kaldi中文语音识别_基于thchs30(1)
kaldi是语音识别的开源软件包,网址http://www.kaldi-asr.org/
Kaldi's code lives at https://github.com/kaldi-asr/kaldi. To checkout (i.e. clone in the git terminology) the most recent changes, you can use this command git clone https://github.com/kaldi-asr/kaldi or follow the github link and click "Download in zip" on the github page (right hand side of the web page)
它的代码在这个网址,并且支持git 下载,所以我们先要下载它的代码工程。
然后我们还需要下载中文语音数据库thchs30,网址是http://www.openslr.org/18/
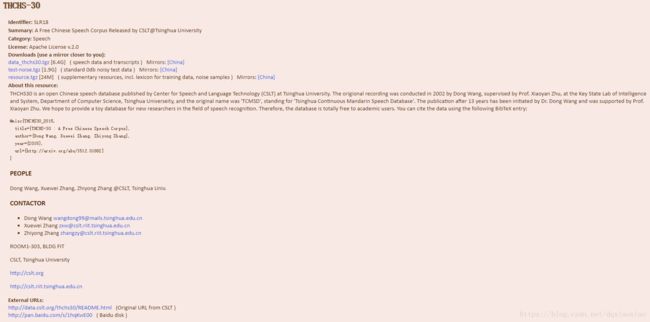
进去以后我们看到,有data_thchs30.tgz resource.tgz test-noise.tgz 这三个语音文件压缩包链接地址,在最下面还有百度网盘的链接,我是下载的三个语音压缩包的链接地址的那个。
首先,thchs30有两种数据库,kaldi运行的数据库最好是 thchs30-openslr。
这里我们下载kaldi的代码工程之后我们看一下cmd.sh脚本,这个脚本在egs/thchs30/s5下
这里的解释是s5中的cmd.sh中的英文解释:
如果您没有排队系统,并且希望在本地机器上运行,您可以更改所有'queue.pl' 为 run.pl,(但是要小心,一个一个地运行该命令:大多数的方法会耗尽你机器上的内存)。
也就是说如果你要用run.pl的话你应该一步一步的运行这些脚本,因为可能消耗掉你机器的内存,建议用脚本注释的方式一步一步来。
这里的queue.pl为kaldi调用的gridengine,是一种多cpu(gpu)的一种并行处理的方案。如果你只有一台计算机,这个恐怕完成不了,这个即使gridengine安装成功,但是一般也会报错,所以一般我们就用run.pl。
如果是slurm其他并行任务分发软件配合,则是slurm.pl。
也就是说不同的并行处理方案要调用不同的脚本,
为了描述这些差异,您可以创建和编辑文件conf/queue.conf以匹配您的配置。
寻找关于conf/queue.conf 在http://kaldi-asr.org/doc/queue.html中获取更多信息,或者在utils/queue.pl 或者utils/slurm.pl中搜索字
符串的'default_config' 。这里也就是说queue.pl在utils下
关于Kaldi的并行任务转载人家的一片文章 https://blog.csdn.net/dqxiaoxiao/article/details/80250809
我们来看run.pl的解释,它也在utils下
未完待续。。。。。。