SYNPROXY抵御DDoS攻击的原理和优化
序
又到了周末,我又要必须写点什么了…
周末依然加班,感谢周末上班平日休息的老婆分担了几乎所有家务,一切依然…然而这些对我来讲都不是个事儿,事实上我是希望取消一切节假日和周末的,所谓的周末和节假日是我一直以来觉得出自《圣经》里面最荒唐的东西…休息时间为什么要集中化,既然有个集中化的休息时间,那么必有人会充分利用这段时间,说实话,根本就没有人把周末和假期用来休息,相反,很多时候在这些所谓的休息时间是比上班还要累的!难道每天工作4小时,然后365天每天都在工作不好吗?
当为安息日守为圣日,《十诫》之第四:
Remember the Sabbath day,to keep it holy.
Six days you shall labor,and do all your work; but the seventh day is a Sabbath to The Lord your God; in it you shall not do any work,you,or your son,or your daughter,your manservant,or your maidservant,or your cattle,or the sojourner who is within your gates; for in six days The Lord made heaven and earth,the sea,and all that is in them,and rested the seventh day; therefore The Lord blessed the Sabbath day and hallowed it
只可惜远东很少真正信基督的,更别说犹太教徒了,这让我在引述时显得有点轻松的尴尬,既然知道在中国没有圣日,便无所谓安息日了,所以我一直以来都希望,取消所有周末和节假日,这是我16年来的梦想!
我会专门写一篇《IT行业的12小时工作制》结合世界历史来联系所谓安息日和圣日,但在本文,我想谈点技术,关于DDoS攻击和nf_conntrack的技术。我的每周一报都会带有强烈的感情色彩,所以在本文中,我依旧是在为Netfilter/nf_conntrack而平反,但我并不嘲笑无知,因为技术无褒贬。
关于DDoS攻击和本文
DDoS攻击很多人都不会陌生,很多人都会花费很大的精力去对付它,然而却找不到根治的办法,DDoS攻击比那些病毒,木马什么的更难以根治!DDoS攻击特别像我们日常的感冒,不致命,但却非常之讨厌。你会花多少钱去应对一次普通的感冒呢?事实上,你甚至根本不需要花一分钱,感冒症状也会随着时间自然消失,但是如果你想让它快速离你而远去,你就势必要花点钱了。现如今,天花,霍乱,鼠疫这类致命传染病都有了根治的特效药,根治癌症,艾滋病也只是个时间问题,然而感冒却没有根治的办法,也不会有!从某种意义上讲,感冒不能算是病,它只是一种正常的生理反应,同时它还能检测你的免疫系统的健康程度呢。同样的道理,DDoS攻击也可以检验你的服务器的抗打能力。
市面上经常见到的针对DDoS的防护手段非常多,你可以花几万甚至几十万去买专用的DDoS清洗设备,也可以不花一分钱任攻击者在暗爽后达到目的或者感到无聊时停止攻击。本文介绍一种中间手段,即一种廉价的DDoS防护机制,你不用花钱,当然也不是要你被动等待,你需要花点精力来熟悉一些技术,然后利用这些技术来主动做一些事情,事实证明,本文介绍的DDoS防护技术的效果非常好。
本文大致分三个部分,第一部分主要介绍nf_conntrack的相关细节,第二部分主要介绍已经存在的SYNPROXY技术,这部分我主要是阐述原理以及在适当的时候讲一些故事,第三部分是我自己的一个设计和实现,旨在针对我觉得SYNPROXY不爽的地方做一些优化,这部分我当然是以见招拆招的方式进行,毕竟,先要找到问题,然后再去优化,不能为了优化而优化。
关于DDoS与nf_conntrack
人人都知道,DDoS防护是性能攸关的,它的目标在于提高在受到海量数据包倾泻式侵袭时的协议栈处理能力,同时,也是几乎人人都知道的是,Netfilter/nf_conntrack会影响协议栈的处理性能,DDoS防护万万不可以使用Netfilter的nf_conntrack机制,因为二者是不相容且相对的。我不知道这样认为的人出于什么心态,但可以肯定的是,这些人大部分都是在道听途说!我们从nf_conntrack的操作入手,看看到底怎么回事。
nf_conntrack的操作是非常典型的,大体上分为了创建,删除,查询,更新这么几类,它们在整个协议栈以及Netfilter框架中的位置如下图所示:
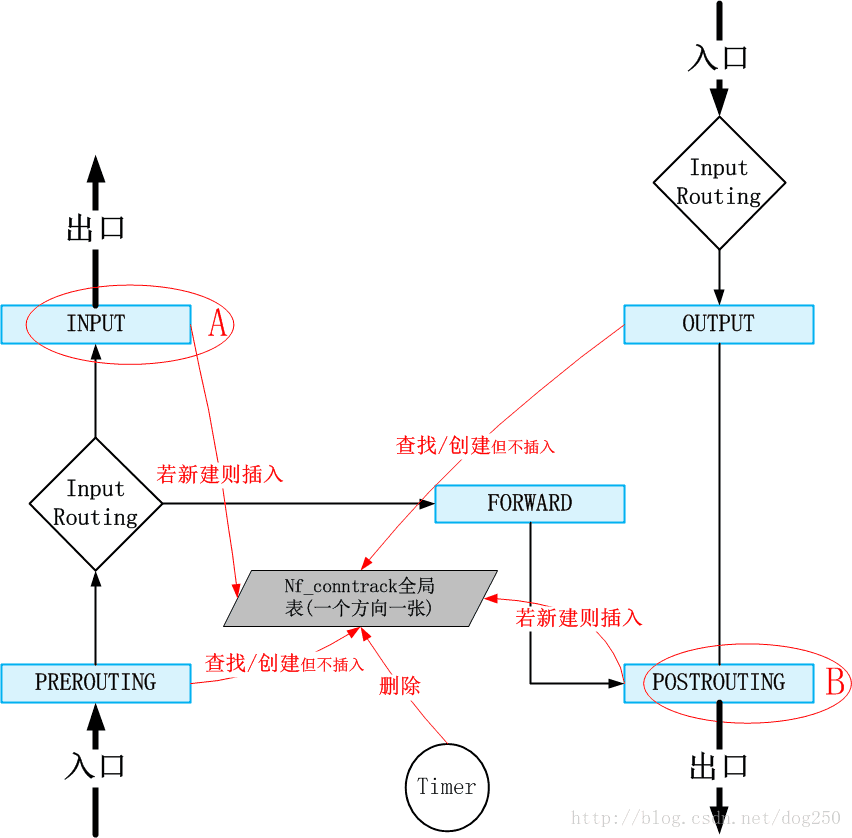
如图可见,我们可以得出以下的结论:
- nf_conntrack使用了全局链表(其实是两张表,一张正向元组表,一张反向元组表)
- nf_conntrack的表项查询是非常高效的,因为它仅采用了Netfilter的RCU锁以及自身引用计数的保护
- nf_conntrack的表项插入,删除是串行化的,因为全局链表只能采用自旋锁保护
这意味着,Netfilter的入口位置,即PREROUTING,OUTPUT两个位置的查询和离线创建操作是十分高效的,而nf_conntrack的性能损耗主要就是在表项的插入和删除,即Netfilter的出口INPUT,POSTROUTING两个位置,这个位置上的插入操作才是罪魁祸首,整个nf_conntrack甚至Netfilter是为这种局部操作背锅的。
我们接下来再来看看nf_conntrack表项的插入和删除与DDoS攻击的关系,就明白为什么大多数人这么抵触使用nf_conntrack来进行DDoS防护了(其实他们不是抵触用nf_conntrack进行DDoS防护,而是根本就是抵触Netfilter本身)。
nf_conntrack机制就是为每一个数据包关联到五元组连接,连接也可以称作流,如果无法关联成功便会为其创建一个表项,这样可以保存一些流的信息,然后将一些针对流的策略使能到单独的数据包上,这些策略包括像是NAT策略,防火墙策略,路由等等。当系统面临DDoS攻击的时候,几乎所有的数据包都是孤立生成的数据包,几乎没有哪些数据包会恰好属于同一个流,这个事实意味着nf_conntrack机制几乎会为每一个攻击数据包都创建一个nf_conntrack表项,如果这些数据包能通过路由,防火墙的检查从而通过协议栈,直达上图中的A点和B点的话,该表项就会被confirm,该插入动作会使用自旋锁锁住整个链表(事实上两个方向上各有一条链表,因此会有两把自旋锁)。
问题来了,这就是问题之所在!
