优达学城《无人驾驶入门》学习笔记——卡尔曼滤波器实现详解
优达学城《无人驾驶入门》的第二个项目是实现矩阵类,要求通过python编写一个用来计算矩阵的类Matrix.编写这个类并不难,涉及到的线性代数方面的知识也不多,比如矩阵的加法、减法、乘法,求逆矩阵,创建单位矩阵等。相比之下,理解编写矩阵类的目的反而显得更加重要。
编写矩阵类,是为实现了卡尔曼滤波器。卡尔曼滤波器涉及的知识很广,涵盖了《无人驾驶入门》课程第二部分“贝叶斯定理”和第三部分“使用矩阵”这两部分的内容,包括贝叶斯定义、高斯分布、运动模型、线性代数等内容。个人认为,如果把“实现卡尔曼滤波器”做为项目会更好。可能考虑到难度有些大,课程是通过workspace(“卡尔曼滤波器和你的矩阵类”)的形式演示了如何实现卡尔曼滤波器。workspace还调用了datagenerator用来生成输入的数据,它是非常好的学习资源,值得研究。
这篇文章的目的有2个:
第一个目的,介绍实现卡尔曼滤波器的3个步骤:
-
创建矩阵类。编写矩阵类是你需要完成的项目,我不会在这里公布答案,而是向你介绍一些扩展内容。项目要求使用列表来实现矩阵类,这样做的好处是,首先,需要的python知识比较基础,难度不大;其次,了解矩阵计算的原理。作为扩展内容,我会提供一个新思路,向你介绍如何通过numpy库来实现矩阵类。使用numpy库的ndarray和matrix来计算矩阵,会比列表方便得多。丰富的第三方库,正是python功能强大的原因之一。
-
创建汽车行驶的数据。我会对workspace“卡尔曼滤波器和你的矩阵类”中调用的datagenerator.py文件进行讲解,介绍函数generate_data和generate_lidar是如何生成汽车的行驶数据和测量数据的。这两个函数运用到了课程中学习过的运动模型和高斯分布等知识。
-
实现卡尔曼滤波器,并且可视化。把卡尔曼滤波器的公式编写成程序并不难,但是我希望你能了解公式中的参数分别代表哪些量,如何获得这些量。至于如何推导公式,如果有能力完成当然更好,推导不出来也没有关系。最后,通过matplotlib库将卡尔曼滤波器可视化。
第二个目的,推荐一些学习资料。主要包括numpy库,matplotlib库,卡尔曼滤波器的公式推导,以及一个神奇的公式可视化网站,你可以用来观察高斯分布等公式。
1 实现卡尔曼滤波器的步骤
1 创建矩阵类
numpy库的ndarry和matrix对象非常适合用来实现矩阵计算。两个列表相加,是这样实现的:
a = [1,2,3]
b = [4,5,6]
print(a+b)
[1, 2, 3, 4, 5, 6]而两个长度相同的ndarray对象相加,结果完全不同:
c = np.array([1,2,3])
d = np.array([4,5,6])
print(c+d)
[5 7 9]很显然,ndarray的加法就是矩阵的加法。ndarray还有很多矩阵计算的方法和属性,比如矩阵乘法:ndarray.dot();矩阵的迹:ndarray.trace();转置矩阵:ndarray.T.
matrix对象大部分功能和ndarray相同,但是它还提供了一个计算逆矩阵的方法:Matrix.I.
除此之外,numpy还提供了创建矩阵的函数,比如创建单位矩阵:numpy.eye().
下面是通过numpy类实现矩阵类的代码。如果你已经完成了这个项目,对比一下,你会发现,numpy库可以让代码简洁不少。
import numbers
import numpy as np
import matplotlib.pyplot as plt
import math
# 卡尔曼滤波器需要调用的矩阵类
class Matrix(object):
# 构造矩阵
def __init__(self, grid):
self.g = np.array(grid)
self.h = len(grid)
self.w = len(grid[0])
# 单位矩阵
def identity(n):
return Matrix(np.eye(n))
# 矩阵的迹
def trace(self):
if not self.is_square():
raise(ValueError, "Cannot calculate the trace of a non-square matrix.")
else:
return self.g.trace()
# 逆矩阵
def inverse(self):
if not self.is_square():
raise(ValueError, "Non-square Matrix does not have an inverse.")
if self.h > 2:
raise(NotImplementedError, "inversion not implemented for matrices larger than 2x2.")
