Spark商业案例与性能调优实战100课》第16课:商业案例之NBA篮球运动员大数据分析系统架构和实现思路
Spark商业案例与性能调优实战100课》第16课:商业案例之NBA篮球运动员大数据分析系统架构和实现思路
http://www.basketball-reference.com/leagues/NBA_2017_per_game.html
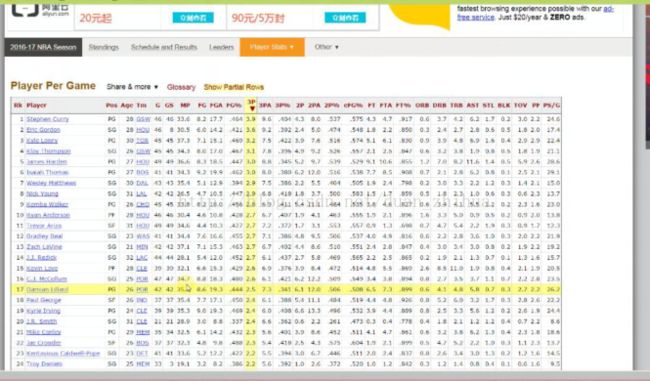

参考数据查询器
http://www.stat-nba.com/
| 球员 | 出场 | 首发 | 时间 | 投篮 | 命中 | 出手 | 三分 | 命中 | 出手 | 罚球 | 命中 | 出手 | 篮板 | 前场 | 后场 | 助攻 | 抢断 | 盖帽 | 失误 | 犯规 | 得分 | 胜 | 负 | |
| 1 | 迈克尔-乔丹 | 1072 | 1039 | 38.3 | 49.7% | 11.4 | 22.9 | 32.7% | 0.5 | 1.7 | 83.5% | 6.8 | 8.2 | 6.2 | 1.6 | 4.7 | 5.3 | 2.3 | 0.8 | 2.7 | 2.6 | 30.1 | ||
| 2 | 威尔特-张伯伦 | 1045 | 45.8 | 54.0% | 12.1 | 22.5 | 51.1% | 5.8 | 11.4 | 22.9 | 4.4 | 2 | 30.1 | |||||||||||
| 3 | 埃尔金·贝勒 | 846 | 40 | 43.1% | 10.3 | 23.8 | 78.0% | 6.8 | 8.7 | 13.5 | 4.3 | 3.1 | 27.4 | |||||||||||
| 4 | 凯文-杜兰特 | 689 | 689 | 37.5 | 48.7% | 9.2 | 18.9 | 38.0% | 1.8 | 4.7 | 88.2% | 7.1 | 8 | 7.1 | 0.8 | 6.4 | 3.8 | 1.2 | 1 | 3.2 | 1.9 | 27.3 | 415 | 274 |
| 5 | 勒布朗-詹姆斯 | 1030 | 1029 | 38.9 | 49.9% | 9.8 | 19.7 | 34.1% | 1.4 | 4 | 74.2% | 6.1 | 8.3 | 7.2 | 1.2 | 6 | 7 | 1.7 | 0.8 | 3.4 | 1.9 | 27.1 | 692 | 338 |
| 6 | 杰里-韦斯特 | 932 | 39.2 | 47.4% | 9.7 | 20.4 | 81.4% | 7.7 | 9.4 | 5.8 | 6.7 | 2.6 | 27 | |||||||||||
| 7 | 阿伦-艾弗森 | 914 | 901 | 41.1 | 42.5% | 9.3 | 21.8 | 31.3% | 1.2 | 3.7 | 78.0% | 7 | 8.9 | 3.7 | 0.8 | 2.9 | 6.2 | 2.2 | 0.2 | 3.6 | 1.9 | 26.7 | 466 | 448 |
| 8 | 鲍勃-佩蒂特 | 792 | 38.8 | 43.6% | 9.3 | 21.3 | 76.1% | 7.8 | 10.3 | 16.2 | 3 | 3.2 | 26.4 | |||||||||||
| 9 | 乔治-格文 | 791 | 33.5 | 51.1% | 10.2 | 19.9 | 84.4% | 5.7 | 6.8 | 4.6 | 1.5 | 3.1 | 2.8 | 1.2 | 0.8 | 2.9 | 26.2 | |||||||
| 10 | 奥斯卡-罗伯特森 | 1040 | 42.2 | 48.5% | 9.1 | 18.9 | 83.8% | 7.4 | 8.8 | 7.5 | 9.5 | 2.8 | 25.7 | |||||||||||
| 11 | 卡尔-马龙 | 1476 | 1471 | 37.2 | 51.6% | 9.2 | 17.8 | 27.4% | 0.1 | 0.2 | 74.2% | 6.6 | 8.9 | 10.1 | 2.4 | 7.7 | 3.6 | 1.4 | 0.8 | 3.1 | 3.1 | 25 | 952 | 524 |
| 12 | 科比-布莱恩特 | 1346 | 1198 | 36.1 | 44.7% | 8.7 | 19.5 | 32.9% | 1.4 | 4.1 | 83.7% | 6.2 | 7.4 | 5.2 | 1.1 | 4.1 | 4.7 | 1.4 | 0.5 | 3 | 2.5 | 25 | 836 | 510 |
| 13 | 卡梅罗-安东尼 | 950 | 950 | 36.2 | 45.2% | 8.9 | 19.6 | 34.6% | 1.2 | 3.4 | 81.3% | 6 | 7.3 | 6.6 | 1.8 | 4.8 | 3.1 | 1.1 | 0.5 | 2.8 | 2.9 | 24.8 | 525 | 425 |
| 14 | 多米尼克-威尔金斯 | 1074 | 995 | 35.5 | 46.1% | 9.3 | 20.1 | 31.9% | 0.7 | 2.1 | 81.1% | 5.6 | 6.9 | 6.7 | 2.7 | 3.9 | 2.5 | 1.3 | 0.6 | 2.5 | 1.9 | 24.8 | ||
| 15 | 卡里姆-贾巴尔 | 1560 | 36.8 | 55.9% | 10.2 | 18.1 | 72.1% | 4.3 | 6 | 11.2 | 3.6 | 3 | 24.6 | |||||||||||
| 16 | 拉里·伯德 | 897 | 870 | 38.4 | 49.6% | 9.6 | 19.3 | 37.6% | 0.7 | 1.9 | 88.6% | 4.4 | 5 | 10 | 2 | 8 | 6.3 | 1.7 | 0.8 | 3.1 | 2.5 | 24.3 | ||
| 17 | 阿德里安-丹特利 | 955 | 35.8 | 54.0% | 8.6 | 15.8 | 81.8% | 7.2 | 8.7 | 5.7 | 2.3 | 3.4 | 3 | 1 | 0.2 | 2.7 | 24.3 | |||||||
| 18 | 皮特-马拉维奇 | 658 | 37 | 44.1% | 9.4 | 21.3 | 82.0% | 5.4 | 6.6 | 4.2 | 5.4 | 2.8 | 24.2 | |||||||||||
| 19 | 沙奎尔-奥尼尔 | 1207 | 1197 | 34.7 | 58.2% | 9.4 | 16.1 | 4.5% | 0 | 0 | 52.7% | 4.9 | 9.3 | 10.9 | 3.5 | 7.4 | 2.5 | 0.6 | 2.3 | 2.7 | 3.4 | 23.7 | 819 | 388 |