问题就在于,攻击数据包实际上不属于任何流,然而nf_conntrack并不知道这件事,它依然会查询并创建五元组表项,然而这并不算什么(为了单独给nf_conntrack平反正名,我单独为本节写个小附录来简单说下此事),可怕的是最终的表项插入的动作,以及后续无同连接的包到达,在超时后的删除动作,海量且频繁的插入,删除动作会把大量的CPU时间引入到nf_conntrack表的自旋锁上。
这大概就是为什么很多实测表明nf_conntrack加载之后,面对DDoS攻击时性能损失严重的原因了吧。
附:为什么nf_conntrack表项的查找和创建并不算个事儿
如果说nf_conntrack表项查询消耗CPU,那么查路由呢?那么查socket呢?为什么就没有人提及且抱怨呢?
原因之一可能是因为nf_conntrack机制是完全可以不用的,然而路由,socket这种是非查不可的。
其实,如今的CPU硬件配合高效的查询算法已经非常优秀了,只要表项数量控制在一定数量级内,查询消耗的CPU时间永远都是蝇量级的,毕竟在大多数计算机系统中,查询操作是最频繁的操作,优化这类带来的收益非常大,因此它的优化空间也就越来越小了。
查什么不是查,而且通过一些手段(下文会讲)将nf_conntrack表项控制在一定的数量级,同时把路由,socket这种结果一并保存在nf_conntrack表项中,既可以做到DDoS防护,又可以省去路由,socket的查找,岂不是一箭三雕,nf_conntrack非但没有影响性能,还帮你省了两次查询操作呢。
至于说查询未果后的创建动作,更不用多说了,就是几个单独的内存操作,这种操作受惠于CPU缓存系统以及高速的系统总线,早就不是性能瓶颈了。
nf_conntrack如何防御DDoS攻击
既然明白了问题在哪儿,那就见招拆招吧。nf_conntrack不光可以绕开导致性能瓶颈的点,它还能优化整个处理过程哩!
显而易见的措施如下:
措施1:不为不请自来的数据包创建nf_conntrack表项
nf_conntrack机制中有一个特性,该特性是nf_conntrack_tcp_loose系统参数带来的:
nf_conntrack_tcp_loose - BOOLEAN 0 - disabled
not 0 - enabled (default)
If it is set to zero, we disable picking up already established connections.它的意思是,是否仅仅允许为经过TCP三次握手的流创建nf_conntrack表项还是说为任意收到的TCP数据包(有可能是一个构造出来的攻击包)查询未果后均创建新的nf_conntrack表项。
我们只需要将nf_conntrack_tcp_loose设置为0即可:sysctl -w net.netfilter.nf_conntrack_tcp_loose=0这样一来,那些铺天盖地而来的攻击数据包显然是未经三次握手的(这种攻击也叫做ACK攻击),自然而然也就不会为它们创建任何nf_conntrack表项了。既然识别了不关联任何表项的数据包都是恶意的攻击包,那么显然下面的iptables规则将会阻止这类数据包进一步深入协议栈:
iptables -A INPUT -i eth4 -p tcp -m state --state INVALID -j DROP这条规则会将数据包阻止在IP层。因此我们已经有了对抗纯ACK攻击(即发送海量仅携带ACK标识的数据包)的手段。
通过这个措施,便可以避免nf_conntrack为ACK攻击创建,删除不必要的表项,节省大量的CPU时间。措施2:保证只有完成TCP三次握手的才创建nf_conntrack表项
要识别TCP握手过程,我们要对携带SYN标记的数据包特殊对待。
在上一条中,我们通过iptables规则丢弃了INVALID的不请自来的攻击数据包,那么还有一种攻击数据包,它们携带了SYN标记,看样子不是不速之客,而且要来握手建连接的,如果它们中有的完成了三次握手,那么OK,这不是攻击数据包,但如果只是发了了SYN包再无下文了,那么很显然,这就是SYN Flood攻击。问题是如何知道它们能不能完成三次握手呢?
这需要有一种机制可以Hold on整个握手过程,那势必就是Syncookie技术了。
Linux的TCP实现中自带了Syncokkie,然而那是在TCP层做的,我们知道Linux内核的TCP是在锁住Listener的情况下进行Syncookie过程的,这样做的意义明显是为了不为SYN攻击流量分配任何本地内存,而不是为了节省CPU时间的。为了去掉那把锁在Listener头上的那把自旋锁,即不为攻击者浪费本地内存,又不为其浪费CPU时间,就必须要在TCP的下层来完成握手过程的Syncookie处理,有这东西吗?
