【吴恩达课后编程作业】01 - 神经网络和深度学习 - 第四周 - PA1&2 - 一步步搭建多层神经网络以及应用
【吴恩达课后编程作业】01 - 神经网络和深度学习 - 第四周 - PA1&2 - 一步步搭建多层神经网络以及应用
声明
本文参考Kulbear 的 【Building your Deep Neural Network - Step by Step】和【Deep Neural Network - Application】,以及念师的【8. 多层神经网络代码实战】,我基于以上的文章加以自己的理解发表这篇博客,力求让大家以最轻松的姿态理解吴恩达的视频,如有不妥的地方欢迎大家指正。
本文所使用的资料已上传到百度网盘【点击下载】,请在开始之前下载好所需资料,或者在本文底部copy资料代码。
【博主使用的python版本:3.6.2】
开始之前
在正式开始之前,我们先来了解一下我们要做什么。在本次教程中,我们要构建两个神经网络,一个是构建两层的神经网络,一个是构建多层的神经网络,多层神经网络的层数可以自己定义。本次的教程的难度有所提升,但是我会力求深入简出。在这里,我们简单的讲一下难点,本文会提到[LINEAR-> ACTIVATION]转发函数,比如我有一个多层的神经网络,结构是输入层->隐藏层->隐藏层->···->隐藏层->输出层,在每一层中,我会首先计算Z = np.dot(W,A) + b,这叫做【linear_forward】,然后再计算A = relu(Z) 或者 A = sigmoid(Z),这叫做【linear_activation_forward】,合并起来就是这一层的计算方法,所以每一层的计算都有两个步骤,先是计算Z,再计算A,你也可以参照下图:

我们来说一下步骤:
初始化网络参数
前向传播
2.1 计算一层的中线性求和的部分
2.2 计算激活函数的部分(ReLU使用L-1次,Sigmod使用1次)
2.3 结合线性求和与激活函数
计算误差
反向传播
4.1 线性部分的反向传播公式
4.2 激活函数部分的反向传播公式
4.3 结合线性部分与激活函数的反向传播公式
更新参数
请注意,对于每个前向函数,都有一个相应的后向函数。 这就是为什么在我们的转发模块的每一步都会在cache中存储一些值,cache的值对计算梯度很有用, 在反向传播模块中,我们将使用cache来计算梯度。 现在我们正式开始分别构建两层神经网络和多层神经网络。
准备软件包
在开始我们需要准备一些软件包:
import numpy as np
import h5py
import matplotlib.pyplot as plt
import testCases #参见资料包,或者在文章底部copy
from dnn_utils import sigmoid, sigmoid_backward, relu, relu_backward #参见资料包
import lr_utils #参见资料包,或者在文章底部copy
- 1
- 2
- 3
- 4
- 5
- 6
软件包准备好了,我们开始构建初始化参数的函数。
为了和我的数据匹配,你需要指定随机种子
np.random.seed(1)
- 1
初始化参数
对于一个两层的神经网络结构而言,模型结构是线性->ReLU->线性->sigmod函数。
初始化函数如下:
def initialize_parameters(n_x,n_h,n_y):
"""
此函数是为了初始化两层网络参数而使用的函数。
参数:
n_x - 输入层节点数量
n_h - 隐藏层节点数量
n_y - 输出层节点数量
返回:
parameters - 包含你的参数的python字典:
W1 - 权重矩阵,维度为(n_h,n_x)
b1 - 偏向量,维度为(n_h,1)
W2 - 权重矩阵,维度为(n_y,n_h)
b2 - 偏向量,维度为(n_y,1)
"""
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
#使用断言确保我的数据格式是正确的
assert(W1.shape == (n_h, n_x))
assert(b1.shape == (n_h, 1))
assert(W2.shape == (n_y, n_h))
assert(b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
初始化完成我们来测试一下:
print("==============测试initialize_parameters==============")
parameters = initialize_parameters(3,2,1)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
- 1
- 2
- 3
- 4
- 5
- 6
测试结果:
==============测试initialize_parameters==============
W1 = [[ 0.01624345 -0.00611756 -0.00528172]
[-0.01072969 0.00865408 -0.02301539]]
b1 = [[ 0.]