| 20 | 德维恩-韦德 | 899 | 888 | 35.5 | 48.5% | 8.5 | 17.5 | 28.7% | 0.5 | 1.6 | 76.8% | 6 | 7.8 | 4.8 | 1.3 | 3.5 | 5.7 | 1.7 | 0.9 | 3.3 | 2.3 | 23.4 | 531 | 368 |
| 球队 | 赛季 | 投篮 | 命中 | 出手 | 三分 | 命中 | 出手 | 罚球 | 命中 | 出手 | 篮板 | 前场 | 后场 | 助攻 | 抢断 | 盖帽 | 失误 | 犯规 | 得分 | 失分 | 胜 | 负 | 公式 | |
| 1 | 金州勇士 | 15-16 | 48.7% | 42.5 | 87.3 | 41.5% | 13.1 | 31.6 | 76.3% | 16.7 | 21.8 | 46.2 | 10 | 36.2 | 28.9 | 8.4 | 6.1 | 14.9 | 20.7 | 114.9 | 104.1 | 73 | 9 | 89 |
| 2 | 芝加哥公牛 | 95-96 | 47.8% | 40.2 | 84 | 40.3% | 6.6 | 16.5 | 74.6% | 18.2 | 24.4 | 44.6 | 15.2 | 29.4 | 24.8 | 9.1 | 4.2 | 13.8 | 22 | 105.2 | 92.9 | 72 | 10 | 87.8 |
| 3 | 金州勇士 | 16-17 | 50.1% | 43.7 | 87.2 | 38.6% | 11.9 | 30.9 | 79.0% | 18.7 | 23.6 | 45.2 | 9 | 36.2 | 31 | 9.4 | 6.4 | 14.9 | 19.2 | 118 | 104.8 | 41 | 7 | 85.4 |
| 4 | 芝加哥公牛 | 96-97 | 47.3% | 40 | 84.4 | 37.3% | 6.4 | 17.1 | 74.7% | 16.8 | 22.5 | 45.1 | 15.1 | 30 | 26.1 | 8.7 | 4 | 13.1 | 19.7 | 103.1 | 92.3 | 69 | 13 | 84.1 |
| 5 | 波士顿凯尔特人 | 85-86 | 50.8% | 45.3 | 89.2 | 35.3% | 1.7 | 4.8 | 79.4% | 21.8 | 27.4 | 46.4 | 12.9 | 33.5 | 29 | 7.8 | 6.2 | 16.3 | 21.4 | 114.1 | 104.7 | 67 | 15 | 81.7 |
| 6 | 芝加哥公牛 | 91-92 | 50.8% | 44.4 | 87.4 | 30.4% | 1.7 | 5.5 | 74.4% | 19.4 | 26 | 44 | 14.3 | 29.7 | 27.8 | 8.2 | 5.9 | 12.8 | 20.6 | 109.9 | 99.5 | 67 | 15 | 81.7 |
| 7 | 达拉斯小牛 | 06-07 | 46.7% | 36.7 | 78.6 | 38.1% | 6.5 | 17.1 | 80.5% | 20.1 | 24.9 | 41.9 | 11.2 | 30.7 | 19.9 | 6.8 | 5 | 13.1 | 22.4 | 100 | 92.8 | 67 | 15 | 81.7 |
| 8 | 金州勇士 | 14-15 | 47.8% | 41.6 | 87 | 39.8% | 10.8 | 27 | 76.8% | 16 | 20.8 | 44.7 | 10.4 | 34.3 | 27.4 | 9.3 | 6 | 14.1 | 19.9 | 110 | 99.8 | 67 | 15 | 81.7 |
| 9 | 洛杉矶湖人 | 99-00 | 45.9% | 38.3 | 83.4 | 32.9% | 4.2 | 12.8 | 69.6% | 20.1 | 28.9 | 47 | 13.6 | 33.4 | 23.4 | 7.5 | 6.5 | 13.5 | 22.5 | 100.8 | 92.3 | 67 | 15 | 81.7 |
| 10 | 圣安东尼奥马刺 | 15-16 | 48.4% | 40.1 | 82.9 | 37.6% | 7 | 18.5 | 80.3% | 16.4 | 20.4 | 43.9 | 9.4 | 34.5 | 24.5 | 8.3 | 5.9 | 12.5 | 17.5 | 103.5 | 92.9 | 67 | 15 | 81.7 |
| 11 | 波士顿凯尔特人 | 07-08 | 47.5% | 36.4 | 76.7 | 38.1% | 7.3 | 19.1 | 77.1% | 20.5 | 26.5 | 42 | 10.1 | 31.9 | 22.4 | 8.5 | 4.6 | 14.4 | 22.7 | 100.5 | 90.3 | 66 | 16 | 80.5 |
| 12 | 克里夫兰骑士 | 08-09 | 46.8% | 36.9 | 78.7 | 39.3% | 8 | 20.4 | 75.7% | 18.6 | 24.5 | 42.2 | 10.8 | 31.4 | 20.3 | 7.2 | 5.3 | 12 | 20.3 | 100.3 | 91.4 | 66 | 16 | 80.5 |
| 13 | 迈阿密热火 | 12-13 | 49.6% | 38.4 | 77.4 | 39.6% | 8.7 | 22.1 | 75.4% | 17.4 | 23 | 38.6 | 8.2 | 30.4 | 23 | 8.7 | 5.4 | 13.3 | 18.7 | 102.9 | 95 | 66 | 16 | 80.5 |
| 14 | 洛杉矶湖人 | 08-09 | 47.4% | 40.3 | 85.1 | 36.1% | 6.7 | 18.5 | 77.0% | 19.6 | 25.5 | 43.9 | 12.4 | 31.5 | 23.3 | 8.8 | 5.1 | 13.1 | 20.7 | 106.9 | 99.3 | 65 | 17 | 79.3 |
| 15 | 洛杉矶湖人 | 86-87 | 51.6% | 45.6 | 88.3 | 36.8% | 2 | 5.4 | 78.9% | 24.5 | 31.1 | 44.4 | 13.7 | 30.7 | 29.6 | 8.9 | 5.8 | 16.4 | 22.6 | 117.8 | 108.5 | 65 | 17 | 79.3 |
