单一数字评估指标:
我们在平时常用到的模型评估指标是精度(accuracy)和错误率(error rate),错误率是:分类错误的样本数站样本总数的比例,即E=n/m(如果在m个样本中有n个样本分类错误),那么1-a/m就是精度。除此之外,还会有查准率和查全率,下面举例解释。
按照周志华《机器学习》中的例子,以西瓜问题为例。
错误率:有多少比例的西瓜被判断错误;
查准率(precision):算法挑出来的西瓜中有多少比例是好西瓜;
查全率(recall):所有的好西瓜中有多少比例被算法跳了出来。
继续按照上述前提,对于二分类问题,我们根据真实类别与算法预测类别会有下面四个名词:
在写下面四个名词前,需要给一些关于T(true)、F(false)、P(positive)、N(negative)的解释:P表示算法预测这个样本为1(好西瓜)、N表示算法预测这个样本为0(坏西瓜);T表示算法预测的和真实情况一样,即算法预测正确,F表示算法预测的和真实情况不一样,即算法预测不对。
TP:正确地标记为正,即算法预测它为好西瓜,这个西瓜真实情况也是好西瓜(双重肯定是肯定);
FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。
所以有:
FP:错误地标记为正,即算法预测它是好西瓜,但这个西瓜真实情况是坏西瓜;
FN:错误地标记为负,即算法预测为坏西瓜,(F算法预测的不对)但这个西瓜真实情况是好西瓜(双重否定也是肯定);
TN:正确地标记为负,即算法标记为坏西瓜,(T算法预测的正确)这个西瓜真实情况是坏西瓜。
所以有:

F1度量的准则是:F1值越大算法性能越好,参考下面的公式:

在一些实际使用中,可能会对查准率或者查全率有偏重,比如:逃犯信息检索系统中,更希望尽量少的漏掉逃犯,此时的查全率比较重要。会有下面F1的一般形式:
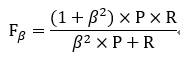
当beta>1时查全率重要,beta<1时查准率重要
以上关于精度、查准率、查全率的论述转自https://blog.csdn.net/qq_27871973/article/details/81065074 总结的很好所以我没有改动。
以下关于满足和优化的评估指标来自吴恩达老师的公开课:
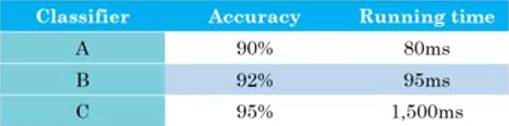
首先Accuracy也可以是上述单一数字评估指标中的任何一种,然后我们又得到了算法的时间性能running time。在这两种条件下如何综合衡量模型的好坏呢?
第一种方法:
线性叠加的思路:cost = Accuracy - 0.5Running time
当然这种线性加权求和的方式显得有些武断
第二种方法:
满足和优化的思路:cost = max(Accuracy) && Running time < 100
这种思路下,认为Accuracy是一种优化指标optimizing metric,同时Running time是一种满足指标satisficing metric,因为只要其满足了条件之后无论多好我们不再关注。
总结一下:当你有N个指标去考量的时候,通常选取其中的1种作为优化指标,剩下的N-1都是满足指标