[ 0.]]
W2 = [[ 0.01744812 -0.00761207]]
b2 = [[ 0.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
两层的神经网络测试已经完毕了,那么对于一个L层的神经网络而言呢?初始化会是什么样的?
假设X(输入数据)的维度为(12288,209):
W的维度
b的维度
激活值的计算
激活值的维度
第 1 层
第 2 层
第 L-1 层
(n[L−1],n[L−2])(n[L−1],n[L−2]) 第 L 层
(n[L],n[L−1])(n[L],n[L−1])
当然,矩阵的计算方法还是要说一下的:
W=⎡⎣⎢jmpknqlor⎤⎦⎥X=⎡⎣⎢adgbehcfi⎤⎦⎥b=⎡⎣⎢stu⎤⎦⎥(1)(1)W=[jklmnopqr]X=[abcdefghi]b=[stu]
如果要计算 WX+bWX+b 的话,计算方法是这样的:
WX+b=⎡⎣⎢(ja+kd+lg)+s(ma+nd+og)+t(pa+qd+rg)+u(jb+ke+lh)+s(mb+ne+oh)+t(pb+qe+rh)+u(jc+kf+li)+s(mc+nf+oi)+t(pc+qf+ri)+u⎤⎦⎥(2)(2)WX+b=[(ja+kd+lg)+s(jb+ke+lh)+s(jc+kf+li)+s(ma+nd+og)+t(mb+ne+oh)+t(mc+nf+oi)+t(pa+qd+rg)+u(pb+qe+rh)+u(pc+qf+ri)+u]
在实际中,也不需要你去做这么复杂的运算,我们来看一下它是怎样计算的吧:
def initialize_parameters_deep(layers_dims):
"""
此函数是为了初始化多层网络参数而使用的函数。
参数:
layers_dims - 包含我们网络中每个图层的节点数量的列表
返回:
parameters - 包含参数“W1”,“b1”,...,“WL”,“bL”的字典:
W1 - 权重矩阵,维度为(layers_dims [1],layers_dims [1-1])
bl - 偏向量,维度为(layers_dims [1],1)
"""
np.random.seed(3)
parameters = {}
L = len(layers_dims)
for l in range(1,L):
parameters["W" + str(l)] = np.random.randn(layers_dims[l], layers_dims[l - 1]) / np.sqrt(layers_dims[l - 1])
parameters["b" + str(l)] = np.zeros((layers_dims[l], 1))
#确保我要的数据的格式是正确的
assert(parameters["W" + str(l)].shape == (layers_dims[l], layers_dims[l-1]))
assert(parameters["b" + str(l)].shape == (layers_dims[l], 1))
return parameters
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
测试一下:
#测试initialize_parameters_deep
print("==============测试initialize_parameters_deep==============")
layers_dims = [5,4,3]
parameters = initialize_parameters_deep(layers_dims)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
测试结果:
==============测试initialize_parameters_deep==============
W1 = [[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]
[-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]
[-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]
[-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]
b1 = [[ 0.]
[ 0.]
[ 0.]
[ 0.]]
W2 = [[-0.01185047 -0.0020565 0.01486148 0.00236716]
[-0.01023785 -0.00712993 0.00625245 -0.00160513]
[-0.00768836 -0.00230031 0.00745056 0.01976111]]
b2 = [[ 0.]
[ 0.]