| 16 | 底特律活塞 | 05-06 | 45.5% | 36.4 | 80 | 38.4% | 6.8 | 17.7 | 72.7% | 17.3 | 23.8 | 40.5 | 11.9 | 28.6 | 24 | 7.1 | 6 | 10.8 | 18.5 | 96.8 | 90.2 | 64 | 18 | 78 |
| 17 | 西雅图超音速 | 95-96 | 48.0% | 37.5 | 78.1 | 36.4% | 7.1 | 19.5 | 76.0% | 22.5 | 29.6 | 41.5 | 11.6 | 29.9 | 24.4 | 10.8 | 4.8 | 17.2 | 24 | 104.5 | 96.7 | 64 | 18 | 78 |
| 18 | 犹他爵士 | 96-97 | 50.4% | 38.2 | 75.8 | 37.0% | 4.1 | 11 | 76.9% | 22.7 | 29.5 | 40.2 | 10.8 | 29.4 | 26.8 | 9.1 | 5 | 14.9 | 24.2 | 103.1 | 94.3 | 64 | 18 | 78 |
| 19 | 底特律活塞 | 88-89 | 49.4% | 41.4 | 83.9 | 30.0% | 1.5 | 4.9 | 76.9% | 22.3 | 29 | 45.1 | 14.1 | 31 | 24.7 | 6.4 | 5 | 16 | 23.6 | 106.6 | 100.8 | 63 | 19 | 76.8 |
| 20 | 洛杉矶湖人 | 89-90 | 49.0% | 41.9 | 85.5 | 36.7% | 3.8 | 10.3 | 78.7% | 23.2 | 29.5 | 43.4 | 13.4 | 30 | 27.2 | 8 | 5.4 | 14.5 | 21.2 | 110.7 | 103.9 | 63 | 19 | 76.8 |
| 21 | 波特兰开拓者 | 90-91 | 48.5% | 43.6 | 89.9 | 37.7% | 4.2 | 11 | 75.3% | 23.3 | 31 | 45.9 | 14.7 | 31.2 | 27.5 | 8.8 | 5 | 15.7 | 24.1 | 114.7 | 106 | 63 | 19 | 76.8 |
| 22 | 圣安东尼奥马刺 | 05-06 | 47.2% | 36.5 | 77.3 | 38.5% | 6.4 | 16.6 | 70.2% | 16.2 | 23.1 | 41.5 | 10.4 | 31.1 | 20.9 | 6.6 | 5.7 | 13.3 | 20.9 | 95.6 | 88.8 | 63 | 19 | 76.8 |
| 23 | 西雅图超音速 | 93-94 | 48.4% | 40.7 | 84.2 | 33.5% | 3 | 8.8 | 74.5% | 21.6 | 29 | 41.2 | 14 | 27.2 | 25.8 | 12.8 | 4.5 | 14.8 | 23.3 | 105.9 | 96.9 | 63 | 19 | 76.8 |
| 24 | 圣安东尼奥马刺 | 16-17 | 47.9% | 39.8 | 83.1 | 41.1% | 9.3 | 22.6 | 81.4% | 18.6 | 22.8 | 42.9 | 9.3 | 33.6 | 24.3 | 7.9 | 5.6 | 12.4 | 18.3 | 107.4 | 99.3 | 36 | 11 | 76.6 |
| 25 | 芝加哥公牛 | 11-12 | 45.2% | 37.4 | 82.8 | 37.5% | 6.3 | 16.9 | 72.2% | 15.2 | 21.1 | 46.7 | 13.9 | 32.8 | 23.1 | 6.9 | 5.9 | 13.4 | 17.3 | 96.3 | 88.2 | 50 | 16 | 75.8 |
| 26 | 圣安东尼奥马刺 | 11-12 | 47.8% | 39.6 | 82.8 | 39.3% | 8.4 | 21.3 | 74.8% | 16.2 | 21.6 | 43 | 10.3 | 32.6 | 23.2 | 7.4 | 4.4 | 13.2 | 17.3 | 103.7 | 96.5 | 50 | 16 | 75.8 |
| 27 | 波士顿凯尔特人 | 08-09 | 48.6% | 37.5 | 77.2 | 39.7% | 6.6 | 16.5 | 76.5% | 19.4 | 25.3 | 42.1 | 10.6 | 31.5 | 22.7 | 7.6 | 4.7 | 15 | 23.1 | 100.9 | 93.4 | 62 | 20 | 75.6 |
| 28 | 芝加哥公牛 | 97-98 | 45.1% | 37.4 | 82.9 | 32.3% | 3.8 | 11.7 | 74.3% | 18.2 | 24.5 | 44.9 | 15.2 | 29.7 | 23.8 | 8.5 | 4.3 | 13.3 | 20.6 | 96.7 | 89.6 | 62 | 20 | 75.6 |
| 29 | 芝加哥公牛 | 10-11 | 46.2% | 37.1 | 80.3 | 36.1% | 6.2 | 17.3 | 74.3% | 18.2 | 24.5 | 44.2 | 11.8 | 32.4 | 22.3 | 7.2 | 5.7 | 13.5 | 20 | 98.6 | 91.3 | 62 | 20 | 75.6 |
| 30 | 洛杉矶湖人 | 85-86 | 52.1% | 46.8 | 89.7 | 33.8% | 1.7 | 5 | 77.8% | 22.1 | 28.4 | 44.6 | 13.4 | 31.2 | 29.7 | 8.4 | 5.1 | 17.6 | 24.7 | 117.3 | 109.5 | 62 | 20 | 75.6 |
序号 |
SEQ |
球队名称 |
TEAM |
赛季 |
SEASON |
投篮命中率 |
FG |
投篮命中数 |
FGM |
投篮出手次数 |
FGA |
三分球命中率 |
3P |
三分球命中数 |
3PM |
三分球出手次数 |
3PA |
罚球命中率 |
FT |
罚球命中次数 |
FTM |
罚球出手次数 |
FTA |
篮板 |
REBS |
前场篮板 |
OREB |
后场篮板 |
DREB |
助攻 |
AST |
抢断 |
STL |
盖帽 |
BLK |
失误 |
TO |
犯规 |
FOVLS |
场均得分 |
PTS |
场均失分 |
PTLS |
胜场 |
W |
负场 |
L |
1. package com.dt.spark.sparksql
2.
