不同位置的tcptrace分析以及FQ如何减少TCP无效重传
昨晚,前同事发微信给我,说之前公司的领导又在夸我了,还截了图...我看了之后好感动,这是必然的。好了,感性的话到此为止。今天下了一天的雨,心情也不错,我觉得继续分享一些技术上的东西是对我之前的公司,现在的公司以及各种帮助过我的同道中人最大的感激。这段话写在前面,简述了我写本文的心情。

以上是一个理想均匀管道的情形,然而并不存在这样的管道!数据从发送端一路到达接收端,会遭遇各种各样的”非均匀“情景,比如与其它的数据流共同排队于一个交换机,比如流量被监管设备整形,比如线路噪声丢包等,任何一种”异常非均匀“的情景都可能会造成数据包的丢失,IP网络并不会将这个丢包事件通知给TCP发送端,所以TCP发送端只能根据ACK中包携带的信息来”猜测“数据包是否丢失,并且决定是否要重传它!
显然,这个猜测总是会有猜错的时候,这是一定的!
现在我们来看一下在哪里可以发现这个错误。我们的依据依然是tcptrace图。
在发送端,显然这是发现不了的,因为这里正是做出重传决定的地方(后面你会看到,有了FQ实现的Pacing发送,就不同了)。
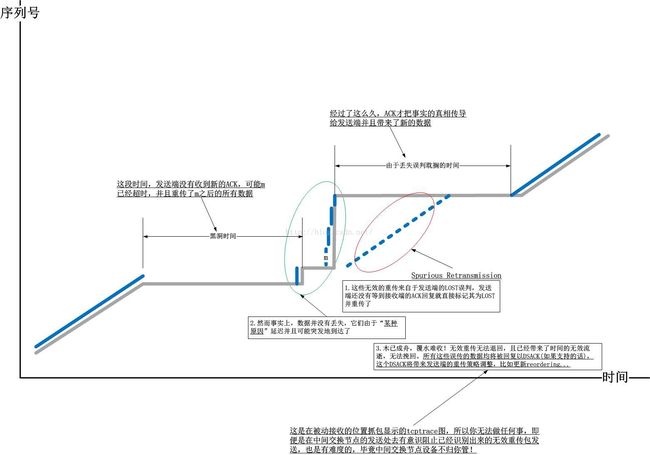
好,让我们接下来将抓包点向接收端移动,在阐述细节之前,我们必须先可以从tcptrace图上明确识别到什么样的重传是无效重传。我们以下图为例:
我们首先来看一下由于误判带来的无效重传在TCP接收端的tcptrace图中的表现形式:
好了,让我们把实现转移到发送端。
我们已经知道,发送端在重传数据包的时候,数据直接从TCP层的一个while循环中一股脑突突出去,根本无法知道重传的这个数据包是不是真的丢了,但是这次,我们加上FQ Pacing!这意味着什么?
这意味着数据包在真正发送到线路上之前,会在FQ队列中等待一定的间隔。如果一个无效重传的数据包P等待在FQ队列里,在它被发出去之前,针对P的ACK回来了,会怎样?我们期待的是这个ACK可以帮我们识别出一些无效的重传包并且阻止其上路。
但是事实是不是这样呢?
一个新的ACK会清除正在传输的重传队列里的数据包,因此会清除P在TCP重传队列里的副本,但是并不会清除FQ队列中的重传数据包,也就是说不会清除P本身,这必然会带来一些问题,如下图所示:
---------------------------------
是不是应该对重传包进行特殊处理,比如给它们直通通道,不做Pacing。答案显然是否定的,因为Pacing是为了治愈BufferBloat的,而任何携带数据的TCP数据包都是制造BufferBloat的根源之一。那么是不是至少让重传包优先发送呢?毕竟由于检测到丢包,空洞造成窗口卡住,它们关系到TCP滑动窗口是否继续滑动。答案是肯定的!
重传包的插队机制
这是FQ中已经有的机制,简单点说,就是针对重传的数据包,从队头开始入队,排在其它已经排队的重传包后面,针对新数据包,则直接排在队列末尾。这是一个典型的同类插队机制的实现,代码的注释已经相当明了:
---------------------------------
然而我受骗了!
这太JB扯了!我不说在skb里添加private字段有多么复杂,但使用一个有明确意义的truesize字段作为标记,绝对不是一个正确的做法!