[ 0.]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们分别构建了两层和多层神经网络的初始化参数的函数,现在我们开始构建前向传播函数。
前向传播函数
前向传播有以下三个步骤
- LINEAR
- LINEAR - >ACTIVATION,其中激活函数将会使用ReLU或Sigmoid。
- [LINEAR - > RELU] ×(L-1) - > LINEAR - > SIGMOID(整个模型)
线性正向传播模块(向量化所有示例)使用公式(3)进行计算:
Z[l]=W[l]A[l−1]+b[l](3)(3)Z[l]=W[l]A[l−1]+b[l]
线性部分【LINEAR】
前向传播中,线性部分计算如下:
def linear_forward(A,W,b):
"""
实现前向传播的线性部分。
参数:
A - 来自上一层(或输入数据)的激活,维度为(上一层的节点数量,示例的数量)
W - 权重矩阵,numpy数组,维度为(当前图层的节点数量,前一图层的节点数量)
b - 偏向量,numpy向量,维度为(当前图层节点数量,1)
返回:
Z - 激活功能的输入,也称为预激活参数
cache - 一个包含“A”,“W”和“b”的字典,存储这些变量以有效地计算后向传递
"""
Z = np.dot(W,A) + b
assert(Z.shape == (W.shape[0],A.shape[1]))
cache = (A,W,b)
return Z,cache
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
测试一下线性部分:
#测试linear_forward
print("==============测试linear_forward==============")
A,W,b = testCases.linear_forward_test_case()
Z,linear_cache = linear_forward(A,W,b)
print("Z = " + str(Z))
- 1
- 2
- 3
- 4
- 5
测试结果:
==============测试linear_forward==============
Z = [[ 3.26295337 -1.23429987]]
- 1
- 2
我们前向传播的单层计算完成了一半啦!我们来开始构建后半部分,如果你不知道我在说啥,请往上翻到【开始之前】仔细看看吧~
线性激活部分【LINEAR - >ACTIVATION】
为了更方便,我们将把两个功能(线性和激活)分组为一个功能(LINEAR-> ACTIVATION)。 因此,我们将实现一个执行LINEAR前进步骤,然后执行ACTIVATION前进步骤的功能。我们来看看这激活函数的数学实现吧~
- Sigmoid: σ(Z)=σ(WA+b)=11+e−(WA+b)σ(Z)=σ(WA+b)=11+e−(WA+b)
我们为了实现LINEAR->ACTIVATION这个步骤, 使用的公式是:A[l]=g(Z[l])=g(W[l]A[l−1]+b[l])A[l]=g(Z[l])=g(W[l]A[l−1]+b[l]),其中,函数g会是sigmoid() 或者是 relu(),当然,sigmoid()只在输出层使用,现在我们正式构建前向线性激活部分。
def linear_activation_forward(A_prev,W,b,activation):
"""
实现LINEAR-> ACTIVATION 这一层的前向传播
参数:
A_prev - 来自上一层(或输入层)的激活,维度为(上一层的节点数量,示例数)
W - 权重矩阵,numpy数组,维度为(当前层的节点数量,前一层的大小)
b - 偏向量,numpy阵列,维度为(当前层的节点数量,1)
activation - 选择在此层中使用的激活函数名,字符串类型,【"sigmoid" | "relu"】
返回:
A - 激活函数的输出,也称为激活后的值
cache - 一个包含“linear_cache”和“activation_cache”的字典,我们需要存储它以有效地计算后向传递
"""
if activation == "sigmoid":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert(A.shape == (W.shape[0],A_prev.shape[1]))
cache = (linear_cache,activation_cache)
return A,cache
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
测试一下:
#测试linear_activation_forward
print("==============测试linear_activation_forward==============")
A_prev, W,b = testCases.linear_activation_forward_test_case()
A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "sigmoid")
print("sigmoid,A = " + str(A))
A, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = "relu")
print("ReLU,A = " + str(A))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
测试结果:
==============测试linear_activation_forward==============
sigmoid,A = [[ 0.96890023 0.11013289]]
ReLU,A = [[ 3.43896131 0. ]]
- 1
- 2
- 3
我们把两层模型需要的前向传播函数做完了,那多层网络模型的前向传播是怎样的呢?我们调用上面的那两个函数来实现它,为了在实现L层神经网络时更加方便,我们需要一个函数来复制前一个函数(带有RELU的linear_activation_forward)L-1次,然后用一个带有SIGMOID的linear_activation_forward跟踪它,我们来看一下它的结构是怎样的:

Figure 2 :
[LINEAR -> RELU] ×× (L-1) -> LINEAR -> SIGMOID model
在下面的代码中,AL表示A[L]=σ(Z[L])=σ(W[L]A[L−1]+b[L])A[L]=σ(Z[L])=σ(W[L]A[L−1]+b[L]).)
