SSE指令集优化学习:双线性插值
from:http://www.cnblogs.com/wangguchangqing/p/5445652.html
对SSE的学习总算迈出了第一步,用2天时间对双线性插值的代码进行了优化,现将实现的过程梳理以下,算是对这段学习的一个总结。
1. 什么是SSE
说到SSE,首先要弄清楚的一个概念是SIMD(单指令多数据流,Single Instruction Multiple Data),是一种数据并行技术,能够在一条指令中同时对多个数据执行运算操作,增加处理器的数据吞吐量。SIMD特别的适用于多媒体应用等数据密集型运算。
1.1 历史
1996年Intel首先推出了支持MMX的Pentium处理器,极大地提高了CPU处理多媒体数据的能力,被广泛地应用于语音合成、语音识别、音频视频编解码、图像处理和串流媒体等领域。但是MMX只支持整数运算,浮点数运算仍然要使用传统的x87协处理器指令。由于MMX与x87的寄存器相互重叠,在MMX代码中插入x87指令时必须先执行EMMS指令清除MMX状态,频繁地切换状态将严重影响性能。这限制了MMX指令在需要大量浮点运算的程序,如三维几何变换、裁剪和投影中的应用。
另一方面,由于x87古怪的堆栈式缓存器结构,使得硬件上将其流水线化和软件上合理调度指令都很困难,这成为提高x86架构浮点性能的一个瓶颈。为了解决以上这两个问题,AMD公司于1998年推出了包含21条指令的3DNow!指令集,并在其K6-2处理器中实现。K6-2是 第一个能执行浮点SIMD指令的x86处理器,也是第一个支持水平浮点寄存器模型的x86处理器。借助3DNow!,K6-2实现了x86处理器上最快的浮点单元,在每个时钟周期内最多可得到4个单精度浮点数结果,是传统x87协处理器的4倍。许多游戏厂商为3DNow!优化了程序,微软的DirectX 7也为3DNow!做了优化,AMD处理器的游戏性能第一次超过Intel,这大大提升了AMD在消费者心目中的地位。K6-2和随后的K6-III成为市场上的热门货。
1999年,随着Athlon处理器的推出,AMD为3DNow!增加了5条新的指令,用于增强其在DSP方面的性能,它们被称为“扩展3DNow!”(Extended 3DNow!)。
为了对抗3DNow!,Intel公司于1999年推出了SSE指令集。SSE几乎能提供3DNow!的所有功能,而且能在一条指令中处理两倍多的单精度浮点数;同时,SSE完全支持IEEE 754,在处理单精度浮点数时可以完全代替x87。这迅速瓦解了3DNow!的优势。
1999年后,随着主流操作系统和软件都开始支持SSE并为SSE优化,AMD在其2000年发布的代号为“Thunderbird”的Athlon处理器中添加了对SSE的完全支持(“经典”的Athlon或K7只支持SSE中与MMX有关的部分,AMD称之为“扩展MMX”即Extended MMX)。随后,AMD致力于AMD64架构的开发;在SIMD指令集方面,AMD跟随Intel,为自己的处理器添加SSE2和SSE3支持,而不再改进3DNow!。
2010年八月,AMD宣布将在新一代处理器中取消除了两条数据预取指令之外3DNow!指令的支持,并鼓励开发者将3DNow!代码重新用SSE实现。
1.2 MMX和SSE
MMX 是Intel在Pentium MMX中引入的指令集。其缺点是占用浮点数寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名)以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。后来Intel在此基础上发展出SSE指令集;AMD在此基础上发展出3D Now指令集。
SSE(Streaming SIMD Extensions)是Intel在3D Now!发布一年之后,在PIII中引入的指令集,是MMX的超集。AMD后来在Athlon XP中加入了对这个指令集的支持。这个指令集增加了对8个128位寄存器XMM0-XMM7的支持,每个寄存器可以存储4个单精度浮点数。使用这些寄存器的程序必须使用FXSAVE和FXRSTR指令来保持和恢复状态。但是在PIII对SSE的实现中,浮点数寄存器又一次被新的指令集占用了,但是这一次切换运算模式不是必要的了,只是SSE和浮点数指令不能同时进入CPU的处理线而已。
SSE2是Intel在P4的最初版本中引入的,但是AMD后来在Opteron 和Athlon 64中也加入了对它的支持。这个指令集添加了对64位双精度浮点数的支持,以及对整型数据的支持,也就是说这个指令集中所有的MMX指令都是多余的了,同时也避免了占用浮点数寄存器。这个指令集还增加了对CPU的缓存的控制指令。AMD对它的扩展增加了8个XMM寄存器,但是需要切换到64位模式(AMD64)才可以使用这些寄存器。Intel后来在其EM64T架构中也增加了对AMD64的支持。
