简洁啊。
我们可以构造一个算子mul_f来计算两个函数的积,然后通过mul_f算子来构造exp_f算子来计算函数的幂。
那么我们求数列第2项之后的第n项就相当于T变换的n-2次幂作用于(1,1)。
于是我们可以根据这个改写一下代码:
#http://cnblogs.com/colin-cai
def f(n): def mul_f(f1,f2): return lambda x:f1(f2(x)) def exp_f(func, n): if n==0 : return lambda x:x; return mul_f(func, exp_f(func, n-1)) if n<3: return 1 return exp_f(lambda (a,b):(b,a+b),n-2)((1,1))[1]
带有算子、lambda的代码对于不是很习惯于函数式编程的可能看起来有一点难懂,不过这里只要理解了函数的幂即可。
我们利用mul_f函数乘积算子还可以模仿之前快速求幂算法,代码如下:
#http://cnblogs.com/colin-cai
def f(n): def mul_f(f1,f2): return lambda x:f1(f2(x)) def f2(T1,T2,n): if n==0: return T1 elif n%2==0: return f2(T1,mul_f(T2,T2),n/2) return f2(mul_f(T1,T2),mul_f(T2,T2),(n-1)/2) if n<3: return 1 return f2(lambda (a,b):(a,b), lambda (a,b):(b,a+b), n-2)((1,1))[1]
函数在这里运算,代码有点难懂,再继续忍耐忍耐吧,马上就要OK了。
上面的代码里面有一堆函数的运算,但是最终运算还是要落实到实际机器上,从而不仅不减少运算量,甚至还多了一点函数的运算。
说白了,那个mul_f实在太“虚”了。如果我们可以让这里的函数乘积变成真正的数字计算,那么我们上述的思路就成立了。
我们尝试着去手动计算T变换的幂:
T: (a,b)->(b,a+b)
T2: (a,b)->(a+b,a+2b)
T3: (a,b)->(a+2b,2a+3b)
…
T的任何次幂,都是把(a,b)转换为a、b的两个线性组合组成的元组。
于是我们受到了启发:从现在开始,我们完全可以用一个四元组(m,n,p,q)来表示T的任意次幂,也就是上述任何的mul_f的结果。(m,n,p,q)代表
(a,b)->(m*a+n*b,p*a+q*b)
函数的乘法mul_f我们需要仔细想想,写出来似乎长了一点。其他地方简单的改写一下,最后函数求值函数采用lambda的编写就很简单了。最终代码如下:
#http://cnblogs.com/colin-cai
def f(n): mul_f = lambda (m1,n1,p1,q1),(m2,n2,p2,q2) \ : (m2*m1+n2*p1, m2*n1+n2*q1, p2*m1+q2*p1, p2*n1+q2*q1) def f2(T1,T2,n): if n==0: return T1 elif n%2==0: return f2(T1,mul_f(T2,T2),n/2) return f2(mul_f(T1,T2),mul_f(T2,T2),(n-1)/2) if n<3: return 1 return (lambda (m,n,p,q),(a,b) : p*a+q*b)\ (f2((1,0,0,1), (0,1,1,1), n-2),(1,1))
运算一下f(1000000),在我的电脑不到5秒就算了出来。不过看来,计算真未必是Python的长项,它还是做粘合剂比较合适。
当然,最后还是再配上我喜欢的Scheme的实现版本:
(define (f n) (define mul (lambda (a b) (let ((s1 (list (car a) (caddr a))) (s2 (list (cadr a) (cadddr a))) (s3 (list (car b) (cadr b))) (s4 (cddr b)) (c (lambda (x y) (apply + (map * x y))))) (list (c s1 s3) (c s2 s3) (c s1 s4) (c s2 s4))))) (define (f2 T1 T2 n) (cond ((zero? n) T1) ((even? n) (f2 T1 (mul T2 T2) (/ n 2))) (else (f2 (mul T1 T2) (mul T2 T2) (/ (- n 1) 2))))) (if (< n 3) 1 ((lambda (T init) (apply + (map * (cddr T) init))) (f2 '(1 0 0 1) '(0 1 1 1) (- n 2)) '(1 1))))
后记
本文我决定使用Python作为问题描述的主要语言,而不以我以往描述问题习惯使用的C、Scheme、bc,谁叫Python流行呢。
C语言作为“高级汇编”,描述算法确实很吃力,本文中涉及到大数运算,C语言描述并不那么直接;当然,C++也一样不能直接描述大数运算,虽然C++有着很多的抽象能力,比如模板,但它身上有“高级汇编”的根,这点无论怎么包装都是瞒不住的。我是越来越不倾向于用这样底层的语言来描述算法。不过,从底层更加容易理解我这里提到的大数加法的O(n)时间复杂度问题倒是真的。
最后那个对数级的快速算法,我当初是先知道它的存在,然后硬是不看答案甚至不看提示自己推出来,推的过程乃至代码描述和本文有很大的不同。但在写这篇文章的时候,推着推着,觉得文中这样的推理过程更加合理,从而更能让人接受,于是就按文所写了。