多层模型的前向传播计算模型代码如下:
def L_model_forward(X,parameters):
"""
实现[LINEAR-> RELU] *(L-1) - > LINEAR-> SIGMOID计算前向传播,也就是多层网络的前向传播,为后面每一层都执行LINEAR和ACTIVATION
参数:
X - 数据,numpy数组,维度为(输入节点数量,示例数)
parameters - initialize_parameters_deep()的输出
返回:
AL - 最后的激活值
caches - 包含以下内容的缓存列表:
linear_relu_forward()的每个cache(有L-1个,索引为从0到L-2)
linear_sigmoid_forward()的cache(只有一个,索引为L-1)
"""
caches = []
A = X
L = len(parameters) // 2
for l in range(1,L):
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)], parameters['b' + str(l)], "relu")
caches.append(cache)
AL, cache = linear_activation_forward(A, parameters['W' + str(L)], parameters['b' + str(L)], "sigmoid")
caches.append(cache)
assert(AL.shape == (1,X.shape[1]))
return AL,caches
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
测试一下:
#测试L_model_forward
print("==============测试L_model_forward==============")
X,parameters = testCases.L_model_forward_test_case()
AL,caches = L_model_forward(X,parameters)
print("AL = " + str(AL))
print("caches 的长度为 = " + str(len(caches)))
- 1
- 2
- 3
- 4
- 5
- 6
测试结果:
==============测试L_model_forward==============
AL = [[ 0.17007265 0.2524272 ]]
caches 的长度为 = 2
- 1
- 2
- 3
计算成本
我们已经把这两个模型的前向传播部分完成了,我们需要计算成本(误差),以确定它到底有没有在学习,成本的计算公式如下:
−1m∑i=1m(y(i)log(a[L](i))+(1−y(i))log(1−a[L](i)))(4)(4)−1m∑i=1m(y(i)log(a[L](i))+(1−y(i))log(1−a[L](i)))
def compute_cost(AL,Y):
"""
实施等式(4)定义的成本函数。
参数:
AL - 与标签预测相对应的概率向量,维度为(1,示例数量)
Y - 标签向量(例如:如果不是猫,则为0,如果是猫则为1),维度为(1,数量)
返回:
cost - 交叉熵成本
"""
m = Y.shape[1]
cost = -np.sum(np.multiply(np.log(AL),Y) + np.multiply(np.log(1 - AL), 1 - Y)) / m
cost = np.squeeze(cost)
assert(cost.shape == ())
return cost
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
测试一下:
#测试compute_cost
print("==============测试compute_cost==============")
Y,AL = testCases.compute_cost_test_case()
print("cost = " + str(compute_cost(AL, Y)))
- 1
- 2
- 3
- 4
测试结果:
==============测试compute_cost==============
cost = 0.414931599615
- 1
- 2
我们已经把误差值计算出来了,现在开始进行反向传播
反向传播
反向传播用于计算相对于参数的损失函数的梯度,我们来看看向前和向后传播的流程图:
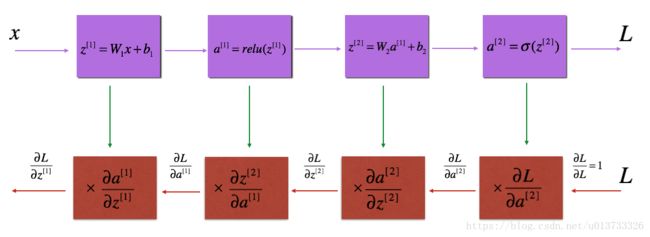
流程图有了,我们再来看一看对于线性的部分的公式:

我们需要使用dZ[l]dZ[l]
<
你可能感兴趣的:(【吴恩达课后编程作业】01 - 神经网络和深度学习 - 第四周 - PA1&2 - 一步步搭建多层神经网络以及应用)