现代操作系统 第三章 内存管理 习题答案
-
首先,需要使用特殊的硬件进行比较,而且必须快速,因为它用于每个内存引用。第二,使用4位密钥,一次只能在内存中存储16个程序(其中一个是操作系统)。
-
这是个意外。基址寄存器是16384,因为程序恰好加载在地址16384。它本来可以放在任何地方。限界寄存器是16384,因为程序包含16384字节。它可以有任何长度。加载地址恰好与程序长度匹配是纯粹的巧合。
-
几乎整个存储器都必须被复制,这需要读取每个字,然后在不同的位置重写。 读取4个字节需要4 nsec,因此读取1个字节需要1 nsec,写入需要另外2 nsec,每个字节紧缩总共2 nsec。 这是500,000,000字节/秒的速率。 要复制4 GB(232字节,大约4. 295×109字节),计算机需要232 / 500,000,000秒,大约859毫秒。 这个数字有点麻烦,因为如果内存底部的初始孔是k字节,则不需要复制那些k字节。 但是,如果有许多孔和许多数据段,则孔将很小,因此k将很小并且计算中的误差也会很小。
-
首次适配20 MB,10 MB,18 MB。 最佳适配12 MB,10 MB和9 MB。 最差适配20 MB,18 MB和15 MB。 下次适配20 MB,18 MB和9 MB。
-
真实内存使用物理地址。 这些是存储器芯片对总线作出反应的数字。 虚拟地址是引用进程地址空间的逻辑地址。 因此,无论机器是否具有比4 GB更多或更少的内存,具有32位字的机器都可以生成高达4 GB的虚拟地址。
-
对于4 KB的页面大小,(页面,偏移)对是(4,3616),(8,0)和(14,2656)。 对于8 KB的页面大小,它们是(2,3616),(4,0)和(7,2656)。
-
(a) 8212. (b) 4100. © 24684.
-
他们建立了一个MMU,并将其插入8086和总线之间。因此,所有8086个物理地址作为虚拟地址进入MMU。然后,MMU将它们映射到物理地址上,并发送到总线上。
-
需要有一个可以将虚拟页面重新映射到物理页面的MMU。 此外,当引用当前未映射的页面时,需要存在操作系统的陷阱,以便它可以获取页面。
-
如果智能手机支持iPhone,Android和Windows手机都支持的多道程序设计,则支持多个进程。 如果父进程和子进程之间共享进程分支和页面,则写入时复制绝对有意义。 智能手机比服务器小,但逻辑上并没有那么不同。
-
对于这些尺寸
(a)M必须至少为4096才能确保每次访问X元素时TLB未命中。由于N仅影响X的访问次数,因此N的任何值都可以。
(b)M应该至少为4,096,以确保每次访问X元素时TLB未命中。但是现在N应该大于64K以使TLB抖动,即X应该超过256 KB。 -
组合的所有进程的总虚拟地址空间为nv,因此页面需要大量存储空间。 但是,数量r可以在RAM中,因此所需的磁盘存储量仅为nv-r。 这个数量远远超过实际需要的数量,因为实际上很少会有n个进程在运行,而且几乎不需要所有进程都需要最大允许的虚拟内存。
-
每k条指令发生一次页面错误,会给平均值增加额外的n /k μsec开销,因此平均指令需要1+n/ k nsec。
-
页表包含232/213个条目,即524,288。 加载页面表需要52毫秒。 如果进程达到100毫秒,则包括用于加载页表的52毫秒和用于运行的48毫秒。 因此,52%的时间用于加载页表。
-
在这种情况下:
(a)我们每页需要一个条目,或224 = 16×1024×1024个条目,因为页码字段中有36 =48-12位。
(b)指令地址将在TLB中达到100%。 在程序移动到下一个数据页之前,数据页将具有100命中率。 由于4 KB页面包含1,024个长整数,因此每1,024个数据引用将有一个TLB未命中和一个额外的内存访问。 -
TLB的命中率为0.99,页表为0.0099,页面错误为0.0001(即10,000个引用中只有1个会导致页面错误)。 以秒为单位的有效地址转换时间为:
0.99*1+0.0099*100+0.00016106≈602个时钟周期。
请注意,有效地址转换时间非常长,因为即使页面错误仅在10,000个引用中出现一次,它也会受页面替换时间的影响。 -
考虑,
(a)多级页表由于其层次结构,减少了需要在内存中的页面实际页面的数量。 实际上,在具有大量指令和数据局部性的程序中,我们只需要顶级页表(一页),一个指令页和一个数据页。