SSE3是Intel在P4的Prescott版中引入的指令集,AMD在Athlon 64的第五个版本中也添加了对它的支持。这个指令集扩展的指令包含寄存器的局部位之间的运算,例如高位和低位之间的加减运算;浮点数到整数的转换,以及对超线程技术的支持。
2 双线性差值的优化
上面的多半是粘贴的,是前期学习SSE的资料搜集,算是对SSE的由来有一个大致的了解。下面介绍对双线性插值的优化的学习过程。
2.1 双线性插值
在图像变换时,变换后图像的像素映射到源图像上的坐标有可能是一个浮点坐标,插值算法就是要计算出浮点坐标像素近似值。那么要如何计算浮点坐标的近似值呢。一个浮点坐标必定会被四个整数坐标所包围,将这个四个整数坐标的像素值按照一定的比例混合就可以求出浮点坐标的像素值。混合比例为距离浮点坐标的距离,这就是双线性插值的基本思想。关于双线性插值的更多信息可以参见WIKI和 本人博文
要优化的双线性插值的C++实现
//计算缩放后的图像大小
dstWidth = static_cast<int>(width * fx);
dstHeight = static_cast<int>(height * fy);
depth /= 8;
int dstSize = dstWidth * dstHeight * depth;
dst = new byte[dstSize];
memset(dst, 255, dstSize);
byte* dstPixel = nullptr;
double x = 0.0f; //缩放后图像在映射到原图像的横坐标
double y = 0.0f; //映射到原图像的横坐标
for (int j = 0; j < dstHeight; j++)
{
y = j / fy;
for (int i = 0; i < dstWidth; i++)
{
x = i / fx;
dstPixel = dst + (j * dstWidth + i) * depth;
//计算距离当前映射点(x,y)最近的4个点
int x1, y1, x2, y2;
x1 = static_cast<int>(x);
x2 = x1 + 1;
y1 = static_cast<int>(y);
y2 = y1 + 1;
double u = x - x1; //映射点和最左边横坐标的差值
double v = y - y1; //映射点和最下边纵坐标的差值
byte cltr1, cltr2, cltr3, cltr4;
//分别计算各个通道的分量
for (int k = 0; k < depth; k++)
{
cltr1 = src[(y1 * width + x1) * depth + k]; // x1,y1
cltr2 = src[(y1 * width + x2) * depth + k]; // x2,y1
cltr3 = src[(y2 * width + x1) * depth + k]; // x1,y2
cltr4 = src[(y2 * width + x2) * depth + k]; // x2,y2
double f1, f2;
f1 = u * cltr1 + (1-u) * cltr2;
f2 = u * cltr3 + (1-u) * cltr4;
dstPixel[k] = static_cast(v * f1 + (1-v) * f2);
}
}
} 优化的思路,使用128位的xmm寄存器,可以同时对4个32位的数据进行运算,选择同时对一个像素的所有通道进行处理(3通道和4通道)。优化后的运行速度,因为主要是用来学习SSE指令的,没有很做很严谨的对比,在debug下大致是3倍速(实验用的图像是24位3通道),在release下优化和优化的速度没有明显的提升,编译器的优化就是牛哇...。
下面就开始介绍用SSE实现双线性插值的过程,主要分为以下几个步骤:
- 数据的移动
- 数据的组织:pack,unpck,shuffle
- 运算
2.2 数据的移动
使用SSE的第一步就是需要将要处理的数据从内存复制到xmm寄存器中。SSE的mov指令可谓无花八门,可以mov不同长度的数据到xmm寄存器,另外有的mov指令需要内存16位对齐,有的则不需要。SSEmov指令可以将数据在xmm寄存器和内存之间进行移动,也可以用于xmm寄存器之间。下面列举几个常用mov指令:
