Harvard NLP The Annotated Transformer 学习之代码
Harvard NLP The Annotated Transformer 学习代码:
- The Annotated Transformer 论文:

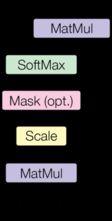
- 注意力模型:
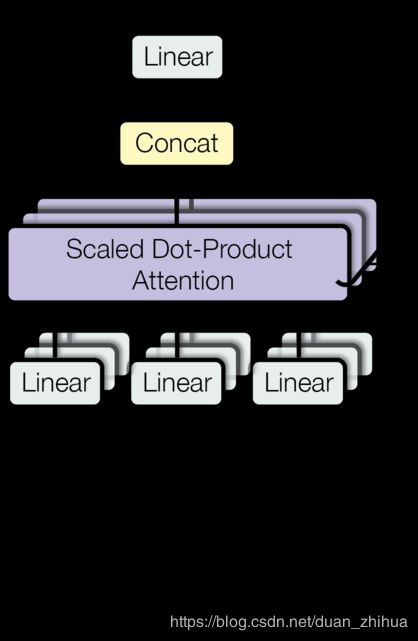
- 多注意力模型结构:
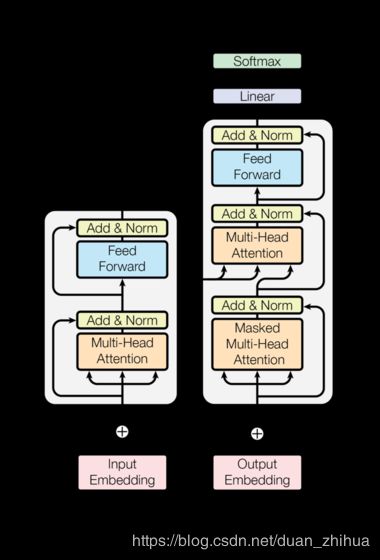
- Transformer 编码器、解码器结构:
Transformer 代码如下:
# -*- coding: utf-8 -*-
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
from torch.autograd import Variable
import matplotlib.pyplot as plt
import seaborn
seaborn.set_context(context="talk")
class EncoderDecoder(nn.Module):
"""
标准编码器-解码器结构,本案例及其他各模型的基础。
"""
def __init__(self,encoder,decoder,src_embed,tgt_embed,generator):
super(EncoderDecoder,self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator =generator
def forward(self,src,tgt,src_mask,tgt_mask):
"处理屏蔽的源序列与目标序列"
return self.decode(self.encode(src,src_mask),src_mask,tgt,tgt_mask)
def encode(self,src,src_mask):
return self.encoder(self.src_embed(src),src_mask)
def decode(self,memory,src_mask,tgt,tgt_mask):
return self.decoder(self.tgt_embed(tgt),memory,src_mask,tgt_mask)
class Generator(nn.Module):
"定义标准linear + softmax 步骤"
def __init__(self,d_model,vocab):
super(Generator,self).__init__()
self.proj = nn.Linear(d_model,vocab)
def forward(self,x):
return F.log_softmax(self.proj(x),dim =-1)
# =============================================================================
#
# Encoder 编码器
#
# =============================================================================
#论文中的编码器由N=6个相同层的堆栈组成
def clones(module,N):
"生成N个相同的层"
return nn.ModuleList([copy.deepcopy(module) for _ in range(N) ])
class Encoder(nn.Module):
"核心编码器是N层堆叠"
def __init__(self,layer,N):
super(Encoder,self).__init__()
self.layers=clones(layer,N)
self.norm = LayerNorm(layer.size)
def forward(self,x,mask):
"依次将输入的数据(及屏蔽数据)通过每个层"
for layer in self.layers:
x=layer(x,mask)
return self.norm(x)
#在两个子层中的每一个子层使用一个残差连接,然后进行层归一化
class LayerNorm(nn.Module):
"构建层归一化模块"
def __init__(self,features,eps=1e-6):
super(LayerNorm,self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps=eps
def forward(self,x):
mean =x.mean(-1,keepdim=True)
std = x.std(-1,keepdim=True)
return self.a_2*(x - mean ) /(std + self.eps)+self.b_2
# 每一个子层的输出为 LayerNorm(x+Sublayer(x)),其中 Sublayer(x) 是子层自己实现的函数,在子层输入和归一化之前完成每一个子层输出的dropout。
# 为了实现残差连接,模型中的所有子层以及嵌入层的输出维度都是dmodel=512。
class SublayerConnection(nn.Module):
"""
层归一化之后的残差连接。
注意:为了简化代码,归一化是第一个,而不是最后一个。
"""
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self,x,sublayer):
"将残差连接应用于相同大小的任何子层。"
return x+self.dropout(sublayer(self.norm(x)))
#每层有两个子层:第一层是多头自注意机制,第二层是一个简单的、位置导向的、全连接的前馈网络。
class EncoderLayer(nn.Module):
"编码器由以下的自注意力和前馈网络组成"
def __init__(self,size,self_attn,feed_forward,dropout):
super(EncoderLayer,self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size,dropout),2)
self.size =size
def forward(self,x,mask):
"按照论文中的图1(左)的方式进行连接"
x = self.sublayer[0](x,lambda x:self.self_attn(x,x,x,mask))
return self.sublayer[1](x,self.feed_forward)
