python基础之函数篇
ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符
计算str包含多少个字符,可以用len()函数
>>> len('中文')
2>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6Unicode表示的str通过encode()方法可以编码为指定的bytes
'中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'bytes
。要把
bytes
变为
str
,就需要用
decode()
方法
>>>
b'\xe4\xb8\xad\xe6\x96\x87'
.decode(
'utf-8'
)
'中文'
几种序列比较:1、字符串:有序不可变 2、列表:有序可变 3、元组:有序不可变 4、字典:无序可变(key不可变,值可变)5、集合:无序,可变不可变的集合都有
删除列表指定位置的元素,用pop(i)方法
从raw_input()读取的内容永远以字符串的形式返回,把字符串和整数比较就不会得到期待的结果,须用int()把字符串转换为我们想要的整型
通过in判断key是否存在,二是通过dict提供的get方法
add(key)方法可以添加元素到set中,remove(key)方法可以删除元素
python的内置函数如下

数据类型检查可以用内置函数isinstance实现
if not isinstance(x, (int, float)):
raise TypeError('bad operand type')
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
这样,当我们调用power(5)时,相当于调用power(5, 2):
>>> power(5)
25
>>> power(5, 2)
25
而对于n > 2的其他情况,就必须明确地传入n,比如power(5, 3)
可变参数:可变参数在函数调用时自动组装为一个tuple
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
定义可变参数和定义list或tuple参数相比,仅仅在参数前面加了一个*号
关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw):
print 'name:', name, 'age:', age, 'other:', kw参数组合案例:def func(a, b, c=0, *args, **kw):
print 'a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw>>> func(1, 2, 3, 'a', 'b', x=99)
a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}给定一个list或tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称为迭代(Iteration)
map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回
reduce把一个函数作用在一个序列[x1, x2, x3...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算,其效果就是:
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)用map()、reduce()、lambda()函数实现字符串转换为整数:
def char2num(s):
return {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}[s]
def str2int(s):
return reduce(lambda x,y: x*10+y, map(char2num, s))filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。内置的sorted()函数就可以对list进行排序
内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构
返回闭包时牢记的一点就是:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
如果一定要引用循环变量怎么办?方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变:
匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。本质上,decorator就是一个返回函数的高阶函数
functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64__init__.py
的文件
if __name__=='__main__':
test()
当我们在命令行运行hello模块文件时,Python解释器把一个特殊变量__name__置为__main__,而如果在其他地方导入该hello模块时,if判断将失败,因此,这种if测试可以让一个模块通过命令行运行时执行一些额外的代码,最常见的就是运行测试。
别名
导入模块时,还可以使用别名,这样,可以在运行时根据当前环境选择最合适的模块。比如Python标准库一般会提供StringIO和cStringIO两个库,这两个库的接口和功能是一样的,但是cStringIO是C写的,速度更快,所以,你会经常看到这样的写法:
try:
import cStringIO as StringIO
except ImportError: # 导入失败会捕获到ImportError
import StringIO
这样就可以优先导入cStringIO。如果有些平台不提供cStringIO,还可以降级使用StringIO。导入cStringIO时,用import ... as ...指定了别名StringIO,因此,后续代码引用StringIO即可正常工作。
还有类似simplejson这样的库,在Python 2.6之前是独立的第三方库,从2.6开始内置,所以,会有这样的写法:
try:
import json # python >= 2.6
except ImportError:
import simplejson as json # python <= 2.5
由于Python是动态语言,函数签名一致接口就一样,因此,无论导入哪个模块后续代码都能正常工作。
作用域
在一个模块中,我们可能会定义很多函数和变量,但有的函数和变量我们希望给别人使用,有的函数和变量我们希望仅仅在模块内部使用。在Python中,是通过_前缀来实现的。
正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,x123,PI等;
类似__xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如上面的__author__,__name__就是特殊变量,hello模块定义的文档注释也可以用特殊变量__doc__访问,我们自己的变量一般不要用这种变量名;
类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;
之所以我们说,private函数和变量“不应该”被直接引用,而不是“不能”被直接引用,是因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量。
private函数或变量不应该被别人引用,那它们有什么用呢?请看例子:
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)
我们在模块里公开greeting()函数,而把内部逻辑用private函数隐藏起来了,这样,调用greeting()函数不用关心内部的private函数细节,这也是一种非常有用的代码封装和抽象的方法,即:
外部不需要引用的函数全部定义成private,只有外部需要引用的函数才定义为public。
如果你想在Python 2.7的代码中直接使用Python 3.x的模块功能,可以通过__future__模块的xxx实现:例如除法--->xxx=division
from __future__ import division
__
,在Python中,实例的变量名如果以
__
开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问。双下划线开头的实例变量是不是一定不能从外部访问呢?其实也不是。不能直接访问__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量:
但是如果外部代码要获取name和score怎么办?可以给Student类增加get_name和get_score这样的方法:
def get_name(self):
return self.__nameset_score
方法
def set_score(self, score):
self.__score = score 你也许会问,原先那种直接通过bart.score = 59也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数:
class Student(object):
...