- movd 移动双字到xmm寄存器
- movq 移动四字到xmm寄存器
- movapd / movaps 移动对齐的pack的双精度浮点数/单精度浮点数
- movupd / movups 移动未对齐的pack的双精度浮点数/单精度浮点数
- movdqa 移动对齐的双四字
-
movdqu 移动未对齐的双四字
SSE的数据移动指令很多,这里只列举一些,具体的可以参考Intel开发者手册。
在双线性插值中,由于一个浮点坐标要使用其附近的4个像素近似得到,利用SSE指令同时计算这个4个像素的坐标,计算公式如下:
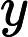


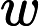
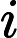
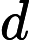




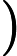
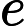




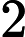
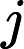 (yi∗width+xi)∗depth,i=1,2j=1,2
(yi∗width+xi)∗depth,i=1,2j=1,2
首先将这需要用到的数据移动到xmm寄存器中movd xm0,width movd xmm1,y1 movd xmm2,y2width和y1,y2都是32位的整型,所以使用
movd将其移动到xmm中。
2.3 数据的组织
数据的组织可以说是使用SSE指令的第一个难点,因为128位寄存器可以同时对4个32位数据进行运算,就需要按照该一定的顺序将数据放在寄存器中。SSE中提供了两种指令来调整数据在xmm寄存器中的顺序
- unpck 交叉组合。
- shuffle 乱序
2.3.1 unpck
unpck是将源操作数和目的操作中字(双字,四字具体的交叉单位依赖于不同的指令)重新组合。
unpcklps32位单精度浮点数低位交叉 (unpckhps 32位浮点数高位交叉)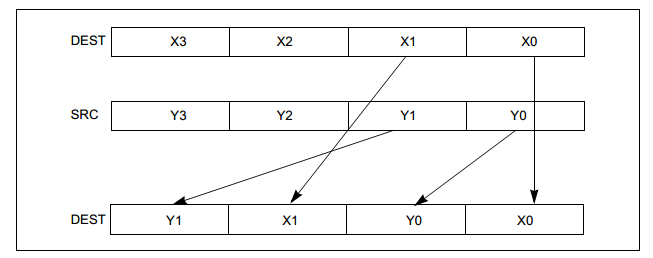
unpckhpd 64位浮点数高位交叉 (unpcklpd 64位浮点数低位交叉)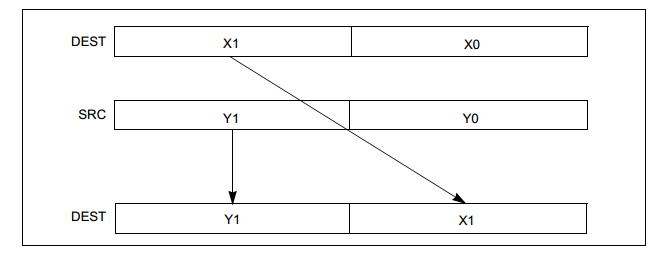
低位的unpck是按照一定的长度(根据指令的不同,一般有字/双字/四字,字长为16)取两操作数的低位数据进行重组,重组后的数据的高位是源操作数的低位,低位是目的操作数的低位。重组的结果保存在目的操作数中。
除了上述的unpck指令外,常用的交叉指令还有
- punpcklbw 交叉组合低位4字中的字节
- punpcklwd 交叉组合低位双字中字
- punpckldq 交叉组合低位四字中的双字
- punpcklqdq 交叉组合低位四字
利用上面提到的交叉指令,可以将byte变成16位的整型,16位的整型变成32为整型,32位整型变成64位整型,后面有用到再详述。
2.3.2 shuffle
shuffle 指令功能更赞,它能够将xmm寄存器中的位调整为我们需要的顺序。这里以pshufd为例进行介绍。pshufd xmm1,xmm2,imm8pshufd有三个操作数,从左往右,第一个操作数是目的操作数保存结果,第二个操作数是源操作数,第三个操作数是一个8位立即数,指定以怎样的顺序将源操作数中数据保存到目的操作数。
imm8中每2位选择源操作数的一个双字(共4个),00选择第一个,01选择第二个,10选择第三个,11选择第四个。利用imm8位模式选择好源操作数的双字后,其每2位的位段决定着这些双字如何在目的操作数中排列。[0-1]位选择的双字放在目的操作数的[0-31],[2-3]选择的放在[32-63],[4-5]选择的放在[64,95],[6-7]选择的放在[96-127]中。
具体如下图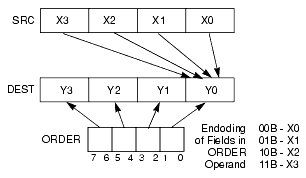
例如:
_MM_ALIGN16 int a[4] = {1,2,3,4}; //要变成2,4,3,1的顺序
_asm
{
movdqa xmm0,[a];
pshufd xmm0,xmm0,0x2D; // 0010 1101
} 0x2d 就是0010 1101
将从源操作数选择的双字 从左到右,由高到底依次存放在目的操作数
00 选择 1,放在[96-127]