这是一段垃圾代码!不管是区分是否是重传包还是区分是否是纯ACK包,我想你一定有更好的办法,这里不再赘述。
---------------------------------
对于Linux FQ实现的不足,我们首先要实现的是skb_is_retransmit,这个很简单,采用任何方法都可以!甚至你都可以学着skb_is_tcp_pure_ack的样子将其实现为:
---------------------------------
下面该实现图示中展示的优化了。原则如下:
1.ACK要及时反馈,且可以积累确认,纯ACK可以容忍丢包,且不会过多Bloat缓存,不需要Pacing,所以本机FQ对ACK要直通。这是FQ已经落实的。
2.重传包携带数据,不容忍丢失,且可能Bloat缓存,故需要Pacing,然而其优先级要高于新数据,所以重传包要插队。经过实现skb_is_retransmit,FQ也落实了。
3.瞎子TCP总会误判丢包,既然FQ有检测到误判带来的无效重传,那就要想办法阻止这些重传包发送到线路上。这点有待落实。
4.尽管在接收端我们对无效重传的数据包无能为力,因为木已成舟,但是对于中间路径上tcptrace显示重传线落到ACK线下面的地方,确实可以就此阻止无效包的发送。有待落实。
上述第4点靠个人力量是不可能落实的,没有人会让你在骨干网的交换节点上部署一个你自己的发包检测模块,除非有一天,这已经成了标准!但是第3点是很容易落实的。如果没有FQ,那么对于发送端而言就没有队列,没有队列就等于数据包发送没有延时,一旦数据包被丢到网络线路,就等于覆水难收了。幸亏有FQ,我们有机会发现无效的重传并能阻止!
---------------------------------
前面说了那么多,只是为了最后这么一个小修改!非常简单,只需要更改一下FQ的dequeue逻辑即可。这个逻辑如下图所示:
在前面描述tcptrace图的几篇文章中,我有个基本的假设,那就是抓包的位置都在TCP的发送端,因此所有的结论都基于这个假设。然而,抓包是可以在任意位置进行的,比如中间任意一个经由的交换节点,比如接收端。不管在哪个位置,tcptrace图显示的发送线随着抓包点与接收端的距离而改变,我们知道平行于时间轴的线相交于发送线和ACK线之间的部分代表抓包位置自发送包到收到此包ACK的RTT,这个RTT显然随着抓包点距离接收端距离的临近而缩小,这个关系我希望通过以下的图示表现出来:
我列举三个典型的例子,分别在发送端,中间交换节点,接收端抓包,理想中的tcptrace图是下面的样子:
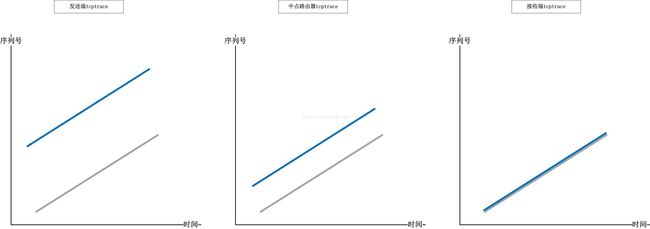
以上是一个理想均匀管道的情形,然而并不存在这样的管道!数据从发送端一路到达接收端,会遭遇各种各样的”非均匀“情景,比如与其它的数据流共同排队于一个交换机,比如流量被监管设备整形,比如线路噪声丢包等,任何一种”异常非均匀“的情景都可能会造成数据包的丢失,IP网络并不会将这个丢包事件通知给TCP发送端,所以TCP发送端只能根据ACK中包携带的信息来”猜测“数据包是否丢失,并且决定是否要重传它!
显然,这个猜测总是会有猜错的时候,这是一定的!
现在我们来看一下在哪里可以发现这个错误。我们的依据依然是tcptrace图。
在发送端,显然这是发现不了的,因为这里正是做出重传决定的地方(后面你会看到,有了FQ实现的Pacing发送,就不同了)。
好,让我们接下来将抓包点向接收端移动,在阐述细节之前,我们必须先可以从tcptrace图上明确识别到什么样的重传是无效重传。我们以下图为例:


好了,大致的原理就说到这,关于怎么读图的原理应该已经没什么好说的了,现在开始,我们来详细分析。
---------------------------------我们首先来看一下由于误判带来的无效重传在TCP接收端的tcptrace图中的表现形式:
好了,让我们把实现转移到发送端。
我们已经知道,发送端在重传数据包的时候,数据直接从TCP层的一个while循环中一股脑突突出去,根本无法知道重传的这个数据包是不是真的丢了,但是这次,我们加上FQ Pacing!这意味着什么?
这意味着数据包在真正发送到线路上之前,会在FQ队列中等待一定的间隔。如果一个无效重传的数据包P等待在FQ队列里,在它被发出去之前,针对P的ACK回来了,会怎样?我们期待的是这个ACK可以帮我们识别出一些无效的重传包并且阻止其上路。
但是事实是不是这样呢?