(b)为三个页面字段中的每一个分配12位。 偏移字段需要14位来寻址16 KB。 这为页面字段留下了24位。 由于每个条目是4个字节,因此一个页面可以容纳212个页面表条目,因此需要12个位来索引一个页面。 因此,为每个页面字段分配12位将解决所有238个字节。 -
虚拟地址从(PT1,PT2,偏移)变为(PT1,PT2,PT3,偏移)。 但虚拟地址仍然只使用32位。 虚拟地址的位配置从(10,10,12)变为(2,9,9,12)
-
20位用于虚拟页码,剩下12位用于偏移。 这会产生4 KB的页面。 虚拟页面的二十位意味着220页。
-
对于一级页表,需要232/212或1M页。 因此,页表必须具有1M条目。 对于两级分页,主页表具有1K条目,每个条目指向第二页表。 只使用其中两种。 因此,总共只需要三个页表条目,一个在顶级表中,一个在每个下级表中。
-
代码和参考字符串如下

代码(I)表示指令引用,而(D)表示数据引用 -
有效指令时间为1h+5(1-h),其中h是命中率。 如果我们将这个公式等于2并求解h,我们发现h必须至少为0.75。
-
相联存储器实质上将密钥与多个寄存器的内容同时进行比较。 对于每个寄存器,必须有一组比较器,用于将寄存器内容中的每个位与要搜索的密钥进行比较。 实现这种器件所需的门(或晶体管)的数量是寄存器数量的线性函数,因此扩展设计会线性地成本高昂。
-
对于8 KB页面和48位虚拟地址空间,虚拟页面的数量为248/213,即235(约340亿)。
-
主存储器有228/213 = 32,768页。 32K哈希表的平均链长为1.要低于1,我们必须使用下一个尺寸,为65536个条目。将32768个条目分布在65536个表槽上将得到0.5的平均链长度,从而确保快速查找。
-
这是不可能的,除非程序的执行过程在编译时是完全可预测的,这种情况不常见,也不是非常有用。如果编译器收集有关过程调用代码中位置的信息,则可以在链接时使用此信息重新排列对象代码,使过程靠近调用它们的代码。这将使过程更可能与调用代码位于同一页上。当然,这对程序中许多地方调用的程序没有多大帮助。
-
在这种情况下
(a)每个引用都将缺页中断,除非页框的数量是512,即整个序列的长度。
(b)如果有500页框,则将页面0-498映射到固定页框并且仅改变一页框。 -
FIFO的页框如下:
x 0172333300
xx017222233
xxx01777722
xxxx0111177
LRU的页框如下:
x 0172327103
xx017232710
xxx01773271
xxxx0111327
FIFO产生六次缺页中断; LRU为7次。 -
将选择0位的第一页,在本例中为D.
-
计数器是
Page 0:0110110
Page 1:01001001
Page 2:00110111
Page 3:10001011 -
顺序:0,1,2,1,2,0,3。在LRU中,第1页将被第3页替换。在clock中,第1页将被替换,因为所有页面都将被标记,表针位于 在第0页。
-
页面的生存时间是2204-1213= 991.如果τ=400,它肯定不在工作集中,并且最近没有被引用,因此它将被移除。 τ=1000的情况不同。 现在页面属于工作集,所以它不会被删除。
-
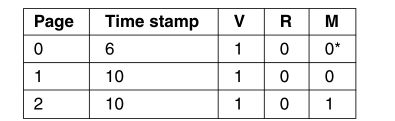
33.考虑,
(a)对于设置的每个R位,将时间戳值设置为10并清除所有R位。 您还可以将(0,1)R-M条目更改为(0,0 *)。 因此第1页和第2页的条目将更改为:
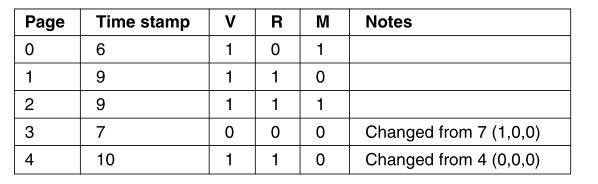
(b)移除第3页(r=0,m=0),加载第4页:
-
考虑,
(a)属性是:(FIFO)加载时间; (LRU)最新参考时间; 和(最优)将来最近的参考时间。
(b)有标记算法和替换算法。 标签算法使用部分a中给出的属性标记每个页面。 移除算法驱逐具有最小标签的页面。 -
寻道加旋转延迟为10毫秒。对于2KB页面,传输时间约为0.009766毫秒,总计约为10.009766毫秒。加载其中的32页大约需要320.21毫秒。对于4KB的页面,传输时间增加了一倍,约为0.01953毫秒,因此每页的总时间为10.01953毫秒。加载其中16页大约需要160.3125毫秒。对于如此快速的磁盘,最重要的是减少传输的数量(或者将页面安全地放在磁盘上)。