3. import scala.language.postfixOps
4. import org.apache.hadoop.conf.Configuration
5. import org.apache.hadoop.fs.{FileSystem, Path}
6. import org.apache.log4j.{Level, Logger}
7. import org.apache.spark.SparkConf
8. import org.apache.spark.broadcast.Broadcast
9. import org.apache.spark.rdd.RDD
10. import org.apache.spark.sql.{DataFrame, SparkSession}
11.
12. import scala.collection.{Map, mutable}
13.
14. /**
15. * 版权:DT大数据梦工厂所有
16. * 时间:2017年1月26日;
17. * NBA篮球运动员大数据分析决策支持系统:
18. * 基于NBA球员历史数据1970~2017年各种表现,全方位分析球员的技能,构建最强NBA篮球团队做数据分析支撑系统
19. * 曾经非常火爆的梦幻篮球是基于现实中的篮球比赛数据根据对手的情况制定游戏的先发阵容和比赛结果(也就是说比赛结果是由实际结果来决定),
20. * 游戏中可以管理球员,例如说调整比赛的阵容,其中也包括裁员、签入和交易等
21. *
22. * 而这里的大数据分析系统可以被认为是游戏背后的数据分析系统。
23. * 具体的数据关键的数据项如下所示:
24. * 3P:3分命中;
25. * 3PA:3分出手;
26. * 3P%:3分命中率;
27. * 2P:2分命中;
28. * 2PA:2分出手;
29. * 2P%:2分命中率;
30. * TRB:篮板球;
31. * STL:抢断;
32. * AST:助攻;
33. * BLT: 盖帽;
34. * FT: 罚球命中;
35. * TOV: 失误;
36. *
37. *
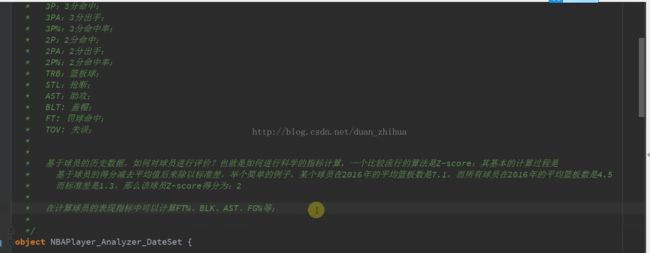
38. * 基于球员的历史数据,如何对球员进行评价?也就是如何进行科学的指标计算,一个比较流行的算法是Z-score:其基本的计算过程是
39. * 基于球员的得分减去平均值后来除以标准差,举个简单的例子,某个球员在2016年的平均篮板数是7.1,而所有球员在2016年的平均篮板数是4.5
40. * 而标准差是1.3,那么该球员Z-score得分为:2
41. *
42. * 在计算球员的表现指标中可以计算FT%、BLK、AST、FG%等;
43. *
44. *
45. * 具体如何通过Spark技术来实现呢?
46. * 第一步:数据预处理:例如去掉不必要的标题等信息;
47. * 第二步:数据的缓存:为加速后面的数据处理打下基础;
48. * 第三步:基础数据项计算:方差、均值、最大值、最小值、出现次数等等;
49. * 第四步:计算Z-score,一般会进行广播,可以提升效率;
50. * 第五步:基于前面四步的基础可以借助Spark SQL进行多维度NBA篮球运动员数据分析,可以使用SQL语句,也可以使用DataSet(我们在这里可能会
51. * 优先选择使用SQL,为什么呢?其实原因非常简单,复杂的算法级别的计算已经在前面四步完成了且广播给了集群,我们在SQL中可以直接使用)
52. * 第六步:把数据放在Redis或者DB中;
53. *
54. *
55. * Tips:
56. * 1,这里的一个非常重要的实现技巧是通过RDD计算出来一些核心基础数据并广播出去,后面的业务基于SQL去实现,既简单又可以灵活的应对业务变化需求,希望
57. * 大家能够有所启发;
58. * 2,使用缓存和广播以及调整并行度等来提升效率;
59. *
60. */
61. object NBABasketball_Analysis {
62.
63. def main(args: Array[String]) {
64. Logger.getLogger("org").setLevel(Level.ERROR)
65. var masterUrl = "local[4]"
66. if (args.length > 0) {
67. masterUrl = args(0)
68. }
69.
70. // Create a SparContext with the given master URL
71. /**
72. * Spark SQL默认情况下Shuffle的时候并行度是200,如果数据量不是非常多的情况下,设置200的Shuffle并行度会拖慢速度,
73. * 所以在这里我们根据实际情况进行了调整,因为NBA的篮球运动员的数据并不是那么多,这样做同时也可以让机器更有效的使用(例如内存等)
74. */
75. val conf = new SparkConf().setMaster(masterUrl).set("spark.sql.shuffle.partitions", "5").setAppName("FantasyBasketball")
76. val spark = SparkSession
77. .builder()
78. .appName("NBABasketball_Analysis")
79. .config(conf)
80. .getOrCreate()
81.
82. val sc = spark.sparkContext
83.
84. //********************
85. //SET-UP
86. //********************
87.