非常幸运,我们目前有可用的SYNPROXY。这也是本文接下来要详细讲解的。
通过这个措施,便可以避免nf_conntrack为SYN Flood攻击创建,删除不必要的表项,节省大量的CPU时间。措施3:三次握手之后依然查询不到表项的数据包直接丢弃
根据以上的第1点和第2点措施,我们现在可以保证,凡是没有成功关联到nf_conntrack的数据包,均为攻击数据包!果断丢弃这些数据包可以节省巨量的CPU处理时间。第1点措施里的iptables规则可以在SYNPROXY之后来做这件事。
通过这个措施,便可以避免攻击数据包到达上层或者被Forward到其它网段,有效为后面的处理逻辑屏蔽了不必要的内存消耗以及CPU时间的浪费。
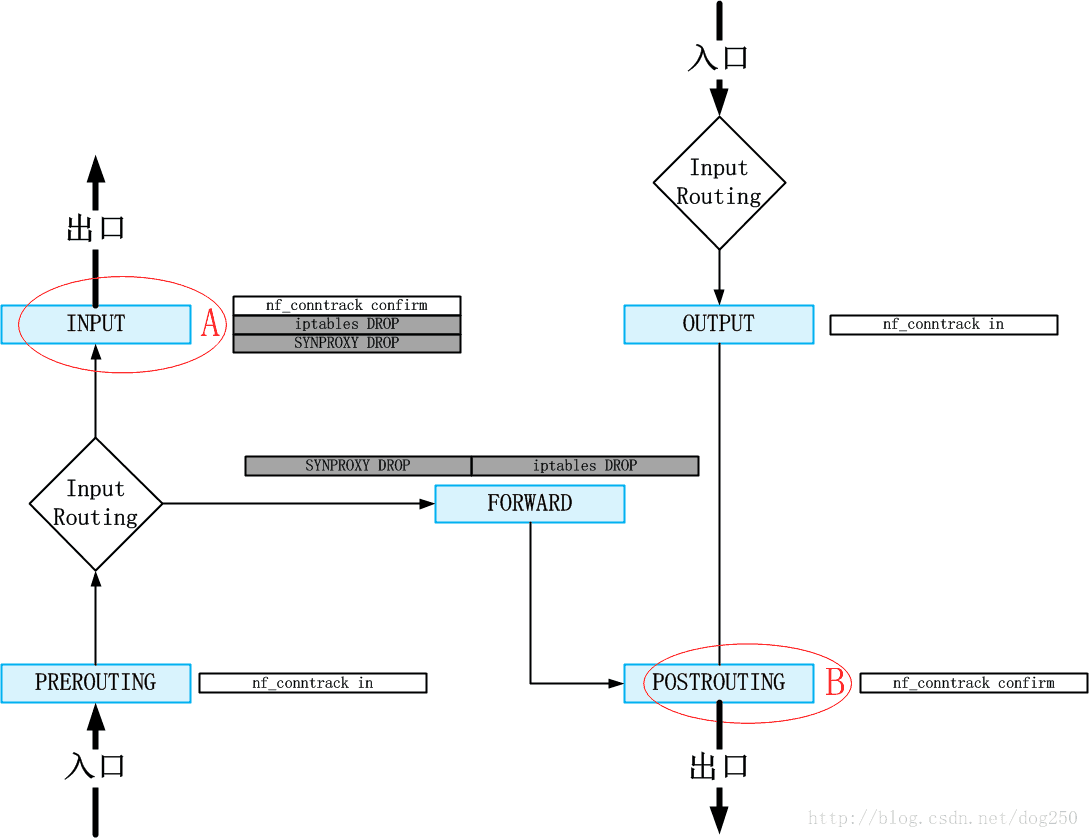
最终,我们要做的事就很简单明了了,总之就是在数据流处理进入上图的A,B瓶颈点之前,将攻击数据包识别并且丢弃:
对于TCP连接建立中(即仍未完成三次握手的流量)的攻击流量,即SYN Flood攻击,交给SYNPROXY来识别并丢弃;
对于其余的攻击流量,比如ACK Flood,则交给iptables来丢弃
这就避开了A,B的瓶颈点。整个逻辑如下图所示:
同时,结合最终SYNPROXY的实现,你会发现,这个整套机制不光是避开了瓶颈点,而且还附带得优化了性能。
有了这个基本的认识,接下来的事情就是如何去实现它了。
我们看到,必要的iptables规则已经构建了整个解决方案的框架,剩下的就是提到的所谓SYNPROXY的细节,这将是本文接下来的内容。
附:什么是INVALID状态的数据包
nf_conntrack会为每一个数据包关联到一种状态,该状态是到达数据包所属协议的状态机决定的,而状态的转换快照则保存在nf_conntrack表项中。如果一个数据包没有关联任何的nf_conntrack表项(且没有被NOTRACK),那么它就是INVALID状态的。
SYNPROXY原理解析
关于SYNPROXY的扫盲文章,请看这一篇:《netfilter: implement netfilter SYN proxy》我这里再给出一个综述。
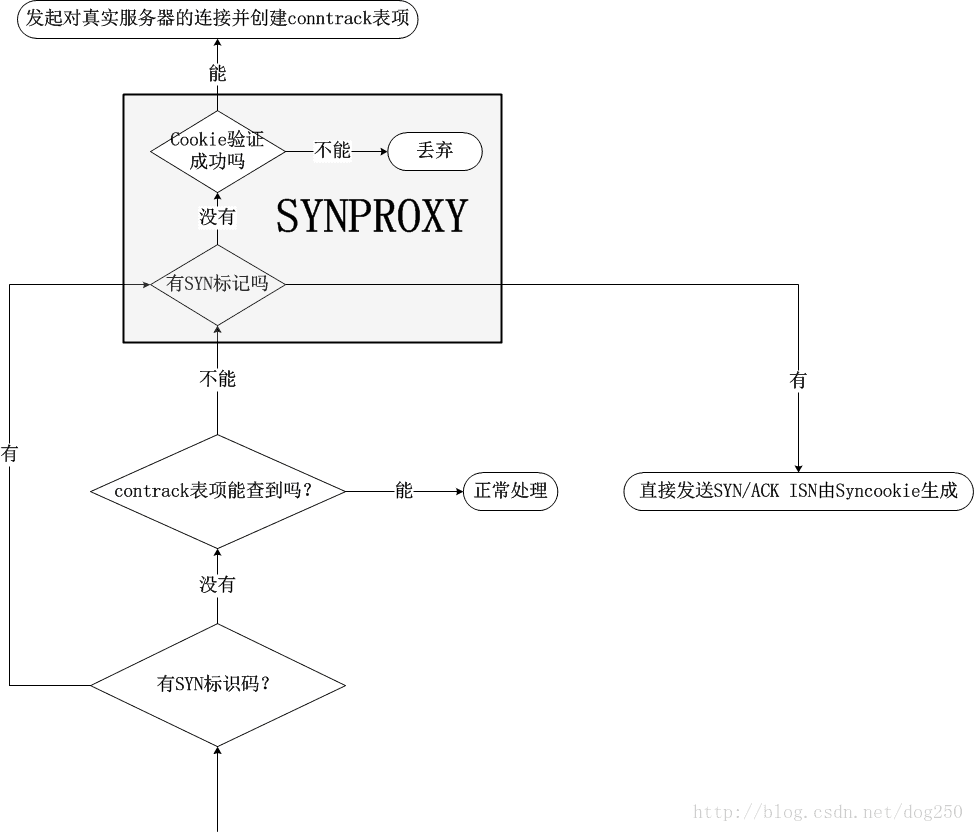
所谓的SYNPROXY顾名思义就是一个TCP握手代理,该代理截获TCP连接建立的请求,它可以保证只有与自己完成整个TCP握手(该握手过程非常轻量级,采用Syncookie机制,且不会touch任何关于socket的逻辑)的连接才被认为是正常的连接,此时才会由代理真正发起与真实服务器的TCP连接。整个流程图如下:

请注意,红色部分是由代理模拟发出的,发起连接请求的客户端并不知道到底发生了什么。这个图几乎就可以诠释SYNPROXY的一切了,在大框架之外,我们请注意两个细节:
关于SYN-ACK的接收窗口
- 第2步中握手代理回复给客户端的SYN-ACK携带的接收窗口大小为0
- 第5步中真实服务器回复给握手代理的SYN-ACK携带的接收窗口要透传给客户端
- 问题1:为什么要这样做?