if self.h == 1:
m = Matrix([[1/self[0][0]]])
return m
if self.h == 2:
try:
m = Matrix(np.matrix(self.g).I)
return m
except np.linalg.linalg.LinAlgError as e:
print("Determinant shouldn't be zero.", e)
# 转置矩阵
def T(self):
T = self.g.T
return Matrix(T)
# 判断矩阵是否为方阵
def is_square(self):
return self.h == self.w
# 通过[]访问
def __getitem__(self,idx):
return self.g[idx]
# 打印矩阵的元素
def __repr__(self):
s = ""
for row in self.g:
s += " ".join(["{} ".format(x) for x in row])
s += "\n"
return s
# 加法
def __add__(self,other):
if self.h != other.h or self.w != other.w:
raise(ValueError, "Matrices can only be added if the dimensions are the same")
else:
return Matrix(self.g + other.g)
# 相反数
def __neg__(self):
return Matrix(-self.g)
#减法
def __sub__(self, other):
if self.h != other.h or self.w != other.w:
raise(ValueError, "Matrices can only be subtracted if the dimensions are the same")
else:
return Matrix(self.g - other.g)
# 矩阵乘法:两个矩阵相乘
def __mul__(self, other):
if self.w != other.h:
raise(ValueError, "number of columns of the pre-matrix must equal the number of rows of the post-matrix")
return Matrix(np.dot(self.g, other.g))
# 标量乘法:变量乘以矩阵
def __rmul__(self, other):
if isinstance(other, numbers.Number):
return Matrix(other * self.g)
2 创建汽车行驶的数据
实现卡尔曼滤波器,需要汽车的行驶数据。行驶数据分为两类,一类是真实数据,另一类是传感器测量到的数据。
真实数据通过建立汽车的运动模型来实现。测量数据需要考虑传感器的误差,假设误差呈高斯分布,那么,可以在真实数据的基础上加上一个高斯分布的样本,样本的期望为0,标准差为0.15.
真实数据是通过函数generate_data()来实现的。为了突出重点,我对函数进行了简化,比如删除了单位换算,一律使用国际单位制;简化了运动模型。
# 生成汽车行驶的真实数据
# 汽车从以初速度v0,加速度a行驶10秒钟,然后匀速行驶20秒
# x0:initial distance, m
# v0:initial velocity, m/s
# a:acceleration,m/s^2
# t1:加速行驶时间,s
# t2:匀速行驶时间,s
# dt:interval time, s
def generate_data(x0, v0, a, t1, t2, dt):
a_current = a
v_current = v0
t_current = 0
# 记录汽车运行的真实状态
a_list = []
v_list = []
t_list = []
# 汽车运行的两个阶段
# 第一阶段:加速行驶
while t_current <= t1:
# 记录汽车运行的真实状态
a_list.append(a_current)
v_list.append(v_current)
t_list.append(t_current)
# 汽车行驶的运动模型
v_current += a * dt
t_current += dt