# =============================================================================
#
# Decoder 解码器
#
# =============================================================================
#解码器也由一个N=6个相同层的堆栈组成。
class Decoder(nn.Module):
"带屏蔽的通用N层解码器"
def __init__(self,layer,N):
super(Decoder,self).__init__()
self.layers = clones(layer,N)
self.norm = LayerNorm(layer.size)
def forward(self,x,memory,src_mask,tgt_mask):
for layer in self.layers:
x =layer(x,memory,src_mask,tgt_mask)
return self.norm(x)
#在每个编码器层中的两个子层外,解码器还插入第三个子层,该子层在编码器堆栈的输出上执行多头关注。与编码器类似,使用残差连接解码器的每个子层,然后进行层归一化。
class DecoderLayer(nn.Module):
"解码器由以下的自注意力、源注意力和前馈网络组成"
def __init__(self,size,self_attn,src_attn,feed_forward,dropout):
super(DecoderLayer,self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size,dropout),3)
def forward (self,x,memory,src_mask,tgt_mask):
"按照论文中的图1(右)的方式进行连接"
m = memory
x = self.sublayer[0](x,lambda x:self.self_attn(x,x,x,tgt_mask))
x = self.sublayer[1](x,lambda x:self.src_attn(x,m,m,src_mask))
return self.sublayer[2](x,self.feed_forward)
def subsequent_mask(size):
"屏蔽后续位置"
attn_shape = (1,size,size)
subsequent_mask = np.triu(np.ones(attn_shape),k=1).astype('uint8')
return torch.from_numpy(subsequent_mask) == 0
plt.figure(figsize=(5,5))
plt.imshow(subsequent_mask(20)[0])
# =============================================================================
#
# Attention 注意力
#
# =============================================================================
# 公式:Attention(Q,K,V)=softmax(Q K^T /√dk ) V
def attention(query,key,value,mask=None,dropout=None):
"计算'可缩放点乘注意力'"
d_k = query.size(-1)
scores = torch.matmul(query,key.transpose(-2,-1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores,dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn,value),p_attn
#多头注意力模型
class MultiHeadedAttention(nn.Module):
def __init__(self,h,d_model, dropout=0.1):
"设置模型大小和注意力头部数量"
super(MultiHeadedAttention,self).__init__()
assert d_model % h ==0
#假设 d_v 等于 d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model,d_model),4) # 对应 Q,K,V 3次线性变换 + 最终的1次线性变换
self.attn =None
self.dropout = nn.Dropout(p=dropout)
def forward(self,query,key,value,mask=None):
"实现论文中的第2张图"
if mask is not None:
#同样的屏蔽适用于所有h型头
mask = mask.unsqueeze(1)
nbatches = query.size(0)
#1)批量执行所有线性变换 d_model => h x d_k
query,key,value = [ l(x).view(nbatches,-1,self.h,self.d_k).transpose(1,2)
for l,x in zip (self.linears,(query,key,value))]
#2)将注意力集中在批量的所有投射向量上
x,self.attn =attention(query,key,value,mask=mask,dropout=self.dropout)
#3)使用view方法做Concat然后做最终的线性变换。
x = x.transpose(1,2).contiguous().view(nbatches,-1,self.h*self.d_k)
return self.linears[-1](x)
# =============================================================================
#
# Position-wise Feed-Forward Networks 位置前馈网络
#
# =============================================================================
#计算公式:FFN(x)=max(0,xW1+b1)W2+b2 论文中 输入、输出的维度dmodel=512, 内部隐藏层的维度 dff=2048.