10 选择 3, 放在[64-95]
11 选择 4, 放在[32-63]
01 选择 2, 放在[0-31]
2.3.3 同时计算 y1 * width 和 y2 * width
上面说128位的寄存器可以同时进行4个32位数据的计算,这里要将乘法排除在外,因为32位 32位需要64位空间才能结果不溢出。当然在保证结果不溢出的前提下,也可以使用32位存放相乘的结果。(一定要在保证结果不溢出的前提下,才能如此处理。我在写这段程序时,开始用16位保存的相乘结果,最后产生了溢出,调试了好久才找到错误所在。)
要同时运算y1 width 和 y2 * width,就需要将一个寄存器中存放width ,width,一个寄存器存放y1,y2
punpckldq xmm0, xmm0; // xmm0 => width,width 低64位
movd xmm1, y1;
movd xmm2, y2;
punpckldq xmm1, xmm2; // xmm1 =>y1,y2 低64位 执行上面指令后,还是不能进行计算。这是因为 32位的乘法产生64位的结果,也就是
src[0-31] * dst[0-31] => src[0-64]
src[64-95] * dst[64-95] => src[64-127]
所以要调整顺序 xmm0中数据的顺序为 width 0 width 0 ,xmm1中顺序为 y1 0 y2 0 这就要用到上面提到的shuffle指令
pshufd xmm1, xmm1, 0xd8; // 0x1101 1000
pshufd xmm0, xmm0, 0xd8;
pmuludq xmm0, xmm1; pmuludq 是乘法指令。xmm0得到的是两个64位的数据,这里是做图像缩放用32位存放结果也就足够了。(因为 这里计算的是图像中某个像素的通道的索引,即使是4k * 4k * 4 = 0x400 0000,32位足够保存了)。
得到y1 * width 和 y2 * width后,进行交叉后可以4个一起同时和x1,x2相加
unpcklpd xmm0, xmm0; // xmm0 y1*width y2*width y1*width y2*width
movd xmm1, x1;
punpckldq xmm1, xmm1; // xmm1 => x1,x1
movd xmm2, x2;
punpckldq xmm2, xmm2; // xmm2 => x2,x2
unpcklpd xmm1, xmm2; // xmm1 => x1,x1,x2,x2
paddd xmm0, xmm1; // xmm0 => y1*width + x1,y2*width + x1,y1*width+x2,y2*width+x2 下面需要计算 ![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]() (y∗width+x)∗depth ,128位寄存器只能同时计算2个32位的乘法,所以讲xmm0中的数据拆分放在两个xmm寄存器中
(y∗width+x)∗depth ,128位寄存器只能同时计算2个32位的乘法,所以讲xmm0中的数据拆分放在两个xmm寄存器中
pshufd xmm1, xmm0, 0x50; // xmm1 => (x1,y1) (x1,y2)
pshufd xmm2, xmm0, 0xfa; // xmm2 => (x2,y1) (x2,y2)然后就和上面的类似过程,将得到的64位结果只取低32位,然后在一起放在同一个xmm寄存器中
movd xmm3, depth;
punpckldq xmm3, xmm3;
unpcklpd xmm3, xmm3;
pmuludq xmm1, xmm3;
pmuludq xmm2, xmm3;
pshufd xmm1, xmm1, 0xd8;
pshufd xmm2, xmm2, 0xd8;
punpcklqdq xmm1, xmm2;到这里 xmm1中就存放着要求的浮点坐标周围的4个像素的位置,依次为(x1,y1) (x1,y2) (x2,y1) (x2,y2)。将这四个值放在数组中,在后面取像素值时会用到
//像素的地址偏移量
__declspec(align(16)) int bitOffset[] = { 0,0,0,0 };
movdqa[bitOffset], xmm1;//(x1,y1) (x1,y2) (x2,y1) (x2,y2)2.3.4 位扩展
在对像素的通道进行处理时,读取的数据是8位,而通常在处理时需要运算是32位的或者64位的(本文中和通道数据做运算的是32位浮点数),这就需要将8位的通道数据进行扩展。