关于SYN-ACK的ISN(初始序列号)
- 第2步中握手代理回复给客户端的SYN-ACK中的ISN是由握手代理生成的
- 第5步中真实服务器回复给握手代理的SYN-ACK中的ISN是由真实服务器生成的
- 问题2:代理既然要做到透明,一个连接怎么调和两个不同的ISN?
如果能准确回答了上面两个细节带来的两个问题,那么也就知道SYNPROXY哪里有些不妥了,我接下来给出两个问题的答案:
关于0窗口的问题解答
我们注意到,在客户端完成握手之后,实际传输数据之前,握手代理还要与真实服务器进行一次完整的三次握手,如果在此期间客户端发送了数据,无疑这笔数据是要丢弃的(请核对上文的iptables规则,确保你明白数据是如何被丢弃的),为了避免这个情况的发生,代理在SYN-ACK中回复给客户端一个大小为0的接收窗口,表示自己还没有准备好接收数据(毕竟此时仅仅是客户端与握手代理之间完成了三次握手),待到代理与真实服务器完成了三次握手,再把真实服务器在SYN-ACK中携带的接收窗口透传给客户端,表示连接已经完整建立,准备好数据传输了。
关于序列号的问题解答
这个问题比较棘手,两个ISN都是独立生成的,客户端并不知道握手代理的存在,因此客户端会将首先收到的握手代理发送的SYN-ACK记录在TCP连接中,注意在握手代理透传真实服务器的SYN-ACK时,会携带真实服务器生成的另一个ISN,这必然会引起客户端的混乱,因此事实上这个透传的SYN-ACK是不会被正确接收的。那么解决办法也是非常直接,做几件额外的事情:
- 在握手代理收到真实服务器的SYN-ACK时,去掉SYN标记,只保留ACK标记透传,将其仅仅作为一个窗口更新发送到客户端;
- 对于从真实服务器收到的任何数据包,在发送回客户端之前,调整其序列号使之与客户端握手时的ISN相适应;
- 对于从客户端收到的任何数据包,在发送到真实服务器之前,调整其ACK确认号使之与真实服务器握手时收到的ISN相适应。
问题虽然得到了解决,但仔细一看便会发现这么解决问题是不优雅的。首先客户端在刚开始握手时就收到一个0接收窗口,这有点显得…也确实耽误数据发送,其次通过序列号问题的解决,我们发现这个SYNPROXY其实就是一个类似NAT设备一样的中间装置,一旦经由它代理的TCP三次握手,在该TCP连接的整个生命周期内,所有的双向数据传输必然要经过该SYNPROXY进行序列号和ACK确认号的调整,这便增加了遭遇新的性能瓶颈以及单点故障风险的概率。
这不是一个优雅的方案,我的意思是说,SYNPROXY整个来看,不是一个优雅的方案,本着某些原则,它可用,这就够了,在Lwn文章《netfilter: implement netfilter SYN proxy》中的最后一段,作者不也是说了吗:
Unfortunately I couldn’t come up with a nicer way to catch just the first SYN and final ACK from the client and not have any more packets hit the target, but even though it doesn’t look to nice, it works well.
…
不管这样,这就是我自己着手去寻找一个更加优雅的解决方案的切入点。
好了,在接着介绍我自己的Yet another SYNPROXY(后面简称YASynproxy)之前,先来看看原生的SYNPROXY是如何实现的吧。不过我不会去做源码分析,依然还是以流程为主。
SYNPROXY的实现
我采用自上而下逐步深入细节的方式来描述SYNPROXY的实现。
首先,我们先把采用SYNPROXY进行DDoS防御的所有配置全部列出来:
# 不为不请自来(没有经过三次握手)的数据包关联nf_conntrack表项
sysctl -w net.netfilter.nf_conntrack_tcp_loose=0
# 特殊对待携带SYN标记的数据包,由于仅仅收到SYN无法判断是否能最终完成握手,因此不能判断是否最终能关联nf_conntrack表项,故NOTRACK,交由SYNPROXY处理
iptables -t raw -A PREROUTING -i eth4 -p tcp -m tcp --syn --dport 80 -j CT --notrack
# SYNPROXY会过滤出两类感兴趣数据包自己来处理:
# 1.UNTRACKED:携带SYN标记的数据包
# 2.INVALID:未携带SYN标记的数据包(稍后我们会看到,其实这类包就是握手的ACK包或者攻击包)
iptables -A INPUT -i eth4 -p tcp --dport 80 -m state --state UNTRACKED,INVALID -j SYNPROXY --sack-perm --timestamp --wscale 7 --mss 1460
# 丢弃未被SYNPROXY处理的数据包,此数据包为攻击包
iptables -A INPUT -i eth4 -p tcp --dport 80 -m state --state INVALID -j DROP也许你会有疑问,在设置SYNPROXY target的那条iptables规则的注释里,为什么会说INVALID状态的数据包不是握手的ACK包就是攻击包,有这么肯定吗?难道就不会是已经成功建立连接的数据包吗?
