黑马程序员-java基础(六)-集合
------- android培训、java培训、期待与您交流! ----------
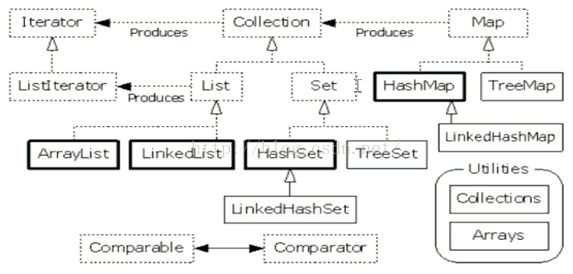
集合
集合类
对象用于封装特有数据,对象多了需要存储;如果对象的个数不确定,就使用集合容器进行存储
数组和集合容器的区别:
集合类特点:数组、集合都是容器可以存储对象,但是数组长度固定,集合长度是可变的,数组还可以存储基本数据类型但是集合只能存储对象
1、只用于存储对象,集合长度是可变的
2、可以用于存储不同类型的对象(每个容器的数据结构不同)
3、集合容器因为内部的数据结构不同,有多种具体容器;不断的向上抽取形成集合框架。
P.S。
集合中存储的不是内容而是地址。
1.Collection接口
Collection 层次结构 中的根接口。Collection 表示一组对象
Collection的常见方法:
1、添加:
boolean add(Object obj);
boolean addAll(Collection coll);
2、删除:
boolean remove(Object obj);
boolean removeAll(Collection coll);
void clear();
3、判断:
boolean contains(Object obj);
boolean containsAll(Collection coll);
boolean isEmpty();判断集合中是否有元素。
boolean retainAll(col2) 仅保留此 collection 中那些也包含在指定 collection 的元素(可选操作)。
import java.util.*;
public class Test {
public static void main(String[] args) {
Collection col1=new ArrayList();
Collection col2=new ArrayList();
col1.add("aa1");
col1.add("aa2");
col2.add("aa3");
col2.add("aa4");
col1.addAll(col2);//把col2中的对象全部添加到col1中
System.out.println("col1--"+col1+" col2--"+col2);
col1.remove("aa1");//移除col1中的一个对象
System.out.println("col1--"+col1+" col2--"+col2);
System.out.println("col1-contains-aa1"+col1.contains("aa1")+"--col1-contains-col2"+col1.containsAll(col2));
System.out.println("col1-retainAll-col2"+col1.retainAll(col2));//计算col1和col2中的交集
System.out.println("col1-retainAll-col2"+col1);
col2.removeAll(col2);//移col2中全部内容
System.out.println("col2-isempity-col2"+col2.isEmpty());
}
}运行结果

迭代器:
Iterator是集合中的封装判断、取出方法的内部类,方便对集合中元素的操作,通过对外开放的iterator()方法创建Iterator对象
Iterator x=集合.iterator();
import java.util.*;
public class Test{
public static void main(String[] args){
Collection coll = new ArrayList();
coll.add( "abc1");
coll.add( "abc2");
coll.add( "abc3");
coll.add( "abc4");
System.out.println(coll);
//使用了Collection中的iterator()方法。调用集合中的迭代器方法,是为了获取集合中的迭代器对象。
Iterator it1 = coll.iterator();
while(it1.hasNext()){//判断是否仍有元素可以迭代
System.out.println(it1.next());
}
System.out.println("------------------------------");
//第二种方法:for循环结束,Iterator变量内存释放,更高效
for(Iterator it2 = coll.iterator();it2.hasNext();){
System.out.println(it2.next());
}
}
}
P.S.