在上面也提到可以利用punpcklbw punpcklwd punpckldq对8位字节进行扩展。下面的SSE指令将8位的通道数据转换为32位的整型
// 取出像素依次存放在xmm0,xmm1,xmm2,xmm3
lea eax, bitOffset; // 取出数组地址
mov edx, [eax];
mov ecx, src;
movd xmm0, [ecx + edx]; //三通道像素,读取了32位,只需要处理24位
//将xxm0中的低位4个字节扩展为32位整数(只处理低3个32位整数)
psllw xmm1, 16; //将xxm1置为0
punpcklbw xmm0, xmm1;
punpcklwd xmm0, xmm1; // 扩展为32位整数 punpcklbw 交叉组合低位四字中的字节,如果源操作数为0,则可以将低位的8位字节扩展为16位整型。psllw 是以字为单位(16位)的逻辑左移指令,立即数16是左移的位数,由于是以字为单位左移16位,所以该指令可以将xmm1清0。
'punpcklwd' 交叉组合低位四字中的字,如果源操作数为0,则可以将低位的16位整型扩展为32位整型。
2.3.5 数据类型转换
数据类型的转换主要在双精度64位浮点数和单精度32位浮点,64位浮点数和32位整型以及32位浮点数和32位整型之间,具体的转换指令如下图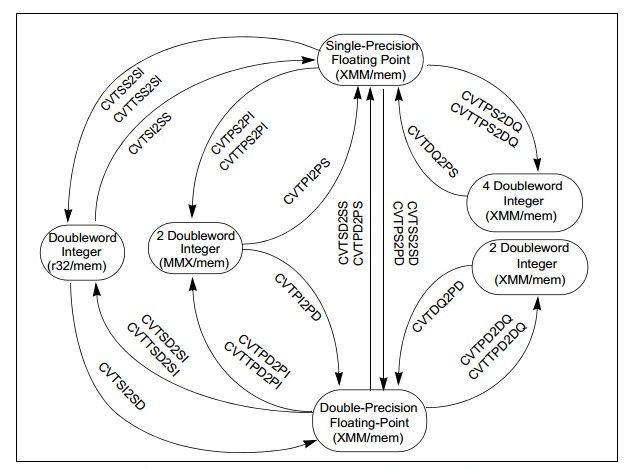
指令前缀为CVTT的表示带截断的类型转换。
在上面,已将三通道的24为像素数据转换为3个32位的整型数据存放在xmm寄存器中,但是下面要做的运算是浮点型的,还需要将32位整型转换为32位的浮点数
cvtdq2ps xmm0, xmm0; //32位整型转换为单精度浮点数 #### 2.4 运算
SSE指令集能够同时在多个数据上执行同一个操作,上面做了那么多操作,就是要将参与运算的数据以需要的格式存放到xmm寄存器中,然后对这些数据同时执行相同的操作。SSE指令集对下面三类常用的运算都有提供
- 算术运算
为了适应各种样的运算环境,SSE也提供了多种样的算术运算。pmuludq无符号双字乘法,源操作数和目的操作数的第一个和第三个32位无符号整型参与运算,结果为2个64位整型,存放在目的操作数。这条指令是将乘法的结果依次给出了,但是只能同时进行2个32位的运算(结果为64位)。而有可能我们只关系乘法结果的某一部分(例如高位,判断两个有符号数的符号是否相同)。pmullwpack有符号字乘法取低位,16位的乘法运算,将32位结果的低16位保存到目的操作数。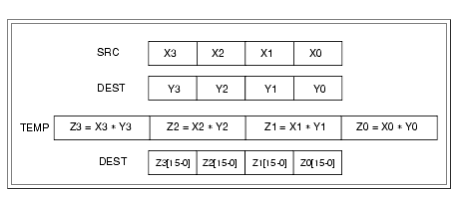
pmulhw pack有符号字乘法取高位,16位的乘法运算,将32位结果的高16位保存到目的操作数。
- 逻辑
- 位移
- 比较
具体的指令这里就不再赘述了,可以参考Intel开发者手册。
3 小结
初次的学习总结就到这里了。使用SSE指令集可以总结为三步:
- 将数据从内存移动到xmm寄存器,这里注意指令是否要求16或者32位对齐。
- 利用各种unpck和shuffle指令,对xmm寄存器中的数据进行操作,将其组织成后面运算需要的格式。
- 对组织好的数据执行运算,注意数据的溢出以及计算的数据类型(浮点、整型、有符号还是无符号),数据的长度(字,双字,四字,双四字)以及指令操作的是高位还是低位等。总之运算时要特别小心,不像在高级语言中那么的省心。
SSE指令集提供了很丰富的操作,但是Intel的手册查阅却不是很方便....。另外,直接在C/C++中内嵌汇编代码,感觉也很拖沓,下一步准备学习下编译器提供的Intrinsics。
大多数的函数是在库中,Intrinsic Function却内嵌在编译器中(built in to the compiler)。
1. Intrinsic Function
Intrinsic Function作为内联函数,直接在调用的地方插入代码,即避免了函数调用的额外开销,又能够使用比较高效的机器指令对该函数进行优化。优化器(Optimizer)内置的一些Intrinsic Function行为信息,可以对Intrinsic进行一些不适用于内联汇编的优化,所以通常来说Intrinsic Function要比等效的内联汇编(inline assembly)代码快。优化器能够根据不同的上下文环境对Intrinsic Function进行调整,例如:以不同的指令展开Intrinsic Function,将buffer存放在合适的寄存器等。
