Google's BBR拥塞控制算法模型解析
1.首先,我对这次海马台风对深圳的影响非常准确,看过我朋友圈的都知道,没看过的也没必要知道,白赚了一天”在家办公“是收益,但在家办公着实效率不高,效果不好。
2.我为什么可以在周五的早上连发3篇博客,一方面为了弥补因为台风造成”在家办公“导致的时间蹉跎,另一方面,我觉的以最快的速度分享最新的东西,是一种精神,符合虔诚基督徒的信仰而不是道德约束。
3.上半年的时候,温州皮鞋厂老板推荐了一个会议,大致是说”迄今为止的Linux进程调度器实现都是错误的...“,这让我觉得可以写一篇科普,但一直没有动笔,这次BBR又让我想起这件事。
由于本文是讲BBR,所以关于调度器的内容,请自行阅读《 THE LINUX SCHEDULER:A DECADE OF WASTED CORES》,关于这个方面的科普,我可能永远都没机会写了,但是大家可以根据我推荐的东西自己去搜索,而且,我记得有一天我在班车上我曾经把这个推荐给我的同事了,不知道他是不是通过别的渠道分享了。
之前的几篇关于TCP BBR拥塞控制算法的文章,我把精力和焦点放在了BBR的外围以及实现本身,然而这两者都说不是核心!我为什么这么说?海马刚走,我以台风为例。台风外围和台风眼都是没啥影响力的地带,所以我说,一项技术,你仅仅知道它的外围-比如它的背景,用法之类,或者仅仅知道它的实现-比如读过/Debug过其源码,或者二者兼得,都不是重要的,都没啥影响力,技术的核心不在这里!所以,在介绍了BBR的背景和算法细节之后,我想简单说一下其思路后面的模型,这是关键的关键。
既然涉及到了BBR的背后思想,我就把它奉为大写了,不再bbr,而是BBR了!
本文的内容来自于对BBR算法个人理解的解说。图片改自Yuchung Cheng和Neal Cardwell的 PPT,我增加了自己的理解。
0.模型
模型是最根本的!
我非常讨厌把所有的东西杂糅在一起,我比较喜欢各个击破,所以说,我最喜欢正交基!我希望把待观测的东西分解成毫无耦合的N个方面,然后各自研究其特性。这个思路我曾经无数次提出,但是几乎没人会听,因为一旦分解,你将看不到目标,看不到结果,拆了的东西并不定能再装起来...令人欣慰的是,TCP的BBR算法思路也是这样,不幸的是,TCP领域的顶级专家并没有N维拆解,人家只是拆解了2个维度。
带宽和RTT BandWidth & RTT我很惊奇Yuchung Cheng(郑又中)和Neal Cardwell是怎么发现这个正交基的,为什么之前30年都没有人发现这个,最为惊奇的是,他们竟然对了!他们的模型基于下图展开:

这张图几乎完全描述了网络的行为!这就是网络传输的本质模型!之所以之前的Reno到CUBIC都是错的,是因为它们没有使用这个模型,我先来解释一下这个模型,然后再看看将Reno/CUBIC套在这个模型上之后,是多么的荒唐。
值得注意的是,这个模型是Kleinrock & Gale早在1981年就提出来的,然而直到现在才被证明是有效的。之前的年月里,人们面临着实现问题(同时测量问题,后面会讲)。因此我把这个模型最终的实现者作为模型的主语,即Yuchung Cheng和Neal Cardwell们的模型,这并不是说他们是模型的发明者。就类似牛顿的定律一样,其实伽利略已经提出了,只是没有用数学系统的论证并总结而已。
1.有破才有立
首先,我们先要知道Reno/CUBIC错在哪里,然后才能知道BBR是怎么改进的。骨子里,人们总希望时间成为横轴,除了生命和做爱,人类几乎所有的行为都是在于尽量缩短时间。
效率是什么?人们只知道效率的分母是时间!人们一旦把时间确定为横轴,很多时候就会蒙蔽很多真相。这是一个哲学问题,我以后再谈。
人们在为TCP建立性能模型的时候,总是用”序列号-时间曲线“,”序列号RTT曲线“等来观察(比如Wireshark等分析工具),目标呢,很简单,就是查一下”一个连接最快能突突多少数据“,
但是,这些都错了!Why?
因为时间轴具有滞后性欺骗特征,所有基于时间轴的效率提升方案都是”先污染后治理“的方案!