在迭代时,不可以通过集合对象的方法操作集合元素,只能用迭代器的方法操作元素,Iterator 方法有限,只有判断取出、删除操作,其他的操作需通过Listiterator来实现,该接口只能通过List集合的Listiterator方法获取
2.List
Collection
|----List:有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制
|----Set:无序的,一个不包含重复元素的 collection。
List
特有操作方法:(可以操作角标的方法)
增:
add(int index,E element) 在列表的指定位置插入指定元素
addAll(Collection c)
删:
remove(int index)移除列表中指定位置的元素
改:
set(int index,E element) 用指定元素替换列表中指定位置的元素
查:
subList(int fromIndex, int toIndex)
get(int index) 返回列表中指定位置的元素。
import java.util.*;
public class Test{
public static void main(String[] args){
ArrayList al = new ArrayList();
al.add( "java1");
al.add( "java2");
al.add( "java3");
System.out.println("al="+al);//打印集合
al.add(3, "java4");//增
System.out.println("al.add---"+al);//打印集合
al.remove(3);//删
System.out.println("al.remove---"+al);//打印集合
al.set(1, "java");//插
System.out.println("al.set---"+al);//打印集合
System.out.println("al.subList---"+al.subList(1, 2));//包括1不包括2
for(int i=0;i"+al.get(i));
}
System.out.println("--------------------");
for(Iterator i=al.iterator();i.hasNext();){
System.out.println("Iterator获取next:"+i.next());
}
}
} 
listIterator() 返回此列表元素的列表迭代器(按适当顺序)
import java.util.*;
public class Test{
public static void main(String[] args){
ArrayList al = new ArrayList();
al.add( "java1");
al.add( "java2");
al.add( "java3");
Iterator it=al.iterator();
while(it.hasNext()){
Object obj=it.next();
if(obj.equals("java2"))
al.add("java");
System.out.println(obj);
}
}
}
P.S.
在Iterator迭代器过程中,使用集合元素操作方法,产生安全隐患,抛出并发访问异常,解决方法是只使用一种操作方式
但是,Iterator 方法有限,只有判断取出、删除操作,其他的操作需通过Listiterator(扩展了其他的迭加器操作方法)来实现,该接口只能通过List集合的Listiterator方法获取
listIterator():列表迭代器,Iterator的子接口(功能进行了扩展)
import java.util.*;
public class Test{
public static void main(String[] args){
ArrayList al = new ArrayList();
al.add( "java1");
al.add( "java2");
al.add( "java3");
ListIterator it=al.listIterator();
System.out.println(al);
while(it.hasNext()){
Object obj=it.next();
if(obj.equals("java2")){
it.set("java22");
it.add("java");}
System.out.println(obj);
}
System.out.println(al);
}
}
List:
|----ArrayList: 底层的数据结构是---数组结构, 特点:有角标查询快,修改删除慢,线程不同步
|----LinkedList:底层的数据结构是---列表数据结构,特点:增、删速度快,查询慢。
removeFirst()移除并返回此列表的第一个元素(NoSuchElementException- 如果此列表 为 空)pollFirst()获取并移除此列表的第一个元素(如果此列表为空,则返回null)|----Vector:底层是数组数据结构,线程是同步的。枚举(Enumeration)是Vector的特有取出方式,和迭加器用法一样
Vector中有一个特有的取出方式:枚举Enumeration
import java.util.*;
public class Test{
public static void main(String[] args){
Vector v = new Vector();
v.add( "java1");
v.add( "java2");
v.add( "java3");
System.out.println(v);
Enumeration en=v.elements();//Vector特有的取出方法枚举
while(en.hasMoreElements()){
System.out.println("MORE:"+en.nextElement());
}
ListIterator it=v.listIterator();
while(it.hasNext()){
System.out.println("NEXT:"+it.next());
}
}
}

LinkedList特有方法:
addFirst();
addLast();
--------------------------------------------------------
getFirst();//获取但不移除,如果链表为空,抛出NoSuchElementException。
getLast();
jdk1.6版本后新方法:
peekFirst();//获取但不移除,如果链表为空,返回null。
peekLast();
--------------------------------------------------------
