【Python基础学习】—多线程
前言
我们知道,每个独立的进程有一个程序运行的入口、顺序执行序列和程序的出口。进程里面的任务由线程执行,线程必须依存在应用程序中,多个线程执行能够提高应用程序的执行效率,多个线程之间共用进程的寄存器数据和堆栈等等。
python多线程类似于同时执行多个不同程序,具有以下特点:
1、用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
程序的运行速度可能加快
2、在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
一、python使用多线程
Python中使用线程有两种方式:_thread模块函数或者用threading 模块封装类来使用线程对象。
1、_thread模块函数方式:
_thread.start_new_thread ( function, args[, kwargs] )
注:原本的thread 模块已被废弃。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 "_thread"。在此推荐使用第二种模块封装的方式:threading 模块。
2、threading 模块封装:
threading 模块除了包含 _thread 模块中的所有方法外,还提供的其他方法:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
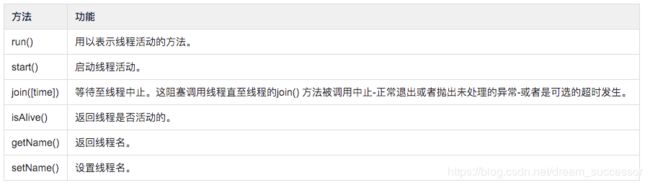
使用 threading 模块创建线程:
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")二、线程同步问题
和Java的多线程一样,Python多线程也要处理线程同步问题,如果多个线程共同对某个数据修改,则在数据的正确性和一致性方面可能出现不可预料的结果。
使用 Thread 对象的锁机制可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
锁有两种状态——锁定和未锁定。每当一个线程要访问共享数据时,必须先获得锁定;如果已经有别的线程获得锁定了,那么就让当前线程暂停,也就是同步阻塞;等到锁定的线程访问完毕,释放锁以后,再让当前线程继续。
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")以上程序输出结果就是同步阻塞的:
开启线程: Thread-1
开启线程: Thread-2
Thread-1: Wed Apr 6 11:52:57 2016
Thread-1: Wed Apr 6 11:52:58 2016
Thread-1: Wed Apr 6 11:52:59 2016
Thread-2: Wed Apr 6 11:53:01 2016
Thread-2: Wed Apr 6 11:53:03 2016
Thread-2: Wed Apr 6 11:53:05 2016
退出主线程三、python多线程的局限性
与PHP一样,脚本解释性的语言都需要一个解析器,一边解析一边运行程序,PHP中通常使用CGI、Fast-CGI协议解析器来解释PHP语言,python也有多种解析器,可以让python在多种环境下(如CPython解析器,PyPy,Psyco)执行,通常默认的也就是用的最多的是CPython解析器,CPython实现了PHP的解析器没有实现的多线程环境,能对多线程进行调度管理。
但是,CPython里面就算开了多个线程环境,CPython解释器也只能一个一个地解释Python语言来运行,这是因为Python解释器CPython采用了全局解释器锁(GIL)的机制,所以多线程实质上也是由当个解释器逐一解释运行,没办法做到真正的并行。
关于Python的全局解释器锁(GIL)的机制,将会在接下来的文章中详细介绍。
本文参考链接:https://www.runoob.com/python3/python3-multithreading.html