看一下上面那个模型图,所有30年来的拥塞控制算法的目标都是收敛于一个错误的收敛点(图的右边):不断地增加数据的传输,试图填满整个网络以及网络上的所有缓存,以为这样就会达到比较高的带宽利用率,直到发现丢包,然后迅速降低数据发送量,之后重新向那个错误的收敛点前进,如此反复。这就是锯齿的根源!这个现象在以上的模型图上显示的非常明确,根本就不用解释。如果一开始人们就使用这个模型图,任何人都不禁会问:为什么要一直在警戒区域徘徊呢?正确的收敛点不应该是畅通模式的最右端吗??我以经典的VJ版TCP拥塞图来说明一下:
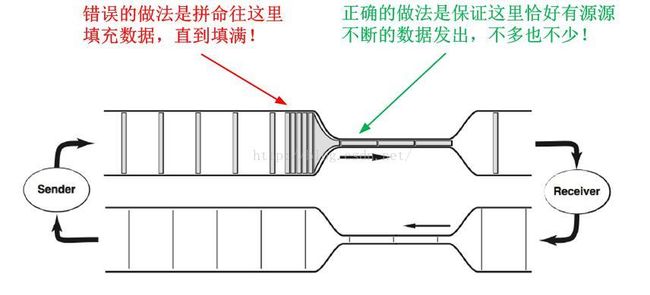
TCP与此不同,TCP的Reno/CUBIC并不是因为条件不具备才往缓存里屯数据包的,对于能搞出CUBIC那么复杂算法的人,搞定BBR根本就是小菜一碟,我承认我看不太懂CUBIC的那些算式背后的东西,但我对BBR的理解非常清晰,像我这种半吊子水平几个月前就差一点实现了BBR类似的东西,但我绝对想不到CUBIC那么复杂的东西,之所以Reno/CUBIC被使用了30多年,完全是因为人们一直以为那是正确的做法,竟然没有任何人觉得这种做法是有问题的。
基于{RTT,Delivery Rate}正交基的新模型一出来,人们好像猛然看到了事实的真相了:

问题的根源在于,BBR拥塞控制模型和BBR之前的拥塞控制模型对BDP的定义不同。BBR的模型中,BDP是不包括网络缓存的,而之前的模型中,是包括缓存的,这就是说,包括缓存的拥塞控制模型中,拥塞控制本身和网络缓存之间有了强耦合!要想做一个好的拥塞控制算法,就必须要彻底理解网络缓存的行为,然而作为端到端的TCP协议,是不可能理解网络缓存的。所以一直以来,30年以来都没有出现一个比较好的算法,Reno到CUBIC,改进的只是算法本身,模型并没有变!
网络缓存是复杂的,有基于深队列的缓存,也有基于浅队列的缓存,不管怎样,都会遇到 BufferBloat的问题,这是TCP所解决不了的,虽然如此,TCP还是尝试填满包括这些永远琢磨不透的网络缓存在内的BDP,这个填满的过程是逐步的,开始于慢启动,然后...这个逐步填满BDP是两个过程,首先是RTT不变,逐渐填满不包括网络缓存在内的管道空间(在我的定义中,这个属于时间延展性的缓存空间),然后是逐渐填满网络缓存的过程(在我的定义中,这部分属于不带时间延展性的时间墙空间),问题处在TCP对后一个过程的不可知不可测的特性!!
既然知道了Reno/CUBIC的问题根源,那么BBR是怎么解决的呢?换句话说,BBR希望收敛在上图中红色圈圈的位置,它怎么做到的呢?