这不可能,因为如果成功建立了连接,nf_conntrack表项是一定会被创建的。
这相当于把TCP层Syncookie的理念用在了IP层,在TCP层,正常来讲只要收到SYN包,就会准备一个Request结构体等待后续该客户端完成连接,然而为了防止半连接攻击,Syncookie机制使服务端只有在受到第三次ACK包的时候才会去为该客户端分配创建连接结构体的内存。这理念对于nf_conntrack一样好使,换汤不换药的说法就是,在IP层的SYNPROXY机制中,在仅收到一个SYN包时,不会为其分配并创建nf_conntrack表项,只有在三次握手完成,即收到客户端的针对SYN-ACK的确认ACK后,才会为其分配一个nf_conntrack表项并插入到全局表中。这样一来,该连接后续的数据包到来的时候,就会被成功关联到一个已经创建好的nf_conntrack表项。因此,如果收到了无SYN的ACK包:
- INVALID状态表示无法关联也无法创建nf_conntrack表项,其它状态表示可以关联一个nf_conntrack表项;
- 如果是INVALID状态,Syncookie验证通过,那么它就是握手过程中的ACK包;
- 如果是INVALID状态,Syncookie验证未通过,那么它就是攻击包;
- 如果是ESTABLISHED状态,那么它就是正常的TCP数据包
现在,一个显然的问题就是,SYNPROXY是如何为一个不携带SYN标记的数据包创建一条nf_conntrack表项的,net.netfilter.nf_conntrack_tcp_loose不是已经设置成0从而不允许为不携带SYN标记的数据包创建表项的吗?这不是矛盾了吗??
这就是SYNPROXY实现中最迂回的细节点所在。
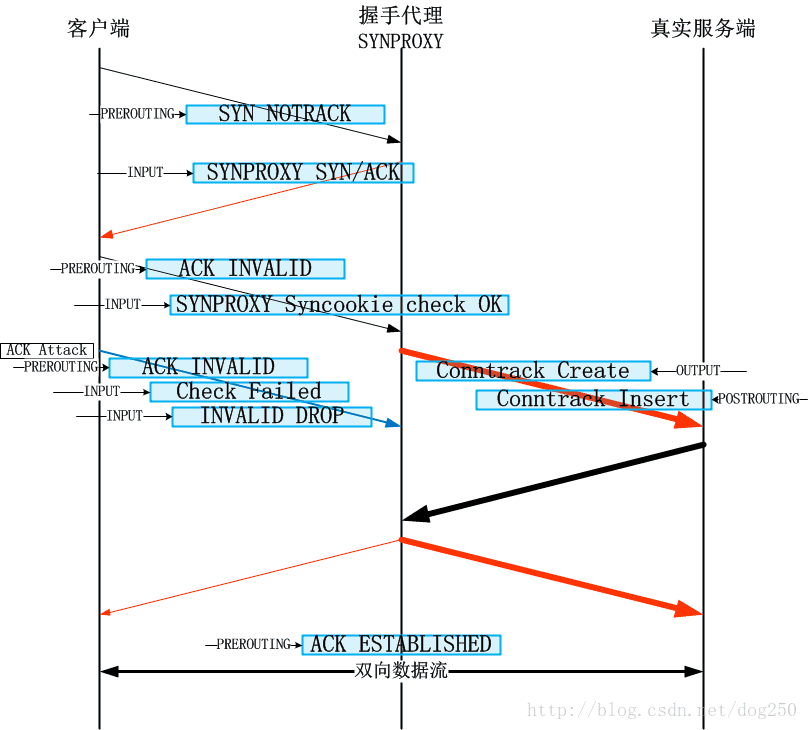
在收到ACK包且Syncookie验证成功后,SYNPROXY会构造一个SYN数据包发往真实的服务器,请注意2个细节:
- 该SYN包完全基于收到的ACK包构造,也就是说它们的五元组是完全相同的,而nf_conntrack表项完全基于五元组为键值;
- 该SYN包通过ip_local_out接口发送出去,过程中必然顺序经过OUTPUT以及POSTROUTING这两个HOOK点;
根据本文最开始的示意图,nf_conntrack机制将会在OUTPUT点创建nf_conntrack表项,在POSTROUTING点confirm表项,将其插入全局链表中。后续的真实服务器发送的SYN-ACK在OUTPUT点查询nf_conntrack全局表的时候,将会成功找到被创建且confirm的一个表项,后面的属于该连接的任何数据包,均会成功关联到这么一个表项:
你(可能也包括几年后的我自己)应该已经理解了SYNPROXY的原理以及实现了,现在是时候展示一下我的YASynproxy了。
Yet another SYNPROXY的优化
之所以会去写这个模块,并不是闲来无事,而是因为有人遇到了类似的问题,我推荐使用SYNPROXY,可是在我部署它的时候,突然想到了一种更加直接的方式,加上我已经将近两年没有再接触这个领域内的技术了,所以就算是练练手吧。
我的方式非常简单,就是省略掉后端的重量级握手,而是直接透传客户端的握手ACK包:
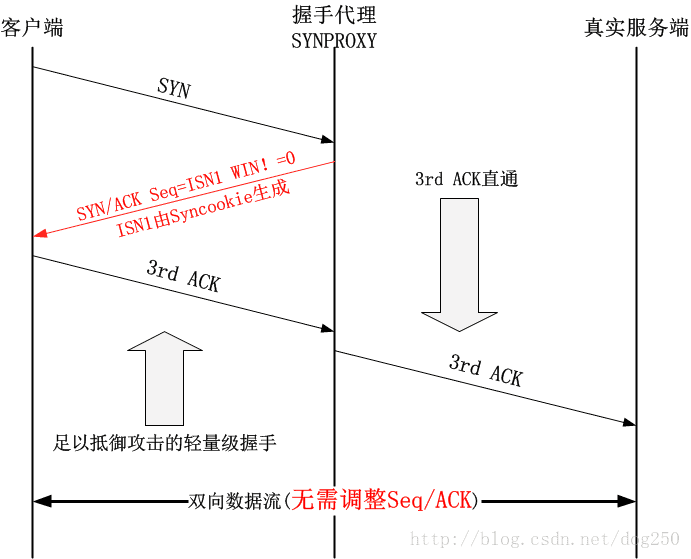
这么做的好处在于:
- 无需经过两次不同的TCP握手过程,一次握手后即可传输数据,省略了0窗口通告的步骤
- 只有一次握手过程,仅仅生成一次SYN/ACK的ISN,代理不再需要再调整序列号和ACK号
- TCP连接在握手完成后就可以不再经过代理了,可以优选更好的路径进行传输
- 暂时还没有想出来,TODO?
也许你会问,TCP层的Listener突然接收到一个ACK(而不是SYN),怎么可能会成功建立连接呢?这是一个好问题。
其实,如果TCP层使能了Syncookie机制,这就是可以的,毕竟TCP层在Syncookie机制下也是这么干的,同样的事换到IP层做没有什么不同,然而,问题是,如果采用了 3rdACK 直通的方案,TCP层必须无条件使用Syncookie来进行握手。然而由于Linux的Syncookie握手并非标准的行为,而是一种触发使能的行为而不是配置使能的机制,所以YASynproxy并非一直都使能的,它需要和系统的Syncookie机制一起使能。至于为什么Syncookie不能成为一种标准的无条件行为,内核文档里关于tcp_syncookies参数的介绍说的很清楚:
Note, that syncookies is fallback facility.