removeFirst();//获取并移除,如果链表为空,抛出NoSuchElementException。
removeLast();
jdk1.6版本后新方法:
pollFirst();//获取并移除,如果链表为空,返回null;
pollLast();
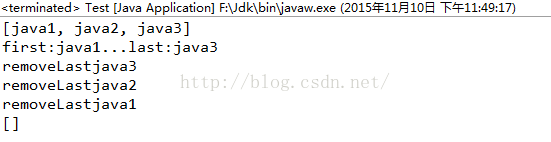
import java.util.*;
public class Test{
public static void main(String[] args){
LinkedList link = new LinkedList();
link.add( "java1");
link.add( "java2");
link.add( "java3");
System.out.println(link);
System.out.println("first:"+link.getFirst()+"...last:"+link.getLast());//获取列表第一、最后一个元素
while(!link.isEmpty()){
System.out.println("removeLast"+link.removeLast()); //获取并移除列表中的最后一个元素
}
System.out.println(link);
}
}
【例】利用LinkedList模拟一个堆栈(先进后出)或者队列数据结构(先进先出)
class DuiLie{//先进先出
private LinkedList link;
DuiLie(){//初始化时创建一个LinkedList对象
link=new LinkedList();
}
public void myAdd(Object obj){//自定义添加元素方法
link.addFirst(obj);
}
public Object myGet(){//自定一获取元素方法
return(link.removeLast());
}
public Boolean isNull(){//自定义判断集合是否为空
return(link.isEmpty());
}
}
class DuiZhan{//堆栈:先进后出
private LinkedList link;
DuiZhan(){//初始化时创建一个LinkedList对象
link=new LinkedList();
}
public void myAdd(Object obj){//自定义添加元素方法
link.addFirst(obj);
}
public Object myGet(){//自定一获取元素方法
return(link.removeFirst());
}
public Boolean isNull(){//自定义判断集合是否为空
return(link.isEmpty());
}
}
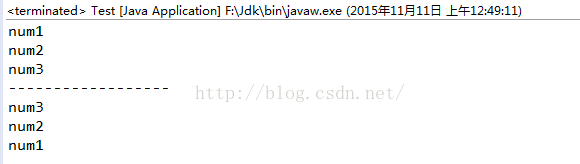
public class Test{
public static void main(String[] args){
DuiLie dl=new DuiLie();
dl.myAdd("num1");
dl.myAdd("num2");
dl.myAdd("num3");
while(!dl.isNull()){
System.out.println(dl.myGet());
}
System.out.println("------------------");
DuiZhan dz=new DuiZhan();
dz.myAdd("num1");
dz.myAdd("num2");
dz.myAdd("num3");
while(!dz.isNull()){
System.out.println(dz.myGet());
}
}
}
3.Set
Set:元素是无序的(存入和取出的顺序不一定一致),元素不可以重复,集合无索引(Set接口中的方法和Collection接口中的方法一样)
|----HashSet:底层数据结构是哈希表,是不同步的。
HashSet 通过元素的两个方法,hashiCode和equals来完成,如果元素的HashCode值相同,才会判断equals是否为ture。
|----TreeSet:可以对Set集合中的元素排序,是不同步的。
HashSet:
保证数据的唯一性:通过元素的两个方法,hashiCode和equals来完成,如果元素的HashCode值相同,才会判断equals是否为ture。(集合底层自动调用这两个方法,因此定义对象是需要根据需求覆写这两个方法)
【例】往HashSet集合中存储Person对象。如果姓名和年龄相同,视为同一个人,视为相同元素
import java.util.*;
class Person{
private String name;
private int age;
Person(String name,int age){//初始化对象
this.name=name;
this.age=age;
}
public String getName(){
return(this.name);
}
public int getAge(){
return(this.age);
}
//根类Object中有hashCode和equals方法,hashSet集合底层自动调用这两个方法
public int hashCode(){//覆盖hashCode()方法,定义对像的哈希值
System.out.println(name+":hashCode...");
return(name.hashCode()+age*age);//保证每个对象哈希值的唯一性
}
public boolean equals(Object obj){//覆盖equals(object obj)方法,自定义判断内容相等的方法
Person p=(Person) obj;
System.out.println(this.name+"...equal..."+p.name);
return this.name==p.name && this.age==p.age;
}
}
public class Test{
public static void main(String[] args){
HashSet hs=new HashSet();
hs.add(new Person("p1",20));
hs.add(new Person("p2",22));
hs.add(new Person("p3",24));
hs.add(new Person("p2",22));
Iterator it=hs.iterator();
while(it.hasNext()){
Person p=(Person)it.next();
System.out.println(p.getName()+" "+p.getAge());
}
}
}
P.S.