列举做法之前,我先列举一下{RTT,Delivery Rate}正交基的美妙:

最终,BBR的BDP如下图所示,不再包括警戒区的网络缓存:
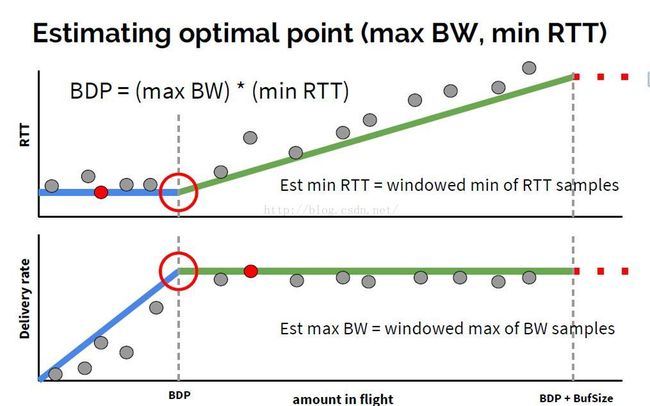

2.BBR对最大带宽和最小RTT的探测
从模型图上可以清楚的看出如何探测最大带宽: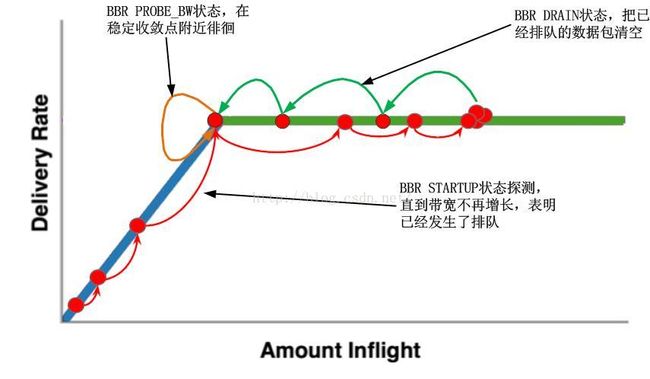
在这里首先要谈一下BBR之前那些”基于时延“的拥塞控制算法。Reno/CUBIC属于基于丢包的拥塞控制算法,而像Vegas之类的属于基于时延的算法,其区别在于,Vegas对RTT的变化比较敏感,判断拥塞的要素是RTT的变化而不是丢包,不管哪种算法,都需要外部发生一个事件,提示TCP连接已经处于拥塞状态了。事实证明,Vegas之类的算法工作的并不好,原因在于它无法抵抗假拥塞,偶尔一次非拥塞造成的RTT增加也会引发TCP主动降窗,这种算法无法对抗共享深队列的其它基于丢包的TCP连接的竞争,因此无法普遍被采用。
BBR需要测量最小RTT,但是它是基于时延的拥塞算法吗?
并不是!起初,当我第一次测BBR的时候,那是在国庆假期我醉酒后的第二天,几乎动用了家里的所有设备(iMac一台,Macbook Pro一台,ThinkPad一台,ROOT-Android平板一个,刷过的荣耀立方一个,树莓派开发板一块,ROOT-Android手机一个,极路由一个,iPhone两个,iPad两个...),搭建了一个测试网络,让BBR和CUBIC,Reno一起跑,并制造了RTT突变,发现BBR并没有降速,甚至对RTT的突变不会有反应,而对RTT的变化的剧烈反应是基于时延的拥塞算法的基本特征,但BBR并没有!任何组合情况下BBR都可以完爆其它算法。这是为什么?
BBR在一个不随时间滑动的大概10秒的时间窗口中采集最小RTT,BBR只使用这个最小RTT计算Pacing Rate和拥塞窗口。BBR不会对RTT变大进行反应。但是如果整的发生了拥塞,RTT确实会变大,BBR怎么发现这种情况呢?答案就在于这个时间窗口的超期滑动,如果在一个时间窗口内持续没有采集到更小的RTT,那么就会将当前的RTT赋值个最小RTT。BBR就是这样抵抗假拥塞的。秒级的窗口内,什么都是瞒不住的。这就是RTT的测量以及使用原则:

之前在网上看到一个美国硅谷工作的实习生质疑BBR会因为时延反应而不利于公平性,我本来想回复的,后来感觉翻次墙太麻烦了,
3.总结
我们一直需要的是一个”可持续发展“的方案来解决效率问题。不幸的是,TCP出现的30年来,我们见到的所有拥塞控制算法都是这种所谓的先污染后治理的方案,贯穿从Reno到CUBIC的所有算法。先把缓存填充到爆,然后再主动缓解,因为所有基于丢包的算法都在抢着填爆所有缓存,基于时延的算法太君子的主动降速行为就显得竞争性不够,典型的劣币驱良币的场景。我一直都以为TCP的加性增,乘性减是一个人人为我,我为人人的策略,确实,可以这么理解,然而这是一种敬人一杯,自罚一壶的策略,结局就是普遍倒下...
大家都能随口说出ssthresh的作用是什么,比如当窗口大于它就怎么怎么样,当小于它就如何什么的,但是有人知道它的含义吗?也许,你会发现ss是slow start的缩写,而thresh则是threshold的缩写,门限的意思,但是这不是正确答案,正确的答案在 这里:
The capacity of a path can be informally defined by the sum of unused available bandwidth in the forward path and the size of buffers at bottleneck routers.