def set_score(self, score):
if 0 <= score <= 100:
self.__score = score
else:
raise ValueError('bad score')__xxx__
的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用
__name__
、
__score__
这样的变量名。
判断一个变量是否是某个类型可以用isinstance()判断:
>>> isinstance(a, list)
Truetype()
函数
>>> type(123)==type(456) type('abc')==types.StringType 能用type()判断的基本类型也可以用isinstance()判断:
如果要获得一个对象的所有属性和方法,可以使用dir()函数,getattr()、setattr()以及hasattr(),我们可以直接操作一个对象的状态
内置了一套try...except...finally...的错误处理机制
try:
print 'try...'
r = 10 / 0
print 'result:', r
except ZeroDivisionError, e:
print 'except:', e
finally:
print 'finally...'
print 'END'
当我们认为某些代码可能会出错时,就可以用try来运行这段代码,如果执行出错,则后续代码不会继续执行,而是直接跳转至错误处理代码,即except语句块,执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
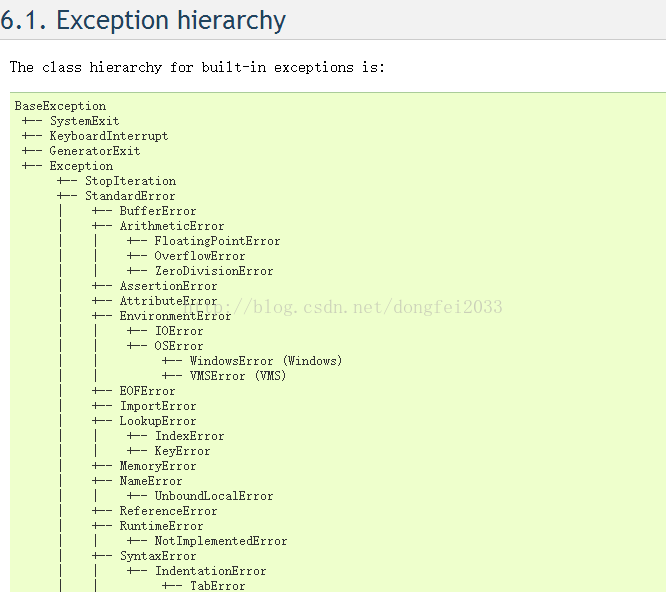

ython内置的logging模块可以非常容易地记录错误信息:
如果要抛出错误,首先根据需要,可以定义一个错误的class,选择好继承关系,然后,用raise语句抛出一个错误的实例:
# err.py
class FooError(StandardError):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s)
return 10 / n调试:print语句、assert语句、logging、启动Python的调试器pdb、pdb.set_trace()、
logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。这样一来,你可以放心地输出不同级别的信息,也不用删除,最后统一控制输出哪个级别的信息。
# err.py
import pdb
s = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print 10 / nPython内置的“文档测试”(doctest)模块可以直接提取注释中的代码并执行测试
ython的os模块封装了操作系统的目录和文件操作,要注意这些函数有的在os模块中,有的在os.path模块中。
>>> os.path.split('/Users/michael/testdir/file.txt')
('/Users/michael/testdir', 'file.txt')>>> os.path.splitext('/path/to/file.txt')
('/path/to/file', '.txt')练习:编写一个search(s)的函数,能在当前目录以及当前目录的所有子目录下查找文件名包含指定字符串的文件,并打印出完整路径:
tips:
# 查看当前目录的绝对路径:
>>> os.path.abspath('.')列出当前目录下的所有目录,只需要一行代码:
>>> [x for x in os.listdir('.') if os.path.isdir(x)]
['.lein', '.local', '.m2', '.npm', '.ssh', '.Trash', '.vim', 'Adlm', 'Applications', 'Desktop', ...]要列出所有的.py文件,也只需一行代码:
>>> [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
['apis.py', 'config.py', 'models.py', 'pymonitor.py', 'test_db.py', 'urls.py', 'wsgiapp.py']
def search(name, path='.'):
found = []
for f in [os.path.abspath(os.path.join(path, x)) for x in os.listdir(path)]:
if os.path.isfile(f) and os.path.split(f)[1].find(name) != -1:
found.append(f)
for path in [x for x in os.listdir(path) if os.path.isdir(x)]:
found.extend(search(name, path))
return found
l = search('2')
print l把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,Python语言特定的序列化模块是pickle,但如果要把序列化搞得更通用、更符合Web标准,就可以使用json模块。