对于判断元素是否存在,ArrayList只依赖于equals(),而HashSet依赖与hashCode()和equals()
运行结果import java.util.*; class Person{ private String name; private int age; Person(String name,int age){//初始化对象 this.name=name; this.age=age; } public String getName(){ return(this.name); } public int getAge(){ return(this.age); } //根类Object中有hashCode和equals方法,hashSet集合底层自动调用这两个方法 public int hashCode(){//覆盖hashCode()方法,定义对像的哈希值 System.out.println(name+":hashCode..."); return(name.hashCode()+age*age);//保证每个对象哈希值的唯一性 } public boolean equals(Object obj){//覆盖equals(object obj)方法,自定义判断内容相等的方法 Person p=(Person) obj; System.out.println(this.name+"...equal..."+p.name); return this.name==p.name && this.age==p.age; } } public class Test{ public static void main(String[] args){ ArrayList al = new ArrayList(); al.add(new Person("p1",20)); al.add(new Person("p2",22)); al.add(new Person("p3",24)); al.add(new Person("p2",22)); System.out.println(al); System.out.println(al.remove(new Person(("p2"),22)));//remove底层依赖的是requals()方法 System.out.println(al); System.out.println(al.contains(new Person(("p1"),20)));//contains底层依赖的是requals()方法 } }

LinkHashSet:无序变有序,具有可预知迭代顺序的Set 接口的哈希表和链接列表实现。
import java.util.HashSet;
import java.util.Iterator;
import java.util.LinkedHashSet;
public class LinkedHashSetDemo{
public static void main(String[] args){
HashSet hs = new LinkedHashSet();
hs.add( "p1");
hs.add( "p2");
hs.add( "p3");
hs.add( "p4");
Iterator it = hs.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}

TreeSet
根据比较方法的返回结果进行排序,负整数、零或正整数,根据此对象是小于、等于还是大于指定对象。且通过TreeSet底层数据结构是二叉树(小的往左边存放,大的往右边存放,减少比较性)比较方法的返回结果是否是0,是0,就是相同元素,不存来保证数据的唯一性。
P.S.
TreeSet:底层数据结构是二叉树(小的往左边存放,大的往右边存放,减少比较性)
TreeSet:保证数据唯一性的依据是,CompareTo 方法中return 0
自定义数据排列方式一:
让元素(对象)自身具备比较性
a、对象所属的类实现comparable(强制对象比较性)接口
b、覆盖该接口中的int compareTo(Object)方法
/*
* 根据年龄对人进行排序,年龄相同则根据姓名排序存储在TreeSet集合中
* */
import java.util.*;
//tep1:TreeSet中的对象类实现Comparable接口
class Person implements Comparable
{
private String name;
private int age;
Person(String name,int age){//初始化对象
this.name=name;
this.age=age;
}
public String getName(){
return(this.name);
}
public int getAge(){
return(this.age);
}
//tep2:实现Comparable接口中的compareTo()方法,自定义对象比较性,集合底层调用
public int compareTo(Object obj){
if(!(obj instanceof Person))//判断是否为学生对象
throw new RuntimeException("不是学生对像");
Person p=(Person)obj;
System.out.println(this.getName()+"..compare.."+p.getName());
if(this.age>p.age)//根据年龄比较
return 1;
else if(this.age==p.age){//年龄相同则根据姓名比较
return this.name.compareTo(p.getName());//String类自定义了compareTo方法
}
return -1;
}
}
public class Test{
public static void main(String[] args){
TreeSet ts = new TreeSet ();