# 第二阶段:匀速行驶
a_current = 0
while t2 > t_current >= t1:
# 记录汽车运行的真实状态
a_list.append(a_current)
v_list.append(v_current)
t_list.append(t_current)
# 汽车行驶的运动模型
t_current += dt
# 计算汽车行驶的真实距离
x = x0
x_list = [x0]
for i in range(len(t_list) - 1):
tdelta = t_list[i+1] - t_list[i]
x = x + v_list[i] * tdelta + 0.5 * a_list[i] * tdelta**2
x_list.append(x)
return t_list, x_list, v_list, a_list
# 生成雷达获得的数据。需要考虑误差,误差呈现高斯分布
def generate_lidar(x_list, standard_deviation):
return x_list + np.random.normal(0, standard_deviation, len(x_list))
# 获取汽车行驶的真实状态
t_list, x_list, v_list, a_list = generate_data(100, 5, 4, 10, 20, 0.1)
# 创建激光雷达的测量数据
# 测量误差的标准差。为了方便观测,可以增加该值。
standard_deviation = 0.15
# 雷达测量得到的距离
lidar_x_list = generate_lidar(x_list, standard_deviation)
# 雷达测量的时间
lidar_t_list = t_list真实数据和测量数据生成完毕后,下面将这些数据可视化。一共会创建6幅图像,分别是真实距离,真实速度,真实加速度,激光雷达测量的距离值。
# 可视化.创建包含2*3个子图的视图
fig, ((ax1, ax2, ax3), (ax4, ax5, ax6)) = plt.subplots(2, 3, figsize=(20, 15))
# 真实距离
ax1.set_title("truth distance")
ax1.set_xlabel("time")
ax1.set_ylabel("distance")
ax1.set_xlim([0, 21])
ax1.set_ylim([0, 1000])
ax1.plot(t_list, x_list)
# 真实速度
ax2.set_title("truth velocity")
ax2.set_xlabel("time")
ax2.set_ylabel("velocity")
ax2.set_xlim([0, 21])
ax2.set_ylim([0, 50])
ax2.set_xticks(range(21))
ax2.set_yticks(range(0, 50, 5))
ax2.plot(t_list, v_list)
# 真实加速度
ax3.set_title("truth acceleration")
ax3.set_xlabel("time")
ax3.set_ylabel("acceleration")
ax3.set_xlim([0, 21])
ax3.set_ylim([0, 5])
ax3.plot(t_list, a_list)
# 激光雷达测量结果
ax4.set_title("Lidar measurements VS truth")
ax4.set_xlabel("time")
ax4.set_ylabel("distance")
ax4.set_xlim([0, 21])
ax4.set_ylim([0, 1000])
ax4.set_xticks(range(21))
ax4.set_yticks(range(0, 1000, 100))
ax4.plot(t_list, x_list, label="truth distance")
ax4.scatter(lidar_t_list, lidar_x_list, label="Lidar distance", color="red", marker="o", s=2)
ax4.legend()
可以通过plt.show()观察一下。
3 实现卡尔曼滤波器,并且可视化
卡尔曼滤波器的公式如下:
预测:
![]()
![]()
更新:
![]()
![]()
![]()
![]()
![]()