It MUST NOT be used to help highly loaded servers to stand
against legal connection rate. If you see SYN flood warnings
in your logs, but investigation shows that they occur
because of overload with legal connections, you should tune
another parameters until this warning disappear.
See: tcp_max_syn_backlog, tcp_synack_retries, tcp_abort_on_overflow.
syncookies seriously violate TCP protocol, do not allow
to use TCP extensions, can result in serious degradation
of some services (f.e. SMTP relaying), visible not by you,
but your clients and relays, contacting you. While you see
SYN flood warnings in logs not being really flooded, your server
is seriously misconfigured.
虽然说Linux的TCP行为不是一种配置使能的机制,内核还是提供了一个内核参数,即:
net.ipv4.tcp_syncookies = 2然而,即便是如此配置,也不是无条件使能Syncookie机制的,当你把该参数配置成2的时候,在服务器192.168.44.100上使用:
watch -d -n 1 netstat -s来查看,此时在另一台机器上发起一个连接:
telnet 192.168.44.100 80在服务器192.168.44.100这台机器上的结果:
...
TcpExt:
221 SYN cookies sent
35 SYN cookies received
20 invalid SYN cookies received
...会发现这三行关于Syncookie的计数根本没有任何变化,Why?如果这个问题不解决,那么我的方案就是不可用的,因为不可能连什么时候使能Syncookie机制都不知道。
欲探知此事,还是要看代码,反正我是不知道有什么标准化的规定必须这么做。在Linux的TCP代码中,有一个函数调用tcp_synq_no_recent_overflow,当它返回true的时候,就不会采用Syncookie的方式来校验ACK,为了使得它返回false,就必须在一段时间限制内更新该socket的ts_recent_stamp,而只有在TCP采用Syncookie机制生成ISN的时候,才会更新它,也就是说只有TCP曾经生成了Cookie,才会有Cookie验证的机会!
而现实是,Cookie并不是TCP生成的,而是IP层的SYNPROXY生成的,这件事TCP层并不知情,所以一般情况下,ts_recent_stamp都不会被更新,进而tcp_synq_no_recent_overflow会返回true,这就意味着如果凭空来了一个ACK,当它到达TCP层以后,会被丢弃的!
要想绕开这个限制并不难,我知道用jprobe机制可以完成此事:
#include 简单吧!
然而这并不优雅!谁能指望用一个Linux内核调试机制来实现一个标准功能吗?
于是,我有了以下的看法:
- 如果没有受到攻击,即系统的pps没有异常变得巨大,那么就没有必要去抵御DDoS;
只有在真的遭遇了异常pps,才要开启DDoS防御功能。
那么,何以标识遭遇异常pps了呢?很简单,那就是Syncookie开启了呗,何以标识?系统可以监控出现了以下的日志:
Possible SYN flooding on port 80....看到了上面这段,就知道系统遭遇了异常。此时就需要使能YASynproxy了,于是我需要一个condition。好在xtables-addons提供了一个condition match,
于是,可以有以下的策略:当发现系统遭遇异常pps时,就启用YASynproxy
至于如何来发现系统遭遇异常pps,我并不关注,这是另一个范畴了,至少的,我可以监控日志,或者监控SNMP的上报信息来得知。
于是我可以把规则集重构成下面这样:
sysctl -w net.ipv4.tcp_syncookies=2
sysctl -w net.netfilter.nf_conntrack_tcp_loose=0
# 只有在发生了异常的时候才会使能YASynproxy
iptables -t raw -I PREROUTING -i eth4 -m condition --condition anti_ddos -p tcp -m tcp --syn --dport 80 -j CT --notrack
iptables -A INPUT -i eth4 -p tcp --dport 80 -m state --state UNTRACKED,INVALID -j YASynproxy --sack-perm --timestamp --wscale 7 --mss 1460
iptables -A INPUT -i eth4 -p tcp --dport 80 -m state --state INVALID -j DROP只是添加了一个condition match,只要通过监控日志或者SNMP获知了系统在遭受DDoS攻击,那么只需以下这样即可:
echo 1 >/proc/net/nf_condition/anti_ddos这套规则的良性副作用是,即便没有遭遇pps异常,系统也能丢弃掉那些不请自来的数据包。是不是很不错呢?
YASynproxy的实现
说了半天,YASynproxy怎么实现呢?
代码已经放在了github上:https://github.com/marywangran/yet-annother-synproxy (yet-annother-synproxy)
只需要注意以下的细节即可:
- 在确认收到客户端的 3rdACK 的时候立即创建nf_conntrack表项
- 在确认收到客户端的 3rdACK 的时候立即将其透传给真实服务器端
在正文中,我给出以下的代码说明即可:
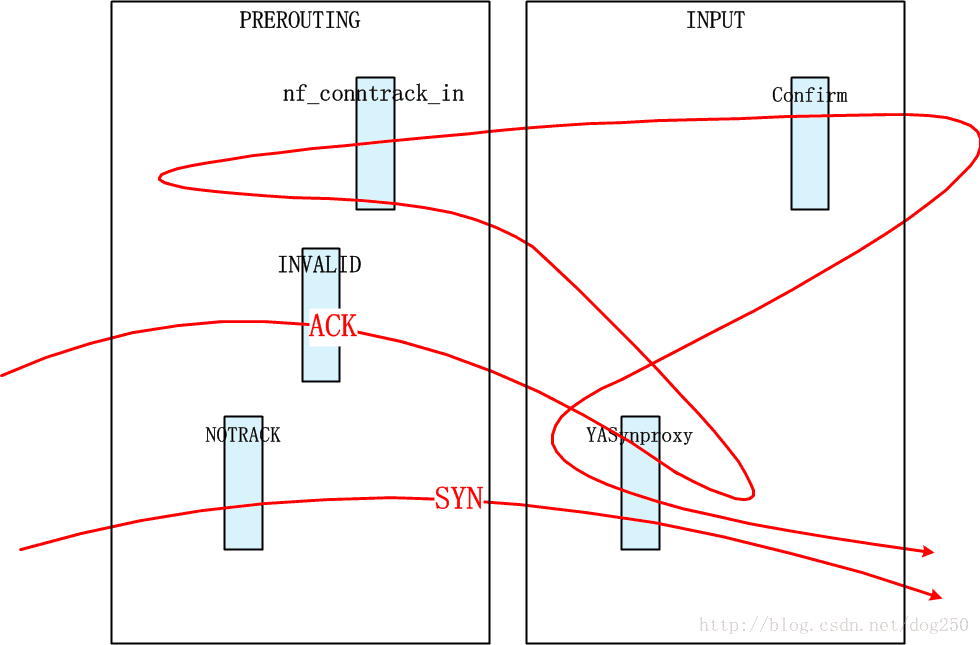
YASynproxy的target函数
static unsigned int synproxy_tg4(struct sk_buff *skb, const struct xt_action_param *par) { const struct xt_synproxy_info *info = par->targinfo; enum ip_conntrack_info ctinfo; struct nf_conn *ct; struct net *net = par->net; struct ip_ct_tcp *state; struct synproxy_net *snet = synproxy_pernet(net); struct synproxy_options opts = {}; struct tcphdr *th, _th; if (nf_ip_checksum(skb, par->hooknum, par->thoff, IPPROTO_TCP)) return NF_DROP; th = skb_header_pointer(skb, par->thoff, sizeof(_th), &_th); if (th == NULL) return NF_DROP; if (!synproxy_parse_options(skb, par->thoff, th, &opts)) return NF_DROP; if (th->syn && !(th->ack || th->fin || th->rst)) { // 对于SYN包,与SYNPROXY逻辑是一样的。 