使用 Intrinsic Function对代码的移植性会有一定的影响,这是由于有些Intrinsic Function只适用于Visual C++,在其他编译器上是不适用的;更有些Intrinsic Function面向的是特定的CPU架构,不是全平台通用的。上面提到的这些因素对使用Intrinsic Function代码的移植性有一些不好的影响,但是和内联汇编相比,移植含有Intrinsic Function的代码无疑是方便了很多。另外,64位平台已经不再支持内联汇编。
2. SSE Intrinsic
VS和GCC都支持SSE指令的Intrinsic,SSE有多个不同的版本,其对应的Intrinsic也包含在不同的头文件中,如果确定只使用某个版本的SSE指令则只包含相应的头文件即可。
引用自:http://www.cnblogs.com/zyl910/archive/2012/02/28/vs_intrin_table.html
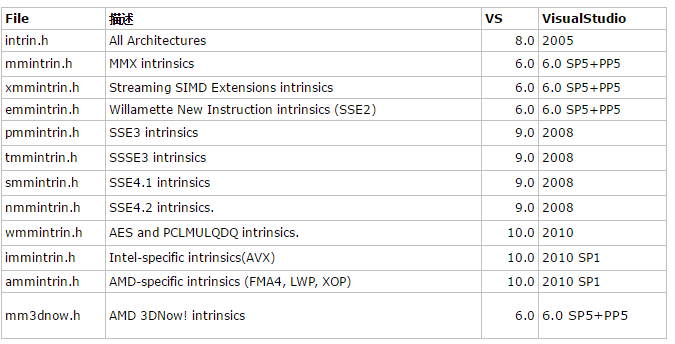
例如,要使用SSE3,则
#include 如果不关心使用那个版本的SSE指令,则可以包含所有
#include 2.1 数据类型
Intrinsic使用的数据类型和其寄存器是想对应,有
- 64位 MMX指令集使用
- 128位 SSE指令集使用
- 256位 AVX指令集使用
甚至AVX-512指令集有512位的寄存器,那么相对应Intrinsic的数据也就有512位。
具体的数据类型及其说明如下:
- **__m64** 64位对应的数据类型,该类型仅能供MMX指令集使用。由于MMX指令集也能使用SSE指令集的128位寄存器,故该数据类型使用的情况较少。
- **__m128 / __m128i / __m128d** 这三种数据类型都是128位的数据类型。由于SSE指令集即能操作整型,又能操作浮点型(单精度和双精度),这三种数据类型根据所带后缀的不同代表不同类型的操作数。__m128是单精度浮点数,__m128i是整型,__m128d是双精度浮点数。
256和512的数据类型和128位的类似,只是存放的个数不同,这里不再赘述。
知道了各种数据类型的长度以及其代码的意义,那么它的表现形式到底是怎么样的呢?看下图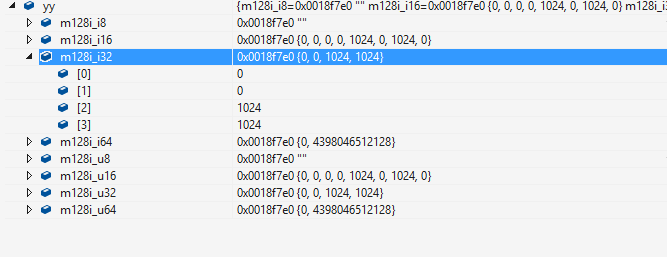
__m128i yy; yy是__m128i型,从上图可以看出__m128i是一个联合体(union),根据不同成员包含不同的数据类型。看其具体的成员包含了8位、16位、32位和64位的有符号/无符号整数(这里__m128i是整型,故只有整型的成员,浮点数的使用__m128)。而每个成员都是一个数组,数组中填充着相应的数据,并且根据数据长度的不同数组的长度也不同(数组长度 = 128 / 每个数据的长度(位))。在使用的时候一定要特别的注意要操作数据的类型,也就是数据的长度,例如上图同一个变量yy当作4个32位有符号整型使用时其数据是:0,0,1024,1024;但是当做64位有符号整型时其数据为:0,4398046512128,大大的不同。
在MSVC下可以使用yy.m128i_i32[0]取出第一个32位整型数据,原生的Intrinsic函数是没有提供该功能的,这是在MSVC的扩展,比较像Microsoft的风格,使用及其的方便但是效率很差,所以这种方法在GCC/Clang下面是不可用的。在MSVC下面可以根据需要使用不使用这种抽取数据的方法,但是这种功能在调试代码时是非常方便的,如上图可以很容易的看出128位的数据在不同数据类型下其值的不同。
2.2 Intrinsic 函数的命名
Intrinsic函数的命名也是有一定的规律的,一个Intrinsic通常由3部分构成,这个三个部分的具体含义如下:
- 第一部分为前缀_mm,表示是SSE指令集对应的Intrinsic函数。_mm256或_mm512是AVX,AVX-512指令集的Intrinsic函数前缀,这里只讨论SSE故略去不作说明。
- 第二部分为对应的指令的操作,如_add,_mul,_load等,有些操作可能会有修饰符,如loadu将未16位对齐的操作数加载到寄存器中。
- 第三部分为操作的对象名及数据类型,_ps packed操作所有的单精度浮点数;_pd packed操作所有的双精度浮点数;_pixx(xx为长度,可以是8,16,32,64)packed操作所有的xx位有符号整数,使用的寄存器长度为64位;_epixx(xx为长度)packed操作所有的xx位的有符号整数,使用的寄存器长度为128位;_epuxx packed操作所有的xx位的无符号整数;_ss操作第一个单精度浮点数。....