![]()
下面简单介绍一下各个参数的含义。如果想深入了解公式的推导过程,可以看看最后推荐的文章。
预测状态:![]()
根据本时刻的状态![]() (这里是位置和速度),基于状态转换矩阵
(这里是位置和速度),基于状态转换矩阵![]() ,控制矩阵
,控制矩阵![]() ,以及控制向量
,以及控制向量![]() ,预测下一时刻的状态
,预测下一时刻的状态![]() .
.
预测误差的协方差矩阵:![]()
状态向量中的两个变量p(位置)和v(速度)存在相关性,用误差协方差矩阵![]() 表示。外部无法检测到的干扰,比如风的干扰,也会增加不确定性。把这些没有被跟踪的干扰当作协方差为的噪音来处理。
表示。外部无法检测到的干扰,比如风的干扰,也会增加不确定性。把这些没有被跟踪的干扰当作协方差为的噪音来处理。 ![]() 是过程噪音协方差矩阵,它会增加不确定性。
是过程噪音协方差矩阵,它会增加不确定性。
预测状态和测量状态之差 :![]()
z是测量向量,表示传感器测量到的数据(比如传感器测量到的汽车的位置)。测量值和预测值(更新后的)之间存在误差![]() .
.
如果状态向量和测量向量包含的数据不同,比如状态向量包括位置和速度,而测量向量只有位置,那么![]() 。
。
测量噪音协方差矩阵:![]()
测量结果存在噪音,用![]() 来表示测量噪音协方差矩阵。因为测量值只有位置一个变量,所以这里是位置的方差。
来表示测量噪音协方差矩阵。因为测量值只有位置一个变量,所以这里是位置的方差。
用于计算卡尔曼增益的中间量:![]()
![]()
卡尔曼增益: ![]()
更新状态矩阵: ![]()
更新误差协方差矩阵: ![]()
各个变量之间的关系请见下图:
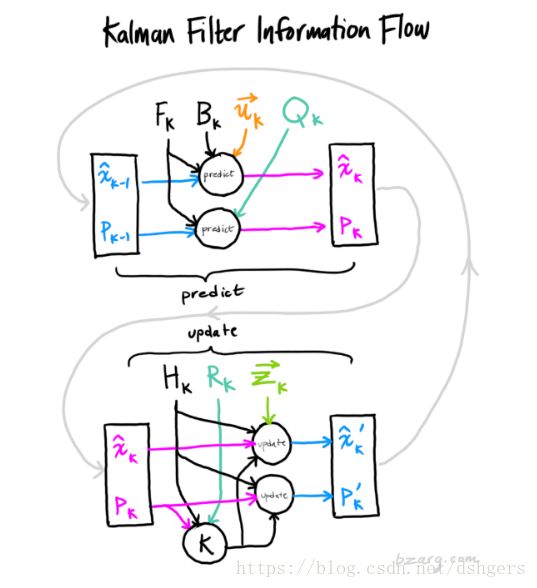
这张图片来自文尾推荐的推导卡尔曼滤波器公式的文章,有兴趣可以了解一下。
代码如下:
# 使用卡尔曼滤波器
# 初始距离。注意:这里假设初始距离为0,因为无法测量初始距离。
initial_distance = 0
# 初始速度。注意:这里假设初始速度为0,因为无法测量初始速度。
initial_velocity = 0
# 状态矩阵的初始值
x_initial = Matrix([[initial_distance], [initial_velocity]])
# 误差协方差矩阵的初始值
P_initial = Matrix([[5, 0], [0, 5]])
# 加速度方差
acceleration_variance = 50
# 雷达测量结果方差
lidar_variance = standard_deviation**2
# 观测矩阵,联系预测向量和测量向量
H = Matrix([[1, 0]])
# 测量噪音协方差矩阵。因为测量值只有位置一个变量,所以这里是位置的方差。
R = Matrix([[lidar_variance]])
# 单位矩阵
I = Matrix.identity(2)
# 状态转移矩阵
def F_matrix(delta_t):
return Matrix([[1, delta_t], [0, 1]])
# 外部噪音协方差矩阵
def Q_matrix(delta_t, variance):
t4 = math.pow(delta_t, 4)
t3 = math.pow(delta_t, 3)
t2 = math.pow(delta_t, 2)
return variance * Matrix([[(1/4)*t4, (1/2)*t3], [(1/2)*t3, t2]])
def B_matrix(delta_t):
return Matrix([[delta_t**2 / 2], [delta_t]])
# 状态矩阵
x = x_initial
# 误差协方差矩阵
P = P_initial
# 记录卡尔曼滤波器计算得到的距离
x_result = []
# 记录卡尔曼滤波器的时间
time_result = []
# 记录卡尔曼滤波器得到的速度
v_result = []
for i in range(len(lidar_x_list) - 1):
delta_t = (lidar_t_list[i + 1] - lidar_t_list[i])
# 预测
F = F_matrix(delta_t)
Q = Q_matrix(delta_t, acceleration_variance)
# 注意:运动模型使用的是匀速运动,汽车实际上有一段时间是加速运动的
x_prime = F * x