ts.add(new Person("p1",20));
ts.add(new Person("p3",24));
ts.add(new Person("p2",22));
ts.add(new Person("p3",22));
for(Iterator it=ts.iterator();it.hasNext();){
Person p=(Person)it.next();
System.out.println(p.getName()+" "+p.getAge());
}
}
}
自定义数据排列方式二:
让集合自身具备比较性
a、让集合自身具备比较功能,定义一个类实现Comparator接口,覆盖compare方法。
b、将该类对象作为参数传递给TreeSet集合的构造函数。TreeSet(Comparator comparator) 构造一个新的空 TreeSet,它根据指定比较器进行排序
/*根据方法一的程序,进行扩展
* 根据姓名对人进行排序,姓名相同则根据年龄排序存储在TreeSet集合中
* */
import java.util.*;
//方法一:让元素自身具备比较性。tep1:TreeSet中的对象类实现Comparable接口
class Person implements Comparable
{
private String name;
private int age;
Person(String name,int age){//初始化对象
this.name=name;
this.age=age;
}
public String getName(){
return(this.name);
}
public int getAge(){
return(this.age);
}
//方法一:让元素自身具备比较性。tep2:实现Comparable接口中的compareTo()方法,自定义对象比较性,集合底层调用
public int compareTo(Object obj){
if(!(obj instanceof Person))//判断是否为学生对象
throw new RuntimeException("不是学生对像");
Person p=(Person)obj;
System.out.println(this.getName()+"..compare.."+p.getName());
if(this.age>p.age)//根据年龄比较
return 1;
else if(this.age==p.age){//年龄相同则根据姓名比较
return this.name.compareTo(p.getName());//String类自定义了compareTo方法
}
return -1;
}
}
//方法二:让集合自身具备比较性。Tep1:定义一个类实现Comparator,覆盖compare方法。
class MyCompare implements Comparator{
public int compare(Object o1,Object o2){
Person s1=(Person)o1;
Person s2=(Person)o2;
int num=s1.getName().compareTo(s2.getName());
if(num==0)
//将年龄封装成Integer对象,用该类中的compareTo方法进行比较
return new Integer(s1.getAge()).compareTo(new Integer(s2.getAge())) ;
return num;
}
}
public class Test{
public static void main(String[] args){
//方法二:让集合自身具备比较性。Tep2将该类对象作为参数传递给TreeSet集合的构造函数
TreeSet ts = new TreeSet (new MyCompare());
ts.add(new Person("p1",20));
ts.add(new Person("p3",24));
ts.add(new Person("p2",22));
ts.add(new Person("p3",22));
for(Iterator it=ts.iterator();it.hasNext();){
Person p=(Person)it.next();
System.out.println(p.getName()+" "+p.getAge());
}
}
}
P.s.
两种排序同时存在,以比较器为主

【例】对字符串进行长度排序。(应用方法二)
import java.util.*;
class MyCompare implements Comparator{
public int compare(Object o1,Object o2){
String s1=(String)o1;
String s2=(String)o2;
int num=new Integer(s1.length()).compareTo(new Integer(s2.length()));
if(num==0)
return s1.compareTo(s2);
return num;
}
}
public class Test{
public static void main(String[] args){
TreeSet ts = new TreeSet (new MyCompare());
ts.add("abcd");
ts.add("cc");
ts.add("aba");
ts.add("ab1");
for(Iterator it=ts.iterator();it.hasNext();){
System.out.println(it.next());
}
}
}
4.泛型
泛型:安全机制(在定义集合时就制定集合存储的类型,类似于数组中的 int[] a=new int[];)
格式:ArryList<String> al=new ArryList
P.S.