将这三部分组合到以其就是一个完整的Intrinsic函数,如_mm_mul_epi32 对参数中所有的32位有符号整数进行乘法运算。
SSE指令集对分支处理能力非常的差,而且从128位的数据中提取某些元素数据的代价又非常的大,因此不适合有复杂逻辑的运算。
3. Intrinsic版双线性插值
在上一篇文章SSE指令集优化学习:双线性插值 使用SSE汇编指令对双线性插值算法进行了优化,这里将其改成为Intrinsic版的。
3.1 计算 (y * width + x) * depth
目的像素需要其映射到源像素周围最近的4个像素插值得到,这里同时计算源像素的最近的4个像素值的偏移量。
__m128i wwidth = _mm_set_epi32(0, width, 0, width);
__m128i yy = _mm_set_epi32(0, y2, 0, y1);
yy = _mm_mul_epi32(yy, wwidth); //y1 * width 0 y2 *width 0
yy = _mm_shuffle_epi32(yy, 0xd8); // y1 * width y2 * width 0 0
yy = _mm_unpacklo_epi32(yy, yy); // y1 * width y2 * width y1 * width y2 * width
yy = _mm_shuffle_epi32(yy, _MM_SHUFFLE(3, 1, 2, 0));
__m128i xx = _mm_set_epi32(x2, x2, x1, x1);
xx = _mm_add_epi32(xx, yy); // (x1,y1) (x1,y2) (x2,y1) (x2,y2)
__m128i x1x1 = _mm_shuffle_epi32(xx, 0x50); // (x1,y1) (x1,y2)
__m128i x2x2 = _mm_shuffle_epi32(xx, 0xfa); // (x2,y1) (x2,y2) - 使用set函数将需要的数据填充到__m128Intel中
- mul函数进行乘法运算,两个32位的整型相乘的结果是一个64位整型。
- 由于计算的是像素的偏移量,使用32位整型也就足够了,使用shffule对__m128i中的数据进行重新排列,使用unpack函数再重新组合,将数据组合为需要的结构。
-
_MM_SHUFFLE是一个宏,能够方便的生成shuffle中所需要的立即数。例如_mm_shuffle_epi32(yy,_MM_SHUFFLE(3,1,2,0);将yy中存放的第2和第3个32位整数交换顺序。
3.2 数据类型的转换
SSE汇编指令和其Intrinsic函数之间基本存在这一一对应的关系,有了汇编的实现再改为Intrinsic是挺简单的,再在这罗列代码也乜嘢什么意义了。这里就记录下使用的过程中遇到的最大的问题:数据类型之间的转换。
做图像处理,由于像素通道值是8位的无符号整数,而与其运算的往往又是浮点数,这就需要将8位无符号整数转换为浮点数;运算完毕后,得到的结果又要写回图像通道,就要是8位无符号整数,还要涉及到超出8位的截断。开始不注意时吃了大亏....
类型转换主要以下几种:
- 浮点数和整数的转换及32位浮点数和64位浮点数之间的转换。 这种转换简单直接,只需要调用相应的函数指令即可。
- 有符号整数的高位扩展将8位、16位、32位有符号整数扩展为16位、32位、64位。
- 有符号整数的截断 将16位、32位、64位有符号压缩
- 无符号整数到有符号整数的扩展
在Intrinsic函数中 上述类型转换的格式
- _mm_cvtepixx_epixx (xx是位数8/16/32/64)这是有符号整数之间的转换
- _mm_cvtepixx_ps / _mm_cvtepixx_pd 整数到单精度/双精度浮点数之间的转换
- _mm_cvtepuxx_epixx 无符号整数向有符号整数的扩展,采用高位0扩展的方式,这些函数是对无符号高位0扩展变成相应位数的有符号整数。没有32位无符号整数转换为16位有符号整数这样的操作。
- _mm_cvtepuxx_ps / _mm_cvtepuxx_pd 无符号整数转换为单精度/双精度浮点数。
上面的数据转换还少了一种,整数的饱和转换。什么是饱和转换呢,超过的最大值的以最大值来计算,例如8位无符号整数最大值为255,则转换为8位无符号时超过255的值视为255。
整数的饱和转换有两种:
-
有符号之间的 SSE的Intrinsic函数提供了两种
__m128i _mm_packs_epi32(__m128i a, __m128i b) __m128i _mm_packs_epi16(__m128i a , __m128i b) -
有符号到无符号之间的
__m128i _mm_packus_epi32(__m128i a, __m128i b) __m128i _mm_packus_epi16(__m128i a , __m128i b)用于将16/32位的有符号整数饱和转换为8/16位无符号整数
4. SSE汇编指令和Intrinsic函数的对比
这里只是做了一个粗略的对比,毕竟还只是个初学者。先说结果吧,在Debug下使用纯汇编的SSE代码会快不少,应该是由于没有编译器的优化,汇编代码的效率还是有很大的优势的。但是在Release下面,前面也有提到过优化器内置了Intrinsic函数的行为信息,能够对Intrinsic函数提供很强大的优化,两者没有什么差别。PS:应该是由于选用数据的问题 ,普通的C++代码,SSE汇编代码以及Intrinsic函数三者在Release下的速度相差无几,编译器本身的优化功能是很强大的。
4.1 Intrinsic 函数进行多次内存读写操作
在对比时发现使用Intrinsic函数另一个问题,就是数据的存取。使用SSE汇编时,可以将中间的计算结果保存到xmm寄存器中,在使用的时候直接取出即可。Intrinsic函数不能操作xmm寄存器,也就不能如此操作,它需要将每次的计算结果写回内存中,使用的时候再次读取到xmm寄存器中。
yy = _mm_mul_epi32(yy, wwidth);上述代码是进行32位有符号整数乘法运算,计算的结果保存在yy中,反汇编后其对应的汇编代码:
000B0428 movaps xmm0,xmmword ptr [ebp-1B0h]