P_prime = F * P * F.T() + Q
# 更新
# 测量向量和状态向量的差值。注意:第一个时刻是没有测量值的,
# 只有经过一个脉冲周期,才能获得测量值。
y = Matrix([[lidar_x_list[i + 1]]]) - H * x_prime
S = H * P_prime * H.T() + R
K = P_prime * H.T() * S.inverse()
x = x_prime + K * y
P = (I - K * H) * P_prime
x_result.append(x[0][0])
v_result.append(x[1][0])
time_result.append(lidar_t_list[i+1])最后,把卡尔曼滤波器的结果可视化。
# 把真实距离、激光雷达测量的距离以及卡尔曼滤波器的结果(距离)可视化
ax5.set_title("Lidar measurements VS truth")
ax5.set_xlabel("time")
ax5.set_ylabel("distance")
ax5.set_xlim([0, 21])
ax5.set_ylim([0, 1000])
ax5.set_xticks(range(0, 21, 2))
ax5.set_yticks(range(0, 1000, 100))
ax5.plot(t_list, x_list, label="truth distance", color="blue", linewidth=1)
ax5.scatter(lidar_t_list, lidar_x_list, label="Lidar distance", color="red", marker="o", s=2)
ax5.scatter(time_result, x_result, label="kalman", color="green", marker="o", s=2)
ax5.legend()
# 把真实速度、卡尔曼滤波器的结果(速度)可视化
ax6.set_title("Lidar measurements VS truth")
ax6.set_xlabel("time")
ax6.set_ylabel("velocity")
ax6.set_xlim([0, 21])
ax6.set_ylim([0, 50])
ax6.set_xticks(range(0, 21, 2))
ax6.set_yticks(range(0, 50, 5))
ax6.plot(t_list, v_list, label="truth velocity", color="blue", linewidth=1)
ax6.scatter(time_result, v_result, label="Lidar velocity", color="red", marker="o", s=2)
ax6.legend()
plt.show()参考源码:kalman filter
运行代码,得到的图像如下:
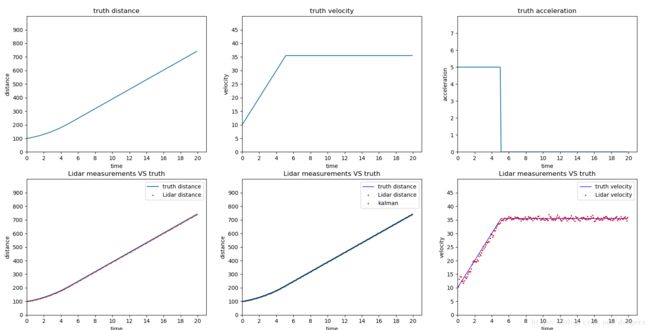
为了更好地了解各个参数的意义,我们可以尝试修改一些参数,观察图像的变化。
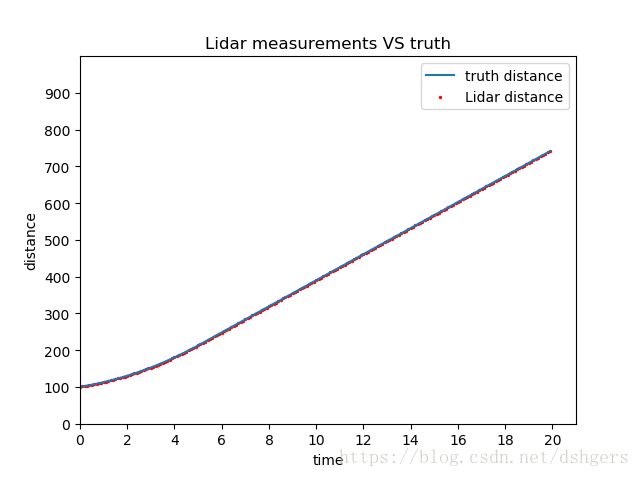
首先看看激光雷达的测量误差。激光雷达的标准差standard_deviation是0.15,真实数据和测量数据的图像是上图中的第4幅,可以看点表示测量数据的离散点分布在表示真实数据的折线的周围。
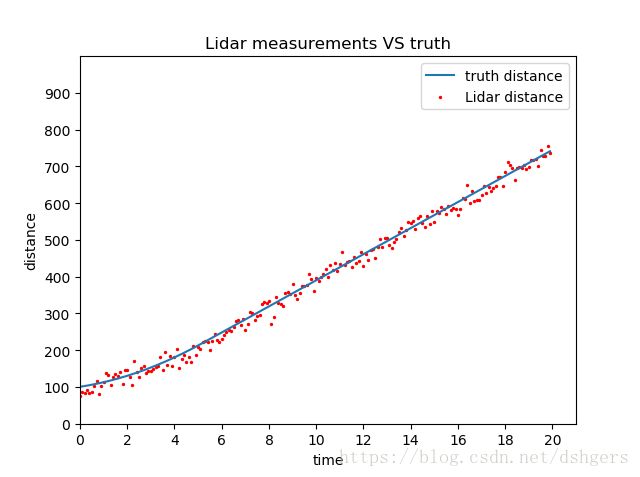
如果改变标准差standard_deviation,比如从0.15增加到15,离散点的分散程度就明显多了。
接下来看看真实数据,测量数据和卡尔曼滤波器测量到的距离,也就是第5幅图。当标准差standard_deviation是0.15时,3种数据很难看出差别。
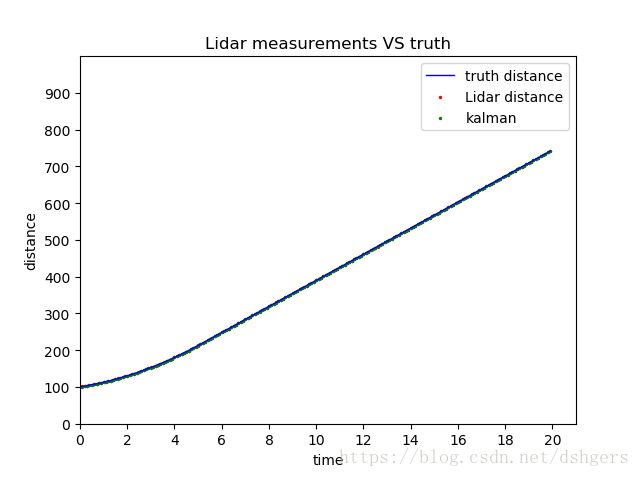
把标准差standard_deviation增加到15,差别就比较明显了。
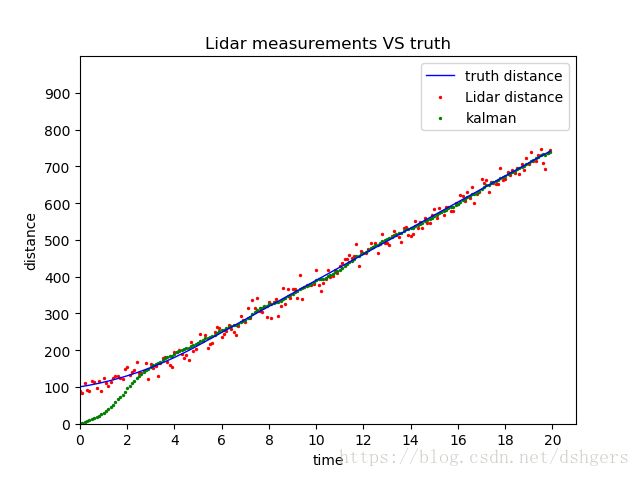
观察这两幅图,可以得出两个结论:
第一,相比于测量数据,卡尔曼滤波器计算得出的数据更加接近真实数据;
第二,在使用卡尔曼滤波器时,设置的初始距离initial_distance和初始速度initial_velocity都是0,因为初始数据无法测量,所以假设为0.