class PositionwiseFeedForward(nn.Module):
"实现FFN方程"
def __init__(self,d_model,d_ff,dropout=0.1):
super(PositionwiseFeedForward,self).__init__()
self.w_1 = nn.Linear(d_model,d_ff)
self.w_2 = nn.Linear(d_ff,d_model)
self.dropout = nn.Dropout(dropout)
def forward(self,x):
return self.w_2(self.dropout(F.relu(self.w_1(x))))
# =============================================================================
#
# Embeddings and Softmax : 嵌入和SoftMax
#
# =============================================================================
class Embeddings(nn.Module):
def __init__(self,d_model,vocab):
super(Embeddings,self).__init__()
self.lut = nn.Embedding(vocab,d_model)
self.d_model = d_model
def forward(self,x):
return self.lut(x.long()) * math.sqrt(self.d_model)
# =============================================================================
#
# Positional Encoding : 位置编码
#
# =============================================================================
class PositionalEncoding(nn.Module):
"实现位置编码函数"
def __init__(self,d_model,dropout,max_len=5000):
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
#计算位置编码
pe = torch.zeros(max_len,d_model)
position = torch.arange(0,max_len).unsqueeze(1).float()
div_term = torch.exp((torch.arange(0,d_model,2)*-math.log(10000) /d_model).float())
pe[:,0::2] = torch.sin(position * div_term)
pe[:,1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe',pe)
def forward (self,x):
x =x +Variable(self.pe[:,:x.size(1)],requires_grad =False)
return self.dropout(x)
#位置编码将根据位置添加一个正弦波,波的频率和偏移对于每个维度都是不同的。
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
y = pe.forward(Variable(torch.zeros(1, 10 , 20)))
plt.scatter(np.arange(10 ), y[0, :,1].data.numpy())
plt.legend(["dim %d"%p for p in [4,5,6,7]])
# =============================================================================
#
# Full Model : 整体模型
#
# =============================================================================
#定义一个函数,它接受超参数并生成完整的模型。
def make_model(src_vocab,tgt_vocab,N=6,d_model=512,d_ff=2048,h=8,dropout=0.1):
"从超参数构造模型"
c = copy.deepcopy
attn = MultiHeadedAttention(h,d_model)
ff = PositionwiseFeedForward(d_model,d_ff,dropout)
position = PositionalEncoding(d_model,dropout)
model = EncoderDecoder(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N),
Decoder(DecoderLayer(d_model, c(attn), c(attn),
c(ff), dropout), N),
nn.Sequential(Embeddings(d_model, src_vocab), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab), c(position)),
Generator(d_model, tgt_vocab))
#从代码来看,使用 Glorot / fan_avg初始化参数很重要。
for p in model.parameters():
if p.dim()>1:
nn.init.xavier_uniform_(p)
return model
#小例子模型
tmp_model = make_model(10, 10, 2)
print(tmp_model)
# =============================================================================
#
# Training : 模型训练
#
# =============================================================================
#Batches and Masking
class Batch:
"此对象用于在训练时进行已屏蔽的批数据处理"
def __init__(self,src,trg=None,pad=0):
self.src = src
self.src_mask = (src != pad).unsqueeze(-2)
if trg is not None:
self.trg = trg[:, :-1]
self.trg_y = trg[:, 1:]
self.trg_mask = \
self.make_std_mask(self.trg, pad)
self.ntokens = (self.trg_y != pad).data.sum()
@staticmethod
def make_std_mask(tgt,pad):
"创建一个mask来隐藏填充和将来的单词"
tgt_mask = (tgt != pad ).unsqueeze(-2)
tgt_mask = tgt_mask & Variable(
subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))