000B042F pmuldq xmm0,xmmword ptr [ebp-190h]
000B0438 movaps xmmword ptr [ebp-7A0h],xmm0
000B043F movaps xmm0,xmmword ptr [ebp-7A0h]
000B0446 movaps xmmword ptr [ebp-1B0h],xmm0 上述汇编代码中有多次的movaps操作。而上述操作在使用汇编时只需一条指令
pmuludq xmm0, xmm1;在使用Intrinsic函数时,每一个函数至少要进行一次内存的读取,将操作数从内存读入到xmm寄存器;一次内存的写操作,将计算结果从xmm寄存器写回内存,也就是保存到变量中去。由此可见,在只有很简单的计算中(例如:同时进行4个32位浮点数的乘法运算)和使用SSE汇编指令不会有很大的差别,但是如果逻辑稍微复杂些或者调用的Intrinsic函数较多,就会有很多的内存读写操作,这在效率上还是有一部分损失的。
4.2 简单运算的Intrinsic和SSE指令的对比
一个比较极端的例子,未经过优化的C++代码如下:
_MM_ALIGN16 float a[] = { 1.0f,2.0f,3.0f,4.0f };
_MM_ALIGN16 float b[] = { 5.0f,6.0f,7.0f,8.0f };
const int count = 1000000000;
float c[4] = { 0,0,0,0 };
cout << "Normal Time(ms):";
double tStart = static_cast<double>(clock());
for (int i = 0; i < count; i++)
for (int j = 0; j < 4; j++)
c[j] = a[j] + b[j];
double tEnd = static_cast<double>(clock());对两个有4个单精度浮点数的数组做多次加法运算,并且这种加法是重复进行,进行1次和进行1000次的结果是相同的。使用SSE汇编指令的代码如下:
for(int i = 0; i < count; i ++)
_asm
{
movaps xmm0, [a];
movaps xmm1, [b];
addps xmm0, xmm1;
}使用Intrinsic函数的代码:
__m128 a1, b2;
__m128 c1;
for (int i = 0; i < count; i++)
{
a1 = _mm_load_ps(a);
b2 = _mm_load_ps(b);
c1 = _mm_add_ps(a1, b2);
} 在Debug下的运行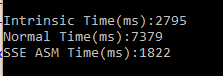
这个结果应该在意料之中的,SSE汇编指令 < Intrinsic函数 < C++。SSE汇编指令比Intrinsic函数快了近1/3,下面是Intrinsic函数的反汇编代码
a1 = _mm_load_ps(a);
00FB2570 movaps xmm0,xmmword ptr [a]
00FB2574 movaps xmmword ptr [ebp-220h],xmm0
00FB257B movaps xmm0,xmmword ptr [ebp-220h]
00FB2582 movaps xmmword ptr [a1],xmm0
b2 = _mm_load_ps(b);
00FB2586 movaps xmm0,xmmword ptr [b]
00FB258A movaps xmmword ptr [ebp-240h],xmm0
00FB2591 movaps xmm0,xmmword ptr [ebp-240h]
00FB2598 movaps xmmword ptr [b2],xmm0
c1 = _mm_add_ps(a1, b2);
00FB259F movaps xmm0,xmmword ptr [a1]
00FB25A3 addps xmm0,xmmword ptr [b2]
00FB25AA movaps xmmword ptr [ebp-260h],xmm0
00FB25B1 movaps xmm0,xmmword ptr [ebp-260h]
00FB25B8 movaps xmmword ptr [c1],xmm0 可以看到共有12个movaps指令和1个addps指令。而SSE的汇编代码只有2个movaps指令和1个addps指令,可见其时间的差别应该主要是由于Intrinsic的内存读写造成的。
Debug下面的结果是没有出意料之外的,那么Release下的结果则真是出乎意料的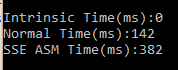
使用SSE汇编的最慢,C++实现都比起快很好,可见编译器的优化还是非常给力的。而Intrinsic的时间则是0,是怎么回事。查看反汇编的代码发现,那个加法只执行了一次,而不是执行了很多次。应该是优化器根据Intrinsic行为做了预测,后面的多次循环都是无意义的(一同学告诉我的,他是做编译器生成代码优化的,做的是分支预测,不过也是在实现中,不知道他说的对不对)。
5. 总结
学习SSE指令将近两个周了,做了两篇学习笔记,差不多也算入门了吧。这段时间的学习总结如下:
- SSE指令集正如其名字 Streaming SIMD Extensions,最强大的是其能够在一条指令并行的对多个操作数进行相同的运算,根据操作数长度和寄存器长度的不同能够同时运算的个数也不同。以32位有符号整数为例,128位寄存器(也是最常用的SSE指令集的寄存器)能够同时运算4个;AVX指令集的256位寄存器能够同时运算8个;AVX-512 的512位寄存器能够同时运算16个。
- 在使用SSE指令时要特别主要操作数的类型,整型则要区分是有符号还是无符号;浮点数则注意其精度是单精度还是双精度。另外就是操作数的长度。即使是同样的128位二进制串,根据其类型和长度也有多种不同的解释。
- 前面多次提到,编译器的优化能力是很强的,不要刻意的使用SSE指令优化。而在要必须使用SSE的时候,要谨记SSE的强大之处是其并行能力。
又是一个阳光明媚的周五下午,说好的今天要下大暴雨呢,早晨都没敢骑自行车来上班,回去的得挤公交啊。话说,为啥不说坐公交或者乘公交,而要挤公交呢。