java中各符号的应用
{程序 结构}(参数)[数组] <泛型>
好处:将运行时期出现ClassCastException转移到编译期;避免了强制转换
泛型类:当类中要操作的引用数据类型不确定时,早期定义Object来完成扩展,现在定义泛型完成扩展
class Tool
{
private Q q;
public void setObject
{
this.q=q
}
public Q getObject()
{
returen q
}
}
泛型类定义的泛型:在整个类中有效,如果被方法使用,那么泛型类的对象要明确操作类型,所有操作的类型就固定了。
class Demo//所有的操作类型都固定
{
public void show(T t)
{
System.out.println("show:"+t)
}
public void print(T t)
{
System.out.println("print:"+t)
}} 泛型方法定义的泛型:在方法上可以让不同方法操作不同类型
class Demo
{
public void show(T t)//操作T类型
{
System.out.println("show:"+t)
}
public void print(Q q)//操作Q类型
{
System.out.println("print:"+q)
}}
p.s.静态方法不可以访问类上定义的泛型,如果静态操作的引用类型不确定,可以将泛型定义在方法上public staticvoid method(W w){}(因为静态是优先于对象加载)
泛型限定:
1、通配符:?---定义不确定泛型
2、泛型上限定:?extends E---可以接受E及E的子类
3、泛型下限定:?super E----可以接收E及E的父类
class Demo{}
class Demo{}
class Demo{}5.Map
Map
*----Hashitable:底层是hash表数据结构,不可以存入null键null值,该集合是线程同步
*----HashMap:底层是hash表数据结构,可以存入null键null值,该集合是线程不同步
*----TreeMap:底层是二叉树数据结构,线程不同步,可以用于给Map集合中的键排序
常用方法:
import java.util.*;
public class Test{
public static void main(String[] args){
Map m=new HashMap();
System.out.println("put:"+m.put(12, "王二"));//put()返回前一个和key关联的值,如果没有返回null。
m.put(16, "李四");
m.put(12, "张三");//新的键值对会覆盖旧的键值对
m.put(11, "刘六");
System.out.println(m);
System.out.println("contains11Key:"+m.containsKey(11));
System.out.println("contains刘六value:"+m.containsValue("刘六"));
System.out.println("empty:"+m.isEmpty());
System.out.println("get:"+m.get(16));//没有则返回null
System.out.println("remove:"+m.remove(11));//remove()返回之前key关联的值,如果没有返回null。
System.out.println("size:"+m.size());//没有则返回null
}
} 
Map集合的两种取出方式:
方式一:
set 返回此映射中所包含的键的Set 视图(Set具备迭代器),所以可以用迭代方式取出所有的键,再根据get方法获取每个键对应的值。原理:将map集合转成set集合,再通过迭代器取出
/*
* Map集合的取出方式一:
* */
import java.util.*;
public class Test{
public static void main(String[] args){
Map m=new HashMap();
m.put(16, "李四");
m.put(12, "张三");
m.put(11, "刘六");
Set s=m.keySet();//keySet() 返回此映射中所包含的键的Set 视图(Set具备迭代器)
Iterator it=s.iterator();//获取set集合的迭代器
while(it.hasNext()){
Integer key=it.next();//取出键
String volue=m.get(key);//获取键对应的值
System.out.println(key+"="+volue);
}
}
} Set返回此映射所包含的映射关系的 Set 视图,map.Entry类型,再通过map.Entry中的getkey和getvalue方法取出键和值
/*
* Map集合的取出方式二:
* */
import java.util.*;
public class Test{
public static void main(String[] args){
Map m=new HashMap();
m.put(16, "李四");
m.put(12, "张三");
m.put(11, "刘六");
//Set> entrySet()返回此映射所包含的映射关系的 Set 视图。
//Map.Entry为数据类型,映射项(键-值对)。Set集合中存放的是Map.Entry对象
Set> s=m.entrySet();
//创建set集合的迭代器
Iterator> it=s.iterator();
while (it.hasNext()){
Map.Entry me=it.next();
Integer key=me.getKey();//通过map.Entry中方法来获取键、值
String value=me.getValue();
System.out.println(key+"="+value);
}
}
}
HashMap应用举例
/*
定义学生 和地址的一一对应,姓名和年龄相同的视为同一个学生
1.创建学生类
2.定义HashMap集合,将学生作为键、地址作为值
3.获取Map中的元素
*/
import java.util.*;
class Student implements Comparable{
private String name;
private int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public String getName(){
return this.name;
}
public int getAge(){
return this.age;
}
public int compareTo(Student s){
int num=this.name.compareTo(s.getName());
if(num==0)
num=(new Integer(this.getAge())).compareTo(new Integer(s.getAge()));
return num;
}
public int hashCode(){
return name.hashCode()+age*30;
}
public boolean equals(Object obj){
if(!(obj instanceof Student))
throw new RuntimeException("类型不匹配");
Student s=(Student)obj;
return this.name.equals(s.getName())&&this.age==s.age;
}
}
public class Test{
public static void main(String[] args){
HashMap hm=new HashMap();
hm.put(new Student("p2",18), "beijing");
hm.put(new Student("p4",19), "nanjing");
hm.put(new Student("p1",20), "shenzhen");
hm.put(new Student("p1",20), "shanghai");
Set> entry=hm.entrySet();
Iterator> it=entry.iterator();
while(it.hasNext()){
Map.Entry map=it.next();
Student s=map.getKey();
String add=map.getValue();
System.out.println(s.getName()+".."+s.getAge()+":"+add);
}
}
} 
TreeMap对键自定义排序应用举例
p.s.