一个新的ACK会清除正在传输的重传队列里的数据包,因此会清除P在TCP重传队列里的副本,但是并不会清除FQ队列中的重传数据包,也就是说不会清除P本身,这必然会带来一些问题,如下图所示:

---------------------------------
是不是应该对重传包进行特殊处理,比如给它们直通通道,不做Pacing。答案显然是否定的,因为Pacing是为了治愈BufferBloat的,而任何携带数据的TCP数据包都是制造BufferBloat的根源之一。那么是不是至少让重传包优先发送呢?毕竟由于检测到丢包,空洞造成窗口卡住,它们关系到TCP滑动窗口是否继续滑动。答案是肯定的!
重传包的插队机制
这是FQ中已经有的机制,简单点说,就是针对重传的数据包,从队头开始入队,排在其它已经排队的重传包后面,针对新数据包,则直接排在队列末尾。这是一个典型的同类插队机制的实现,代码的注释已经相当明了:
/* add skb to flow queue
* flow queue is a linked list, kind of FIFO, except for TCP retransmits
* We special case tcp retransmits to be transmitted before other packets.
* We rely on fact that TCP retransmits are unlikely, so we do not waste
* a separate queue or a pointer.
* head-> [retrans pkt 1]
* [retrans pkt 2]
* [ normal pkt 1]
* [ normal pkt 2]
* [ normal pkt 3]
* tail-> [ normal pkt 4]
*/---------------------------------
然而我受骗了!
/* We might add in the future detection of retransmits
* For the time being, just return false
*/
static bool skb_is_retransmit(struct sk_buff *skb)
{
return false;
}/* locally generated TCP pure ACKs have skb->truesize == 2
* (check tcp_send_ack() in net/ipv4/tcp_output.c )
* This is much faster than dissecting the packet to find out.
* (Think of GRE encapsulations, IPv4, IPv6, ...)
*/
static inline bool skb_is_tcp_pure_ack(const struct sk_buff *skb)
{
return skb->truesize == 2;
}
static inline void skb_set_tcp_pure_ack(struct sk_buff *skb)
{
skb->truesize = 2;
}这太JB扯了!我不说在skb里添加private字段有多么复杂,但使用一个有明确意义的truesize字段作为标记,绝对不是一个正确的做法!
这是一段垃圾代码!不管是区分是否是重传包还是区分是否是纯ACK包,我想你一定有更好的办法,这里不再赘述。
---------------------------------
对于Linux FQ实现的不足,我们首先要实现的是skb_is_retransmit,这个很简单,采用任何方法都可以!甚至你都可以学着skb_is_tcp_pure_ack的样子将其实现为:
static inline bool skb_is_retransmit(const struct sk_buff *skb)
{
return skb->truesize == 3;
}
static inline void skb_set_retransmit(struct sk_buff *skb)
{
skb->truesize = 3;
}---------------------------------
下面该实现图示中展示的优化了。原则如下:
1.ACK要及时反馈,且可以积累确认,纯ACK可以容忍丢包,且不会过多Bloat缓存,不需要Pacing,所以本机FQ对ACK要直通。这是FQ已经落实的。
2.重传包携带数据,不容忍丢失,且可能Bloat缓存,故需要Pacing,然而其优先级要高于新数据,所以重传包要插队。经过实现skb_is_retransmit,FQ也落实了。
3.瞎子TCP总会误判丢包,既然FQ有检测到误判带来的无效重传,那就要想办法阻止这些重传包发送到线路上。这点有待落实。
4.尽管在接收端我们对无效重传的数据包无能为力,因为木已成舟,但是对于中间路径上tcptrace显示重传线落到ACK线下面的地方,确实可以就此阻止无效包的发送。有待落实。
上述第4点靠个人力量是不可能落实的,没有人会让你在骨干网的交换节点上部署一个你自己的发包检测模块,除非有一天,这已经成了标准!但是第3点是很容易落实的。如果没有FQ,那么对于发送端而言就没有队列,没有队列就等于数据包发送没有延时,一旦数据包被丢到网络线路,就等于覆水难收了。幸亏有FQ,我们有机会发现无效的重传并能阻止!
---------------------------------
前面说了那么多,只是为了最后这么一个小修改!非常简单,只需要更改一下FQ的dequeue逻辑即可。这个逻辑如下图所示:

---------------------------------
明天如果有时间,我一定会写一篇近几年工作学习的流水账,夜深了,想起昨天的那个微信,心里莫名感动,感觉有很多话想说出来