this_cpu_inc(snet->stats->syn_received); if (th->ece && th->cwr) opts.options |= XT_SYNPROXY_OPT_ECN; opts.options &= info->options; if (opts.options & XT_SYNPROXY_OPT_TIMESTAMP) synproxy_init_timestamp_cookie(info, &opts); else opts.options &= ~(XT_SYNPROXY_OPT_WSCALE | XT_SYNPROXY_OPT_SACK_PERM | XT_SYNPROXY_OPT_ECN); // 使用Syncookie机制构造SYN/ACK包 synproxy_send_client_synack(net, skb, th, &opts); return NF_DROP; } else if (th->ack && !(th->fin || th->rst || th->syn)) { int mss, tse; struct tcp_options_received tcp_opt; memset(&tcp_opt, 0, sizeof(tcp_opt)); mss = __cookie_v4_check(ip_hdr(skb), th, ntohl(th->ack_seq) - 1); tcp_parse_options(skb, &tcp_opt, 0, NULL); tse = cookie_timestamp_decode(&tcp_opt); if (mss && tse) { // 如果验证都通过,那么为其加上SYN标志,去掉ACK标记,模拟成SYN包去撸一遍CONNTRACK HOOK,为了创建表项 // 这是因为nf_conntrack_tcp_loose设置为0,不允许不携带SYN标识的包创建conntrack表项 tcp_flag_word(th) |= TCP_FLAG_SYN; tcp_flag_word(th) &= ~TCP_FLAG_ACK; skb->nfct = NULL; // 这个NF_HOOK调用会创建nf_conntrack表项,创建完后即退出NF_HOOK的遍历,退出逻辑在YASynproxy注册的HOOK函数中 NF_HOOK_THRESH(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, NULL, skb, skb->dev, NULL, dummy_return, NF_IP_PRI_CONNTRACK); return XT_CONTINUE; } return NF_DROP; } return XT_CONTINUE; }YASynproxy在PREROUTING的NF_IP_PRI_CONNTRACK之后注册的hook函数
static unsigned int ipv4_synproxy_hook(void *priv, struct sk_buff *skb, const struct nf_hook_state *nhs) { struct net *net = nhs->net; enum ip_conntrack_info ctinfo; struct nf_conn *ct; struct ip_ct_tcp *state; const struct iphdr *iph = ip_hdr(skb); struct tcphdr *th, _th; unsigned int thoff; // 该HOOK注册在nf_conntrack_in执行完之后,即conntrack表项被创建之后用于退出NF_HOOK的处理 ct = nf_ct_get(skb, &ctinfo); // 由于已经为经过三次握手的连接创建了contrack表项,所以它就不再是untracked了 if (ct && !nf_ct_is_untracked(ct) && iph->protocol == IPPROTO_TCP) { thoff = ip_hdrlen(skb); th = skb_header_pointer(skb, thoff, sizeof(_th), &_th); if (th && (th->syn && !(th->ack || th->fin || th->rst))) { unsigned int dataoff; state = &ct->proto.tcp; // 带着刚刚被创建的conntrack表项去confirm!所以这里只需要执行NF_IP_PRI_CONNTRACK_CONFIRM优先级的HOOK即可 NF_HOOK_THRESH(NFPROTO_IPV4, NF_INET_LOCAL_IN, net, NULL, skb, skb->dev, NULL, dummy_return, NF_IP_PRI_CONNTRACK_CONFIRM); // 去掉为了创建conntrack表项而添加的SYN标识,恢复ACK标识 tcp_flag_word(th) &= ~TCP_FLAG_SYN; tcp_flag_word(th) |= TCP_FLAG_ACK; dataoff = skb_network_offset(skb) + (iph->ihl << 2); ct = nf_ct_get(skb, &ctinfo); state = &ct->proto.tcp; // 此时因为已经完成了TCP三次握手,所以需要更新conntrack的状态(否则的话conntrack会是TCP_CONNTRACK_SYN_SENT状态) state->state = TCP_CONNTRACK_ESTABLISHED; state->last_dir = IP_CT_DIR_ORIGINAL; state->last_index = TCP_ACK_SET; state->last_seq = ntohl(th->seq); state->last_ack = ntohl(th->ack_seq);; state->last_end = synproxy_segment_seq_plus_len(ntohl(th->seq), skb->len, dataoff, th); state->last_win = ntohs(th->window); state->retrans = 0; // .... TODO Adjust // 由于握手已经完成,因此设置REPLY标记 if (!test_and_set_bit(IPS_SEEN_REPLY_BIT, &ct->status)) { nf_conntrack_event_cache(IPCT_REPLY, ct); } // 退出NF_HOOK的遍历 return NF_STOP; } } // 非YASynproxy流程处理过的包,正常继续 return NF_ACCEPT; }
运行了上面的代码,在DDoS攻击下的性能确实要比原生的SYNPROXY要好,然则看代码的话,总是觉得哪里有点别扭…
噢…既然只能为携带SYN标识的数据包创建nf_conntrack表项,然而携带SYN标识的数据包却被NOTRACK了…只有完成三次握手后,才能为ACK包创建一个nf_conntrack表项,然而nf_conntrack_tcp_loose的值为0,又不允许…显然,这里只能手工为其创建表项了。
幸亏我对Netfilter的流程非常熟悉,于是很快就想出了上面代码中的逻辑,它的示意图如下:
然而,执行流在Netfilter的HOOK链里绕来绕去很不优雅,如果可以直接调用接口创建这个nf_conntrack表项,且设置正确的状态,这显然才是一种正确的做法。在用户态,系统是提供了这样的接口的,如果你安装了conntrack-tools(不想折腾源码的话,你可以直接apt-get install conntrack,说实话源码安装这个),你就会找到conntrack-tool还是有点费劲的),在执行下面的命令之后:
conntrack -I conntrack -s 3.2.3.4 -d 4.4.4.5 -p tcp --sport 1234 --dport 81 --state ESTABLISHED -u SEEN_REPLY -u ASSURED --timeout 20你在/proc/net/nf_conntrack文件中会发现多了以下一条记录:
ipv4 2 tcp 6 18 ESTABLISHED src=3.2.3.4 dst=4.4.4.5 sport=1234 dport=81 src=4.4.4.5 dst=3.2.3.4 sport=81 dport=1234 [ASSURED] mark=0 zone=0 use=2这条记录就是通过命令行添加的记录,而不是数据包触发添加的记录。可以看到,通过接口添加的记录是自然confirm的,并且可以携带你想设置的任意状态标记。
如果进一步深究,会发现这个命令行实际上是通过Netlink套接字将信息注入内核的,然后内核会创建这条记录。我在想,我能不能直接在YASynproxy的targe里面去调用这个内核接口呢?