TreeMap(Comparator comparator)
构造一个新的、空的树映射,该映射根据给定比较器进行排序。
/*
定义学生 和地址的一一对应,姓名和年龄相同的视为同一个学生,根据年龄进行排序
1.创建学生类
2.定义TreeMap集合(将自定义的比较器作为参数传入),将学生作为键、地址作为值
3.获取Map中的元素
*/
import java.util.*;
class Student implements Comparable{
private String name;
private int age;
Student(String name,int age){
this.name=name;
this.age=age;
}
public String getName(){
return this.name;
}
public int getAge(){
return this.age;
}
public int compareTo(Student s){
int num=this.name.compareTo(s.getName());
if(num==0)
num=(new Integer(this.getAge())).compareTo(new Integer(s.getAge()));
return num;
}
public int hashCode(){
return name.hashCode()+age*30;
}
public boolean equals(Object obj){
if(!(obj instanceof Student))
throw new RuntimeException("类型不匹配");
Student s=(Student)obj;
return this.name.equals(s.getName())&&this.age==s.age;
}
}
public class Test{
public static void main(String[] args){
TreeMap hm=new TreeMap(new MyCompare());
hm.put(new Student("p2",18), "beijing");
hm.put(new Student("p4",19), "nanjing");
hm.put(new Student("p1",20), "shenzhen");
hm.put(new Student("p1",20), "shanghai");
Set> entry=hm.entrySet();
Iterator> it=entry.iterator();
while(it.hasNext()){
Map.Entry map=it.next();
Student s=map.getKey();
String add=map.getValue();
System.out.println(s.getName()+".."+s.getAge()+":"+add);
}
}
}
class MyCompare implements Comparator{
public int compare(Student s1,Student s2){
int num=(new Integer(s1.getAge())).compareTo(new Integer(s2.getAge()));
if (num==0)
num=s1.getName().compareTo(s2.getName());
return num;
}
}

【获取字符串中字符的个数】
/*
获取字符串“adsfghadhg”中字符出现的次数
思路:将字符串转换成字符数组,挨个取出字符,然后对应将字符及其个数以键值对的形式存入Map集合中
1.将字符串转换成字符数组
2.创建map集合
3,字符是否在集合中存在,不存在则对应Value=1,存在则对应Value加1
4.打印集合
*/
import java.util.*;
import javax.swing.plaf.basic.BasicComboBoxUI.ItemHandler;
public class Test{
public static void main(String[] args){
TreeMap ts=new TreeMap();
String s="adsfghadhg";
//char[] toCharArray() 将此字符串转换为一个新的字符数组。
char[] C=s.toCharArray();
int num=0;
for(int i=0;i st=ts.keySet();
Iterator it =st.iterator();
while(it.hasNext()){
Character key=it.next();
Integer value=ts.get(key);
sb.append(key+"("+value+")");
}
System.out.println(sb.toString());
}
} 