-
NRU置换第2页.FIFO置换第3页.LRU置换第1页。第二次机会置换第2页。
-
共享页面带来了各种复杂情况和选择:
(a)如果进程B永远不会访问共享页面,或者当页面再次被换出时访问它,则应该延迟进程B的页表更新。 不幸的是,在一般情况下,我们不知道将来B将采取什么流程。
(b)成本是这种懒惰的缺页错误处理会导致更多的缺页错误。 每个缺页错误的开销在确定此策略是否更有效方面起着重要作用。 (旁白:此成本类似于支持某些UNIX fork系统调用实现的写时复制策略所面临的成本。) -
片段B,因为代码比片段A具有更多的空间位置。对于外部循环的其他迭代,内部循环只会导致一个缺页错误。(将只有32个缺页错误。)[旁白(片段A):由于一个页框是128个字,X数组的一行占据了页面的一半(即64个字)。整个阵列适合64 *32/128=16页框。对于给定的列,代码的内部循环将逐步通过连续的x行。因此,对x[i][j]的其他引用都会导致缺页错误。缺页错误总数将为64 *64/2=2048]。
-
当然可以。
(a)这种方法与在智能手机中使用闪存作为寻呼设备有相似之处,但现在虚拟交换区是位于远程服务器上的RAM。必须开发虚拟交换区域的所有软件基础设施。
(b)注意到磁盘驱动器的访问时间在毫秒范围内,而通过网络连接的RAM的访问时间在微秒范围内(如果软件开销不太高),这种方法可能是值得的。但是,只有在服务器场中有大量空闲RAM的情况下,这种方法才有意义。此外,还有可靠性问题。由于RAM是易失性的,如果远程服务器停机,虚拟交换区域将丢失。 -
PDP-1寻呼鼓具有无旋转延迟的优点。每次将内存写入磁鼓时,这节省了一半的旋转延迟。
-
正文8页,数据5页,堆栈4页。程序不适合,因为它需要174096字节的页面。对于512字节的页面,情况不同。这里的文本是64页,数据是33页,堆栈是31页,共有128512字节的页,这是合适的。对于较小的页面大小,可以,但对于较大的页面则不行。
-
该程序有15,000个缺页中断,每个中断使用2毫秒的额外处理时间。缺页中断开销一起是30秒。这意味着在使用的60秒中,一半用于缺页中断开销,一半用于运行程序。如果我们以两倍的内存运行程序,我们得到一半的内存缺页中断,只有15秒的缺页中断开销,因此总运行时间将是45秒。
-
适用于无法修改的程序和不能被修改的数据。然而,程序不能被修改是很常见的,而且很少有数据不能被修改。如果二进制文件上的数据区域被更新的页面覆盖,那么下次程序启动时,它将没有原始数据。
-
指令可以跨越页面边界,导致两个缺页中断只是为了获取指令。获取的字也可以跨越页面边界,再生成两个缺页中断,总共四个。如果字必须在存储器中对齐,则数据字只能导致一个缺页中断,但是在具有4 KB页面的机器上在地址4094处加载32位字的指令在某些机器(包括x86)上是合法的。
-
当最后一个分配单元未满时,就会发生内部碎片。当两个分配单元之间浪费空间时会发生外部碎片。在分页系统中,最后一页中的浪费空间会因内部碎片而丢失。在纯分段系统中,某些空间总是在段之间丢失。这是由于外部碎片造成的。
-
否。搜索键同时使用段号和虚拟页码,因此可以在一次匹配中找到确切的页面。
-
(a)(14,3)否(或0xD3或1110 0011)
(b)NA 保护错误:写入读取/执行段
(c)NA缺页中断
(d)NA保护错误:跳转到读/写段 -
当所有应用程序的内存需求众所周知并受到控制时,不需要一般的虚拟内存支持。例如智能卡、专用处理器(如网络处理器)和嵌入式处理器。在这种情况下,我们应该始终考虑使用更真实的内存的可能性。如果操作系统不需要支持虚拟内存,那么代码将更简单、更小。另一方面,尽管设计要求不同,但从虚拟内存中获得的一些想法仍可能得到有益的利用。例如,程序/线程隔离可能是分页到闪存。
-
此问题涉及虚拟机支持的一个方面。 最近的尝试包括Denali,Xen和VMware。 根本障碍是如何实现接近本机的性能,也就是说,执行的操作系统本身就有内存。 问题是如何快速切换到另一个操作系统,以及如何处理TLB。 通常,您希望为每个内核提供一定数量的TLB条目,并确保每个内核在其正确的虚拟内存上下文中运行。 但有时候硬件(例如,某些英特尔架构)想要在不知道你想要做什么的情况下处理TLB未命中。 因此,您需要在软件中处理TLB未命中或提供硬件支持以使用上下文ID标记TLB条目。