非常不幸,不行!我们来看一下这个内核调用的接口函数是什么:
static struct nf_conn *
ctnetlink_create_conntrack(struct net *net,
const struct nf_conntrack_zone *zone,
const struct nlattr * const cda[],
struct nf_conntrack_tuple *otuple,
struct nf_conntrack_tuple *rtuple,
u8 u3);这个函数是无法使用的,它并没有导出到外部…即便它导出到了外部,也必须要构造Netlink消息,而这并不是一件简单且直接的事情,试想,我就是想创建一个conntrack表项而已,干嘛还非得通过Netlink套接字…显然,这个接口并不友好!
于是,我打消了这个直接调用接口的念头,并对温州皮鞋厂老板提了一个需求,那就是实现一个相对友好的此类接口…不管怎样,我觉得我的实现中这种迂回的方式是要比原生SYNPROXY中迂回的方式更加直接的,它的那种迂回直接撸遍了整个Netfilter HOOK点,而我的迂回只是调用完nf_conntrack_in以及nf_conntrack_confirm便退出…
…
还能再做点什么
请参考下面的文章,或者会得到一点想法:
《利用nf_conntrack机制存储路由,省去每包路由查找》
《悲哀!作为服务器,Top 1却是fib_table_lookup》
其实,我想强调的依然是,nf_conntrack绝不是那般糟糕,相反,它很好用!只要你能成功Hold住它,它不但不会给你带来性能损失,还会节省你的CPU时间!
除此之外,让我们深入到一个细节,我们知道Linux内核协议栈中计算Syncookie时使用的算法是SHA1,,这是一种相对较强的摘要算法,一般用在信息安全领域的数据完整性保证领域,因此,SHA1抗碰撞性能非常好(当然,Google攻破SHA1那只是一个新闻,现实中,在大多数场景下,继续使用SHA1看起来并不是特别糟糕)。然而,TCP的序列号并没有如此强的抗碰撞要求!
这并不是说TCP不要求抗碰撞性,TCP当然要求!否则所谓的连接攻击岂不是很容易下手?然而由于TCP是运行在一个时间序列上的,因此说,在MLS(最长报文寿命)之外,实际上TCP的序列号是可以重用的。
因此,和信息安全领域的信息完整性不同,TCP的序列号只需要在MLS量级的时间窗口内抗碰撞就好了,相反,信息安全领域的信息完整性则需要在全时间域内做到抗碰撞,二者相比,TCP序列号的抗碰撞需求就要弱化很多了。
为了满足信息安全领域的数据完整性保证这个需求,对消息数据所做的摘要信息的命名空间就必须足够大,至少要是全世界所有消息的总量这个量级的,对于SHA1而言,它的结果是160bit,即20个字节,这显然已经可以满足需求了,然而对于TCP序列号而言,显然这有点原子弹打蚊子了,在Linux内核中,计算Syncookie时,系统采用了截取SHA1结果的低32bit的方式来作为TCP的初始序列号。显然,前面的 (160−32) bit的数据是没有用的,相当于说,花了很多的CPU时间,计算了那么多没有用的数据!
优化点显然就是,用另外一种算法代替SHA1算法,其实使用一种大家都在用的hash算法即可满足要求了。近水楼台的方案当然就是Linux内核里到处都在使用的jhash算法了。它不会输出没有用的废数据,因为它的输出直接就是u32类型的,这个可以直接作为TCP的初始序列号使用!采用这种方法,将会极大地提高系统协议栈的处理性能!
我为什么把如此重要的优化点放在最后说呢?因为这需要修改内核。即便我在YASynproxy里使用了jhash替代了SHA1,最终数据包还是要直通到系统的协议栈TCP层做check cookie的,而这个check cookie中算法依然是SHA1…除非你把内核也改咯,这并不是一个模块所能简单做到的(当然,采用二进制HOOK的方式完全可以)。
然而,事情又出现了反转!
我可以修改原生的SYNPROXY呀!因为原生的SYNPROXY的TCP Syncookie生成和校验全部是在模块中自己做的哦,这便是我在文中提到的轻量级握手的过程中使用的方法,在轻量级握手过程中,使用被我替换过的jhash算法。而SYNPROXY和真实服务器的握手是一个新的TCP握手过程,即重量级握手,但这个过程中可能也会使用Syncookie,取决于侦听套接字的队列是不是过于满载,如果使用了Syncookie,那么计算和校验Cookie将全部在真实服务器的系统TCP层面完成,算法当然全部采用系统的SHA1咯,此时SYNPROXY扮演的是一个客户端的角色。可见,两次握手采用不同的算法来计算Syncookie并没有任何问题!嗯,没问题,现在就去做!
20分钟后…
OK,事情已经初步做完,github的地址是:https://github.com/marywangran/synproxy-plus
事情彻底做完之前,我先几句话总结下本文。本文中提到的SYNPROXY的思想以及本节上段的替换SHA1,无外乎就两点:
- 消除TCP层面对socket锁的依赖,让握手过程与socket无关;
- 在1的前提下,计算Syncookie时消除对SHA1的依赖,减少不必要的CPU浪费。
为什么没有提到nf_contrack?因为它只是实现上述第1点的一个手段,即在不引入nf_conntrack表项插入,删除的开销的前提下,帮忙实现第1点,减少了实现的难度,仅此而已。
题外话
SYNPROXY的原生支持是从Linux内核3.13开始的,它可以运行,那就好了,仅此而已。但这种风格会给Linux内核带来很多的垃圾!当然,我并没贬损实用主义者的意思,相反,我喜欢这种风格!
SYNPROXY实现的DDoS防御确实非常廉价,在Linux内核里到处都有类似的东西,比如Netfilter本身就是。Linux可以做成一个廉价的防火墙,几乎全依靠Netfilter,围绕Netfilter展开的项目非常丰富,包括SYNPROXY,LVS在内的这些都是Netflter的派生。得益于此,才有了火爆的OpenWRT等,因此周边的TP-LINK,极路由,小米路由….等种种路由才显得如此廉价可靠。
感谢Netfilter!
我不是程序员,然而旋转升降座椅一定会爆炸,温州皮鞋进水会变胖,这说明温州皮鞋是真皮的!