第三,标准差standard_deviation越大,测量数据越不准确,并且会影响卡尔曼滤波器的精度。比较两幅图可以看出,当标准差standard_deviation是0.15时,卡尔曼滤波器的数据点分布在真实数据周围;而当标准差standard_deviation增加到15时,卡尔曼滤波器的数据点是从0开始的。
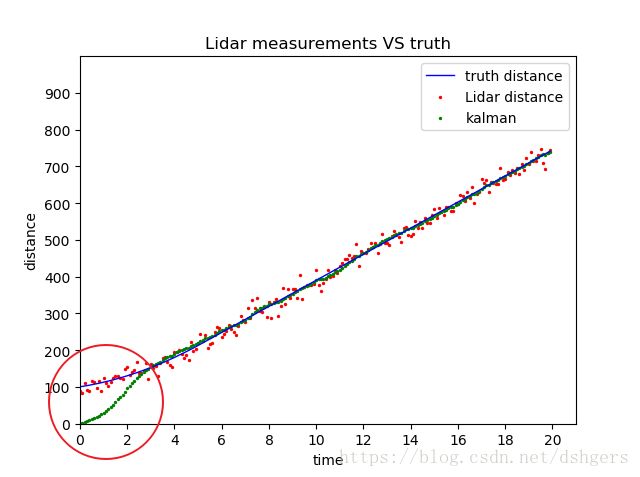
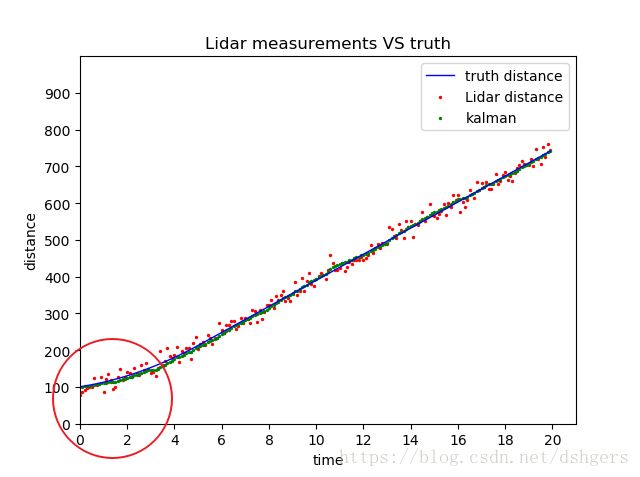
第四,初始距离initial_distance和初始速度initial_velocity同样会影响卡尔曼滤波器的测量精度。保持标准差standard_deviation为15不变,把初始距离initial_distance设置为100(同真实距离),初始速度initial_velocity设置为10(同真实速度),可以发现卡尔曼滤波器的结果更加接近真实数据了。
2 荐学习资料推荐
numpy库资料
numpy库官网
网络课程