88.
89. val DATA_PATH = "data/NBABasketball"
90. //数据存在的目录
91. val TMP_PATH = "data/basketball_tmp"
92.
93. val fs = FileSystem.get(new Configuration())
94. fs.delete(new Path(TMP_PATH), true)
95.
96. //process files so that each line includes the year
97. for (i <- 1970 to 2016) {
98. println(i)
99. val yearStats = sc.textFile(s"${DATA_PATH}/leagues_NBA_$i*").repartition(sc.defaultParallelism)
100. yearStats.filter(x => x.contains(",")).map(x => (i, x)).saveAsTextFile(s"${TMP_PATH}/BasketballStatsWithYear/$i/")
101. }
102.
103.
104. //********************
105. //CODE
106. //********************
107. //Cut and Paste into the Spark Shell. Use :paste to enter "cut and paste mode" and CTRL+D to process
108. //spark-shell --master yarn-client
109. //********************
110.
111.
112. //********************
113. //Classes, Helper Functions + Variables
114. //********************
115. import org.apache.spark.sql.Row
116. import org.apache.spark.sql.types._
117. import org.apache.spark.util.StatCounter
118.
119. import scala.collection.mutable.ListBuffer
120.
121. //helper funciton to compute normalized value
122. def statNormalize(stat: Double, max: Double, min: Double) = {
123. val newmax = math.max(math.abs(max), math.abs(min))
124. stat / newmax
125. }
126.
127. //Holds initial bball stats + weighted stats + normalized stats
128. case class BballData(val year: Int, name: String, position: String,
129. age: Int, team: String, gp: Int, gs: Int, mp: Double,
130. stats: Array[Double], statsZ: Array[Double] = Array[Double](),
131. valueZ: Double = 0, statsN: Array[Double] = Array[Double](),
132. valueN: Double = 0, experience: Double = 0)
133.
134. //parse a stat line into a BBallDataZ object
135. def bbParse(input: String, bStats: scala.collection.Map[String, Double] = Map.empty,
136. zStats: scala.collection.Map[String, Double] = Map.empty): BballData = {
137. val line = input.replace(",,", ",0,")
138. val pieces = line.substring(1, line.length - 1).split(",")
139. val year = pieces(0).toInt
140. val name = pieces(2)
141. val position = pieces(3)
142. val age = pieces(4).toInt
143. val team = pieces(5)
144. val gp = pieces(6).toInt
145. val gs = pieces(7).toInt
146. val mp = pieces(8).toDouble
147.
148. val stats: Array[Double] = pieces.slice(9, 31).map(x => x.toDouble)
149. var statsZ: Array[Double] = Array.empty
150. var valueZ: Double = Double.NaN
151. var statsN: Array[Double] = Array.empty
152. var valueN: Double = Double.NaN
153.
154. if (!bStats.isEmpty) {
155. val fg: Double = (stats(2) - bStats.apply(year.toString + "_FG%_avg")) * stats(1)
156. val tp = (stats(3) - bStats.apply(year.toString + "_3P_avg")) / bStats.apply(year.toString + "_3P_stdev")
157. val ft = (stats(12) - bStats.apply(year.toString + "_FT%_avg")) * stats(11)
158. val trb = (stats(15) - bStats.apply(year.toString + "_TRB_avg")) / bStats.apply(year.toString + "_TRB_stdev")
159. val ast = (stats(16) - bStats.apply(year.toString + "_AST_avg")) / bStats.apply(year.toString + "_AST_stdev")
160. val stl = (stats(17) - bStats.apply(year.toString + "_STL_avg")) / bStats.apply(year.toString + "_STL_stdev")
161. val blk = (stats(18) - bStats.apply(year.toString + "_BLK_avg")) / bStats.apply(year.toString + "_BLK_stdev")
162. val tov = (stats(19) - bStats.apply(year.toString + "_TOV_avg")) / bStats.apply(year.toString + "_TOV_stdev") * (-1)
163. val pts = (stats(21) - bStats.apply(year.toString + "_PTS_avg")) / bStats.apply(year.toString + "_PTS_stdev")
164. statsZ = Array(fg, ft, tp, trb, ast, stl, blk, tov, pts)
165. valueZ = statsZ.reduce(_ + _)
166.
167. if (!zStats.isEmpty) {
168. val zfg = (fg - zStats.apply(year.toString + "_FG_avg")) / zStats.apply(year.toString + "_FG_stdev")
169. val zft = (ft - zStats.apply(year.toString + "_FT_avg")) / zStats.apply(year.toString + "_FT_stdev")
170. val fgN = statNormalize(zfg, (zStats.apply(year.toString + "_FG_max") - zStats.apply(year.toString + "_FG_avg"))
171. / zStats.apply(year.toString + "_FG_stdev"), (zStats.apply(year.toString + "_FG_min")
172. - zStats.apply(year.toString + "_FG_avg")) / zStats.apply(year.toString + "_FG_stdev"))
173. val ftN = statNormalize(zft, (zStats.apply(year.toString + "_FT_max") - zStats.apply(year.toString + "_FT_avg"))
174. / zStats.apply(year.toString + "_FT_stdev"), (zStats.apply(year.toString + "_FT_min")
175. - zStats.apply(year.toString + "_FT_avg")) / zStats.apply(year.toString + "_FT_stdev"))
176. val tpN = statNormalize(tp, zStats.apply(year.toString + "_3P_max"), zStats.apply(year.toString + "_3P_min"))
177. val trbN = statNormalize(trb, zStats.apply(year.toString + "_TRB_max"), zStats.apply(year.toString + "_TRB_min"))
178. val astN = statNormalize(ast, zStats.apply(year.toString + "_AST_max"), zStats.apply(year.toString + "_AST_min"))
179. val stlN = statNormalize(stl, zStats.apply(year.toString + "_STL_max"), zStats.apply(year.toString + "_STL_min"))
180. val blkN = statNormalize(blk, zStats.apply(year.toString + "_BLK_max"), zStats.apply(year.toString + "_BLK_min"))
181. val tovN = statNormalize(tov, zStats.apply(year.toString + "_TOV_max"), zStats.apply(year.toString + "_TOV_min"))
182. val ptsN = statNormalize(pts, zStats.apply(year.toString + "_PTS_max"), zStats.apply(year.toString + "_PTS_min"))
183. statsZ = Array(zfg, zft, tp, trb, ast, stl, blk, tov, pts)
184. // println("bbParse函数中打印statsZ: " + statsZ.foreach(println(_)) )
185. valueZ = statsZ.reduce(_ + _)
186. statsN = Array(fgN, ftN, tpN, trbN, astN, stlN, blkN, tovN, ptsN)
187. // println("bbParse函数中打印statsN: " + statsN.foreach(println(_)) )
188. valueN = statsN.reduce(_ + _)
189. }
190. }
191. BballData(year, name, position, age, team, gp, gs, mp, stats, statsZ, valueZ, statsN, valueN)
192. }
193.