Typically, this capacity estimation is given by ssthresh.
真相如此晚近才被揭示,怪不得人们只知道ssthresh的用法而不知其含义啊!稍微详细一点的东西也可以看我写的一篇文章《 TCP核心概念-慢启动,ssthresh,拥塞避免,公平性的真实含义》。
事实上ssthresh定义了路径上所有缓存(包括时间延展缓存和时间墙缓存),所以说,当检测到丢包时,会将cwnd减少1/2并赋值给ssthresh,此时因为BDP已经满载,所以说其容量的1/2就是路径的缓存容量!Perfect!然而这是错的,TCP误以为所有的缓存都是可以填充的,然而事实却是,只有时间延展性质的缓存,即网络本身才是可以填充的,而时间墙缓存却是应急的缓存,所有的TCP只要都避免使用时间墙缓存(包括路由器,交换机上的队列缓存),其才能真正起到应急的作用,带宽利用率才会最大化!
应急车道是应急的,而不是行车的!
BBR的新模型把这一切错误展示给了所有人,因此,BBR的指示是,保持最大带宽,并最小化网络缓存的利用。事实上,基于新模型额BBR要比之前的算法简单多了!千万不要觉得新算法一定很难,相反,BBR超级简单。
也许你也已经想到了BBR类似的思路,但是它能够在Linux上实现还是要对Linux的TCP实现动手术的,并不仅仅是一个拥塞模块那么简单,前几天的文章说了N遍,BBR之前的拥塞控制算法在非Open状态会被接管,再牛逼的算法也完全没用,由于CUBIC试图填满整个包括队列缓存在内的所有缓存空间,在当下的核心深队列,边缘浅队列高速网络环境中,只有不到40%的时间内TCP的拥塞状态是处于Open状态,大部分情况,传统的算法根本就跑不到!好在BBR的实现中,作者注意到了这一点,完成了TCP拥塞控制的外科手术,快哉!
BBR会在4.9或者5.0内核中成为默认的TCP拥塞控制算法吗?我觉得可能还需要更多的测试,CUBIC虽然表现不佳,但起码并没有因为其表现带来比较严重的问题,CUBIC的运行还是很稳定的。但是我个人希望,我希望BBR赶紧成为所有Linux版本的标配,彻底结束所谓TCP单边加速这个丑行!
附:时间延展性缓存和时间墙缓存
我一直强调BBR是简单的,是因为它确实简单。因为在上半年的时候,我差一点就想出了类似的算法,当时我已经准备对PRR做手术了。我觉得拥塞控制算法对拥塞窗口的控制权不够大,我希望用拥塞算法本身的逻辑来绝对窗口如何调整,而不是一味地PRR!我不相信检测到三次重复ACK就一定是发生了丢包,即便是在非Open状态,比如Recovery状态,我也希望在我的算法认为可以的情况下可以增加窗口...我仔细分析了网络的特征,总结除了两类缓存:
带有时间延展性的缓存,即网络本身(确切的说是网线上跑的数据,从A到B需要时间,所以认为网络是具有存储功能的);
时间墙缓存,即路由器交换机的队列缓存。这类缓存的性质就是内存。
关于这个,请参见我6月份写的一篇文章《 TCP自时钟/拥塞控制/带宽利用之脉络半景解析》,我在想,CUBIC算法到底要不要诱发TCP填充时间墙缓存,然而就CUBIC本身而言,区别这两类缓存非常困难...我当时没有一个好的模型,但我确实已经区别出了两类缓存...
很遗憾,我没有继续下去,很多事情并不是我个人所能左右的,也不是我能安排的,不过当我看到BBR的那一刻,着实有一种找到答案的感觉。虽然,虽然很多事情不是我个人所能左右和安排,当我惧怕开始的时候,多数时候不知不觉中,默默地就结束了。你是不是也有这种感觉。
最后,那个哲学问题,听着窦唯的老歌,我想可以谈谈了。效率的分母是时间的问题。
无论人们怎么努力,分母也不能是0!但有个例外,那就是一条蛇从尾巴开始吃掉自己的情形!你能想象那种场景吗?除非可以沿着时间轴任意穿越,否则这就是不可能的,是这样吗?我觉得这种事没那么复杂,只要上升一个维度去考虑就好了,任何低一级的维度里任何东西对于高一级维度而言就是一个点,也就是一个小宇宙。一条蛇是一个三维动物,它永远也意识不到四维时空里面的一个点,就是它自己吃掉的自己。爆炸!