翻译版
matplotlib库资料
matplotlib库官网
网络课程
翻译版
卡尔曼滤波器公式推导
卡尔曼滤波器公式推导(英文)
卡尔曼滤波器公式推导(中文翻译版)
公式可视化网站
我非常喜欢把抽象的内容可视化,比如数据结构的可视化,算法的可视化,国外也有不少这方面的网站。把抽象的概念具象化,可视化,生动形象,容易理解。在《 学习优达学城《无人驾驶入门》,具体需要掌握哪些python知识点? 》这篇文章中,我也介绍了一个代码可视化的网站。这次介绍的,是一个公式可视化网站。
DESMOS不但可以显示函数曲线、几何图形,还提供了额外功能,比如,通过改变某一个变量,显示曲线变化的过程。在学习高斯分布这一部分时,我通过改变标准差和期望,观察这两个变量对概率密度曲线的影响。
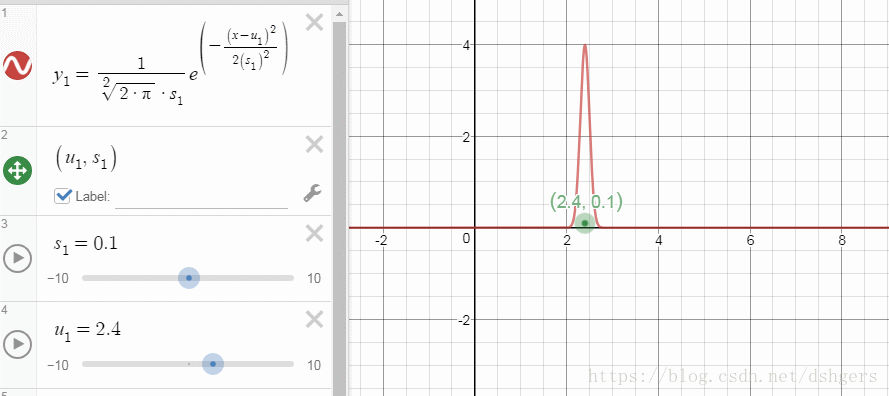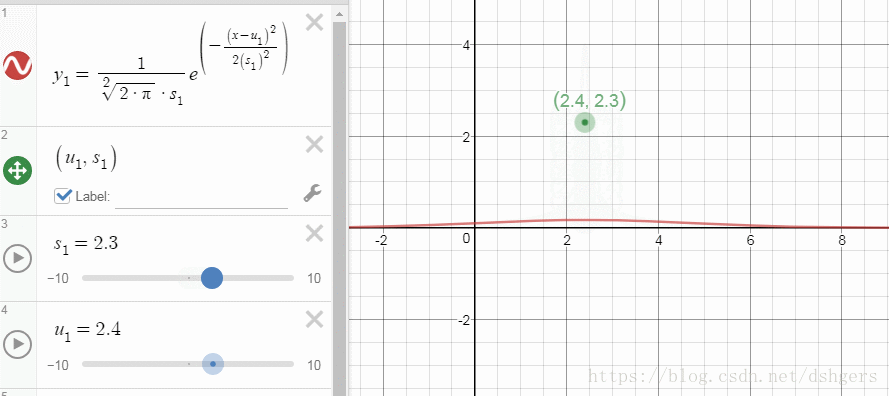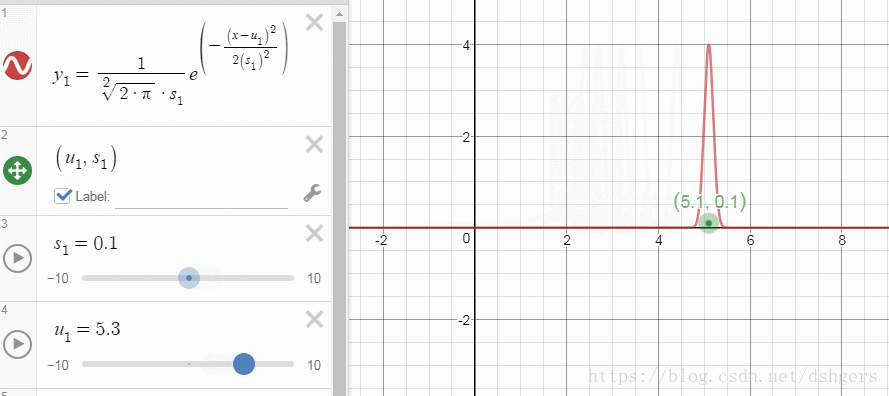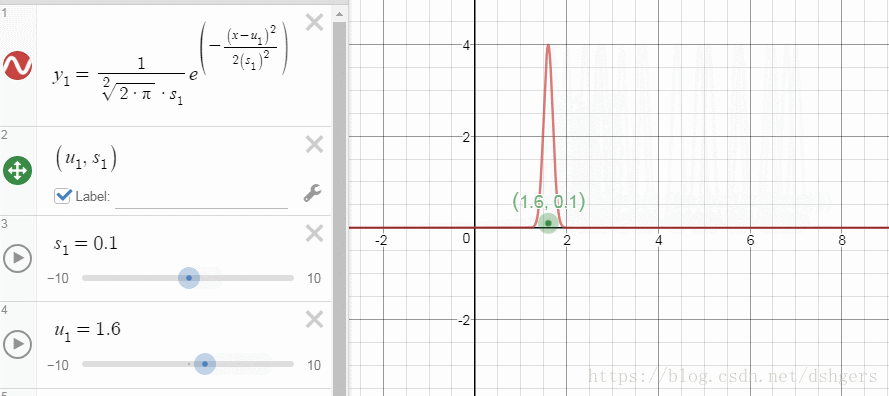