194. //stat counter class -- need printStats method to print out the stats. Useful for transformations
195. //该类是一个辅助工具类,在后面编写业务代码的时候会反复使用其中的方法
196. class BballStatCounter extends Serializable {
197. val stats: StatCounter = new StatCounter()
198. var missing: Long = 0
199.
200. def add(x: Double): BballStatCounter = {
201. if (x.isNaN) {
202. missing += 1
203. } else {
204. stats.merge(x)
205. }
206. this
207. }
208.
209. def merge(other: BballStatCounter): BballStatCounter = {
210. stats.merge(other.stats)
211. missing += other.missing
212. this
213. }
214.
215. def printStats(delim: String): String = {
216. stats.count + delim + stats.mean + delim + stats.stdev + delim + stats.max + delim + stats.min
217. }
218.
219. override def toString: String = {
220. "stats: " + stats.toString + " NaN: " + missing
221. }
222. }
223.
224. object BballStatCounter extends Serializable {
225. def apply(x: Double) = new BballStatCounter().add(x) //在这里使用了Scala语言的一个编程技巧,借助于apply工厂方法,在构造该对象的时候就可以执行出结果
226. }
227.
228. //process raw data into zScores and nScores
229. def processStats(stats0: org.apache.spark.rdd.RDD[String], txtStat: Array[String],
230. bStats: scala.collection.Map[String, Double] = Map.empty,
231. zStats: scala.collection.Map[String, Double] = Map.empty): RDD[(String, Double)] = {
232. //parse stats
233. val stats1: RDD[BballData] = stats0.map(x => bbParse(x, bStats, zStats))
234.
235. //group by year
236. val stats2 = {
237. if (bStats.isEmpty) {
238. stats1.keyBy(x => x.year).map(x => (x._1, x._2.stats)).groupByKey()
239. } else {
240. stats1.keyBy(x => x.year).map(x => (x._1, x._2.statsZ)).groupByKey()
241. }
242. }
243.
244. //map each stat to StatCounter
245. val stats3 = stats2.map { case (x, y) => (x, y.map(a => a.map(b => BballStatCounter(b)))) }
246.
247. //merge all stats together
248. val stats4 = stats3.map { case (x, y) => (x, y.reduce((a, b) => a.zip(b).map { case (c, d) => c.merge(d) })) }
249.
250. //combine stats with label and pull label out
251. val stats5 = stats4.map { case (x, y) => (x, txtStat.zip(y)) }.map {
252. x =>
253. (x._2.map {
254. case (y, z) => (x._1, y, z)
255. })
256. }
257.
258. //separate each stat onto its own line and print out the Stats to a String
259. val stats6 = stats5.flatMap(x => x.map(y => (y._1, y._2, y._3.printStats(","))))
260.
261. //turn stat tuple into key-value pairs with corresponding agg stat
262. val stats7: RDD[(String, Double)] = stats6.flatMap { case (a, b, c) => {
263. val pieces = c.split(",")
264. val count = pieces(0)
265. val mean = pieces(1)
266. val stdev = pieces(2)
267. val max = pieces(3)
268. val min = pieces(4)
269. /* println("processStats函数的返回结果array" +
270. (a + "_" + b + "_" + "count", count.toDouble),
271. (a + "_" + b + "_" + "avg", mean.toDouble),
272. (a + "_" + b + "_" + "stdev", stdev.toDouble),
273. (a + "_" + b + "_" + "max", max.toDouble),
274. (a + "_" + b + "_" + "min", min.toDouble))*/
275.
276.
277. Array((a + "_" + b + "_" + "count", count.toDouble),
278. (a + "_" + b + "_" + "avg", mean.toDouble),
279. (a + "_" + b + "_" + "stdev", stdev.toDouble),
280. (a + "_" + b + "_" + "max", max.toDouble),
281. (a + "_" + b + "_" + "min", min.toDouble))
282. }
283. }
284. stats7
285. }
286.
287. //process stats for age or experience
288. def processStatsAgeOrExperience(stats0: org.apache.spark.rdd.RDD[(Int, Array[Double])], label: String): DataFrame = {
289.
290.
291. //group elements by age
292. val stats1: RDD[(Int, Iterable[Array[Double]])] = stats0.groupByKey()
293.
294. val stats2: RDD[(Int, Iterable[Array[BballStatCounter]])] = stats1.map {
295. case (x: Int, y: Iterable[Array[Double]]) =>
296. (x, y.map((z: Array[Double]) => z.map((a: Double) => BballStatCounter(a))))
297. }
298. //Reduce rows by merging StatCounter objects
299. val stats3: RDD[(Int, Array[BballStatCounter])] = stats2.map { case (x, y) => (x, y.reduce((a, b) => a.zip(b).map { case (c, d) => c.merge(d) })) }
300. //turn data into RDD[Row] object for dataframe
301. val stats4 = stats3.map(x => Array(Array(x._1.toDouble),
302. x._2.flatMap(y => y.printStats(",").split(",")).map(y => y.toDouble)).flatMap(y => y))
303. .map(x =>
304. Row(x(0).toInt, x(1), x(2), x(3), x(4), x(5), x(6), x(7), x(8),
305. x(9), x(10), x(11), x(12), x(13), x(14), x(15), x(16), x(17), x(18), x(19), x(20)))
306.
307. //create schema for age table
308. val schema = StructType(
309. StructField(label, IntegerType, true) ::
310. StructField("valueZ_count", DoubleType, true) ::
311. StructField("valueZ_mean", DoubleType, true) ::
312. StructField("valueZ_stdev", DoubleType, true) ::
313. StructField("valueZ_max", DoubleType, true) ::
314. StructField("valueZ_min", DoubleType, true) ::
315. StructField("valueN_count", DoubleType, true) ::
316. StructField("valueN_mean", DoubleType, true) ::
317. StructField("valueN_stdev", DoubleType, true) ::
318. StructField("valueN_max", DoubleType, true) ::
319. StructField("valueN_min", DoubleType, true) ::
320. StructField("deltaZ_count", DoubleType, true) ::
321. StructField("deltaZ_mean", DoubleType, true) ::
322. StructField("deltaZ_stdev", DoubleType, true) ::
323. StructField("deltaZ_max", DoubleType, true) ::
324. StructField("deltaZ_min", DoubleType, true) ::
325. StructField("deltaN_count", DoubleType, true) ::
326. StructField("deltaN_mean", DoubleType, true) ::
327. StructField("deltaN_stdev", DoubleType, true) ::
328. StructField("deltaN_max", DoubleType, true) ::
329. StructField("deltaN_min", DoubleType, true) :: Nil
330. )
331.
332. //create data frame
333. spark.createDataFrame(stats4, schema)
334. }
335.
336. //********************
337. //Processing + Transformations
338. //********************
339.
340.
341. //********************
342. //Compute Aggregate Stats Per Year
343. //********************
344.
345. //read in all stats
346. val stats = sc.textFile(s"${TMP_PATH}/BasketballStatsWithYear/*/*").repartition(sc.defaultParallelism)
347.
348. //filter out junk rows, clean up data entry errors as well
349. val filteredStats: RDD[String] = stats.filter(x => !x.contains("FG%")).filter(x => x.contains(","))
350. .map(x => x.replace("*", "").replace(",,", ",0,"))
351. filteredStats.cache()
352. println("NBA球员清洗以后的数据记录: ")
353. filteredStats.take(10).foreach(println)
354.
355. //process stats and save as map
356. val txtStat: Array[String] = Array("FG", "FGA", "FG%", "3P", "3PA", "3P%", "2P", "2PA", "2P%", "eFG%", "FT",
357. "FTA", "FT%", "ORB", "DRB", "TRB", "AST", "STL", "BLK", "TOV", "PF", "PTS")
358. println("NBA球员数据统计维度: ")
359. txtStat.foreach(println)
360. val aggStats: Map[String, Double] = processStats(filteredStats, txtStat).collectAsMap //基础数据项,需要在集群中使用,因此会在后面广播出去
361. println("NBA球员基础数据项aggStats MAP映射集: ")
362. aggStats.take(60).foreach { case (k, v) => println(" ( " + k + " , " + v + " ) ") }
363.
364. //collect rdd into map and broadcast
365. val broadcastStats: Broadcast[Map[String, Double]] = sc.broadcast(aggStats) //使用广播提升效率
366.
367.
368. //********************
369. //Compute Z-Score Stats Per Year
370. //********************
371.
372. //parse stats, now tracking weights
373. val txtStatZ = Array("FG", "FT", "3P", "TRB", "AST", "STL", "BLK", "TOV", "PTS")
374. val zStats: Map[String, Double] = processStats(filteredStats, txtStatZ, broadcastStats.value).collectAsMap
375. println("NBA球员Z-Score标准分zStats MAP映射集: ")
376. zStats.take(10).foreach { case (k, v) => println(" ( " + k + " , " + v + " ) ") }
377. //collect rdd into map and broadcast
378. val zBroadcastStats = sc.broadcast(zStats)
379.
380.
381. //********************
382. //Compute Normalized Stats Per Year
383. //********************
384.
385. //parse stats, now normalizing
386. val nStats: RDD[BballData] = filteredStats.map(x => bbParse(x, broadcastStats.value, zBroadcastStats.value))
387.
388. //map RDD to RDD[Row] so that we can turn it into a dataframe
389.
390. val nPlayer: RDD[Row] = nStats.map(x => {
391. val nPlayerRow: Row = Row.fromSeq(Array(x.name, x.year, x.age, x.position, x.team, x.gp, x.gs, x.mp)
392. ++ x.stats ++ x.statsZ ++ Array(x.valueZ) ++ x.statsN ++ Array(x.valueN))
393. //println( nPlayerRow.mkString(" "))
394. nPlayerRow
395. })
396.
397. //create schema for the data frame
398. val schemaN: StructType = StructType(
399. StructField("name", StringType, true) ::
400. StructField("year", IntegerType, true) ::
401. StructField("age", IntegerType, true) ::
402. StructField("position", StringType, true) ::
403. StructField("team", StringType, true) ::
404. StructField("gp", IntegerType, true) ::
405. StructField("gs", IntegerType, true) ::
406. StructField("mp", DoubleType, true) ::
407. StructField("FG", DoubleType, true) ::
408. StructField("FGA", DoubleType, true) ::
409. StructField("FGP", DoubleType, true) ::
410. StructField("3P", DoubleType, true) ::
411. StructField("3PA", DoubleType, true) ::
412. StructField("3PP", DoubleType, true) ::
413. StructField("2P", DoubleType, true) ::
414. StructField("2PA", DoubleType, true) ::
415. StructField("2PP", DoubleType, true) ::
416. StructField("eFG", DoubleType, true) ::
417. StructField("FT", DoubleType, true) ::
418. StructField("FTA", DoubleType, true) ::
419. StructField("FTP", DoubleType, true) ::
420. StructField("ORB", DoubleType, true) ::
421. StructField("DRB", DoubleType, true) ::
422. StructField("TRB", DoubleType, true) ::
423. StructField("AST", DoubleType, true) ::
424. StructField("STL", DoubleType, true) ::
425. StructField("BLK", DoubleType, true) ::
426. StructField("TOV", DoubleType, true) ::
427. StructField("PF", DoubleType, true) ::
428. StructField("PTS", DoubleType, true) ::
429. StructField("zFG", DoubleType, true) ::
430. StructField("zFT", DoubleType, true) ::
431. StructField("z3P", DoubleType, true) ::
432. StructField("zTRB", DoubleType, true) ::
433. StructField("zAST", DoubleType, true) ::
434. StructField("zSTL", DoubleType, true) ::
435. StructField("zBLK", DoubleType, true) ::
436. StructField("zTOV", DoubleType, true) ::
437. StructField("zPTS", DoubleType, true) ::
438. StructField("zTOT", DoubleType, true) ::
439. StructField("nFG", DoubleType, true) ::
440. StructField("nFT", DoubleType, true) ::
441. StructField("n3P", DoubleType, true) ::
442. StructField("nTRB", DoubleType, true) ::
443. StructField("nAST", DoubleType, true) ::
444. StructField("nSTL", DoubleType, true) ::
445. StructField("nBLK", DoubleType, true) ::
446. StructField("nTOV", DoubleType, true) ::
447. StructField("nPTS", DoubleType, true) ::
448. StructField("nTOT", DoubleType, true) :: Nil
449. )
450.