下面是使用DESMOS需要掌握的最小必要知识:
1 添加滑块
输入自由变量,会提示添加滑块。通过拖动滑块,可以改变图形。

2 添加标签
(x, y)
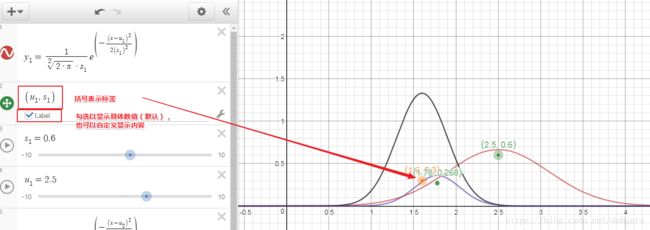
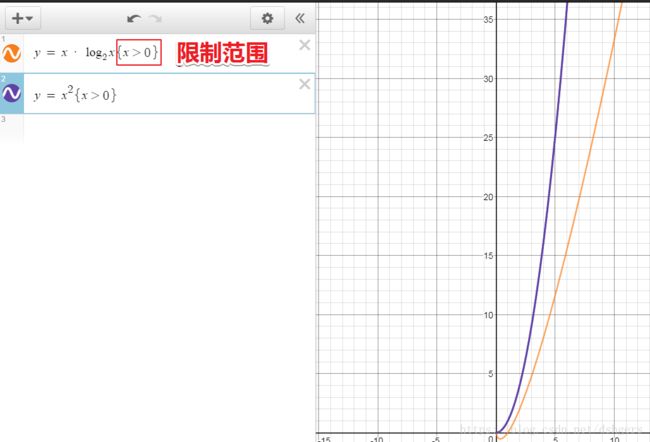
3 限制范围
{x>0}
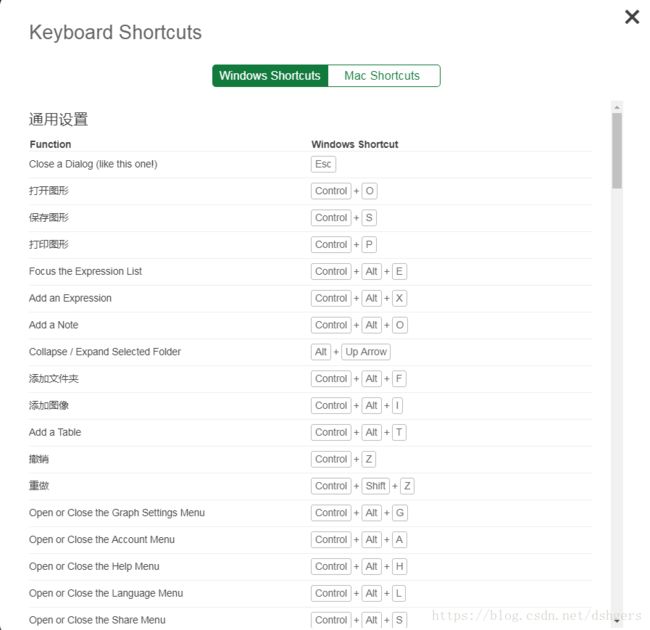
4 打开快捷键菜单
CTRL + /
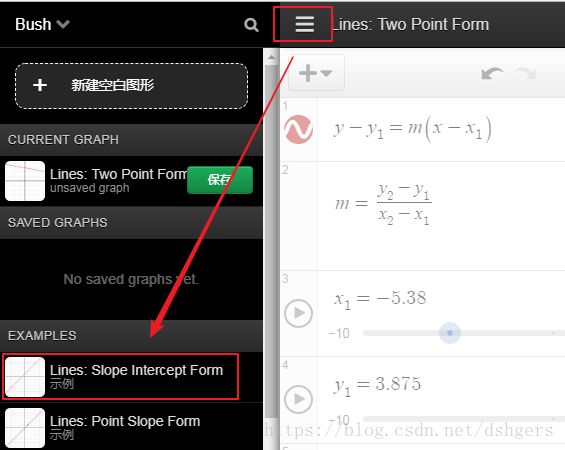
5 查看示例
网站链接:DESMOS
我是《无人驾驶入门》纳米学位的学长,希望这些经验对你有帮助。如果你对udacity的这门课程也感兴趣,可以使用我的优惠码:839662C0,付款时在优惠码框输入,可以抵扣300元学费(限第一次购买udacity课程的学弟学妹用哈)。