451. //create data frame
452. val dfPlayersT: DataFrame = spark.createDataFrame(nPlayer, schemaN)
453.
454. //save all stats as a temp table
455. dfPlayersT.createOrReplaceTempView("tPlayers")
456.
457. //calculate exp and zdiff, ndiff
458. val dfPlayers: DataFrame = spark.sql("select age-min_age as exp,tPlayers.* from tPlayers join" +
459. " (select name,min(age)as min_age from tPlayers group by name) as t1" +
460. " on tPlayers.name=t1.name order by tPlayers.name, exp ")
461. println("计算exp and zdiff, ndiff")
462. dfPlayers.show()
463. //save as table
464. dfPlayers.createOrReplaceTempView("Players")
465. //filteredStats.unpersist()
466.
467. //********************
468. //ANALYSIS
469. //********************
470. println("打印NBA球员的历年比赛记录: ")
471. dfPlayers.rdd.map(x =>
472. (x.getString(1), x)).filter(_._1.contains("A.C. Green")).foreach(println)
473.
474. val pStats: RDD[(String, Iterable[(Double, Double, Int, Int, Array[Double], Int)])] = dfPlayers.sort(dfPlayers("name"), dfPlayers("exp") asc).rdd.map(x =>
475. (x.getString(1), (x.getDouble(50), x.getDouble(40), x.getInt(2), x.getInt(3),
476. Array(x.getDouble(31), x.getDouble(32), x.getDouble(33), x.getDouble(34), x.getDouble(35),
477. x.getDouble(36), x.getDouble(37), x.getDouble(38), x.getDouble(39)), x.getInt(0))))
478. .groupByKey
479. pStats.cache
480.
481. println("**********根据NBA球员名字分组: ")
482. pStats.take(15).foreach(x => {
483. val myx2: Iterable[(Double, Double, Int, Int, Array[Double], Int)] = x._2
484. println("按NBA球员: " + x._1 + " 进行分组,组中元素个数为:" + myx2.size)
485. for (i <- 1 to myx2.size) {
486. val myx2size: Array[(Double, Double, Int, Int, Array[Double], Int)] = myx2.toArray
487. val mynext: (Double, Double, Int, Int, Array[Double], Int) = myx2size(i - 1)
488. println(i + " : " + x._1 + " , while " + mynext._1 + " , " + mynext._2 + " , "
489. + mynext._3 + " , " + mynext._4 + " , " + mynext._5.mkString(" || ") + " , "
490. + mynext._6)
491. }
492.
493. })
494.
495.
496. import spark.implicits._
497. //for each player, go through all the years and calculate the change in valueZ and valueN, save into two lists
498. //one for age, one for experience
499. //exclude players who played in 1980 from experience, as we only have partial data for them
500. val excludeNames: String = dfPlayers.filter(dfPlayers("year") === 1980).select(dfPlayers("name"))
501. .map(x => x.mkString).collect().mkString(",")
502.
503. val pStats1: RDD[(ListBuffer[(Int, Array[Double])], ListBuffer[(Int, Array[Double])])] = pStats.map { case (name, stats) =>
504. var last = 0
505. var deltaZ = 0.0
506. var deltaN = 0.0
507. var valueZ = 0.0
508. var valueN = 0.0
509. var exp = 0
510. val aList = ListBuffer[(Int, Array[Double])]()
511. val eList = ListBuffer[(Int, Array[Double])]()
512. stats.foreach(z => {
513. if (last > 0) {
514. deltaN = z._1 - valueN
515. deltaZ = z._2 - valueZ
516. } else {
517. deltaN = Double.NaN
518. deltaZ = Double.NaN
519. }
520. valueN = z._1
521. valueZ = z._2
522. last = z._4
523. aList += ((last, Array(valueZ, valueN, deltaZ, deltaN)))
524. if (!excludeNames.contains(z._1)) {
525. exp = z._6
526. eList += ((exp, Array(valueZ, valueN, deltaZ, deltaN)))
527. }
528. })
529. (aList, eList)
530. }
531.
532. pStats1.cache
533.
534.
535. println("按NBA球员的年龄及经验值进行统计: ")
536. pStats1.take(10).foreach(x => {
537. //pStats1: RDD[(ListBuffer[(Int, Array[Double])], ListBuffer[(Int, Array[Double])])]
538. for (i <- 1 to x._1.size) {
539. println("年龄:" + x._1(i - 1)._1 + " , " + x._1(i - 1)._2.mkString("||") +
540. " 经验: " + x._2(i - 1)._1 + " , " + x._2(i - 1)._2.mkString("||"))
541. }
542. })
543.
544.
545. //********************
546. //compute age stats
547. //********************
548.
549. //extract out the age list
550. val pStats2: RDD[(Int, Array[Double])] = pStats1.flatMap { case (x, y) => x }
551.
552. //create age data frame
553. val dfAge: DataFrame = processStatsAgeOrExperience(pStats2, "age")
554. dfAge.show()
555. //save as table
556. dfAge.createOrReplaceTempView("Age")
557.
558. //extract out the experience list
559. val pStats3: RDD[(Int, Array[Double])] = pStats1.flatMap { case (x, y) => y }
560.
561. //create experience dataframe
562. val dfExperience: DataFrame = processStatsAgeOrExperience(pStats3, "Experience")
563. dfExperience.show()
564. //save as table
565. dfExperience.createOrReplaceTempView("Experience")
566.
567. pStats1.unpersist()
568.
569. //while(true){}
570. }
571.
572. }