return tgt_mask
#接下来,我们创建一个通用的训练和评分功能来跟踪损失。我们传递一个通用的损失计算函数,该函数还处理参数更新。
def run_epoch(data_iter,model,loss_compute):
"标准的训练及日志函数"
start = time.time()
total_tokens = 0
total_loss = 0.0
tokens = 0
for i,batch in enumerate(data_iter):
out = model.forward(batch.src,batch.trg,
batch.src_mask,batch.trg_mask)
loss = loss_compute(out,batch.trg_y,batch.ntokens)
#print("ok",loss)
total_loss += loss
total_tokens += batch.ntokens
tokens += batch.ntokens
if i % 50 == 1:
elapsed =time.time() - start
print("Epoch Step: %d Loss: %f Tokens per Sec: %f" %
(i,loss /batch.ntokens,tokens /elapsed))
start =time.time()
tokens = 0
#print("ok",total_loss,total_tokens)
return (total_loss /total_tokens).numpy()
#我们将使用torch 文本进行批处理。在TorchText函数中创建批次,确保填充最大批次大小不超过阈值(如果我们有8个GPU,则为25000)。
global max_src_in_batch,max_tgt_in_batch
def batch_size_fn(new,count,sofar):
"持续扩大批处理并计算标识+填充的总数"
global max_src_in_batch,max_tgt_in_batch
if count == 1:
max_src_in_batch = 0
max_tgt_in_batch = 0
max_src_in_batch = max(max_src_in_batch,len(new.src))
max_tgt_in_batch = max(max_tgt_in_batch,len(new.src) + 2)
src_elements = count * max_src_in_batch
tgt_elements = count * max_tgt_in_batch
return max(src_elements,tgt_elements)
# =============================================================================
#
# Optimizer : 优化器 使用Adam优化器
#
# =============================================================================
class NoamOpt:
"实现学习率的优化包装器"
def __init__(self, model_size, factor, warmup, optimizer):
self.optimizer = optimizer
self._step = 0
self.warmup = warmup
self.factor = factor
self.model_size = model_size
self._rate = 0
def step(self):
"Update parameters and rate"
self._step += 1
rate = self.rate()
for p in self.optimizer.param_groups:
p['lr'] = rate
self._rate = rate
self.optimizer.step()
def rate(self, step = None):
"实现学习率 lrate"
if step is None:
step = self._step
return self.factor * \
(self.model_size ** (-0.5) *
min(step ** (-0.5), step * self.warmup ** (-1.5)))
def get_std_opt(model):
return NoamOpt(model.src_embed[0].d_model, 2, 4000,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
#该模型的曲线示例适用于不同的模型尺寸和优化超参数。
#lrate超参数的三个设置
opts = [NoamOpt(512, 1, 4000, None),
NoamOpt(512, 1, 8000, None),
NoamOpt(256, 1, 4000, None)]
plt.figure()
plt.plot(np.arange(1, 20000), [[opt.rate(i) for opt in opts] for i in range(1, 20000)])
plt.legend(["512:4000", "512:8000", "256:4000"])
None
# =============================================================================
#
# Regularization : 正则化
#
# =============================================================================
class LabelSmoothing(nn.Module):
"实现平滑标签"
def __init__(self,size,padding_idx,smoothing =0.0):
super(LabelSmoothing,self).__init__()
self.criterion = nn.KLDivLoss(size_average = False)
self.padding_idx = padding_idx
self.confidence = 1.0 -smoothing
self.smoothing =smoothing
self.size = size
self.true_dist =None
def forward(self,x,target):
assert x.size(1) == self.size
true_dist = x.data.clone()
true_dist.fill_(self.smoothing /(self.size -2 ))
true_dist.scatter_(1,target.long().data.unsqueeze(1),self.confidence)
true_dist[:,self.padding_idx] = 0
mask =torch.nonzero(target.data == self.padding_idx)
if mask.dim() > 0:
true_dist.index_fill_(0,mask.squeeze(),0.0)
self.true_dist = true_dist
return self.criterion(x,Variable(true_dist,requires_grad =False))
#例子 label smoothing.
crit = LabelSmoothing(5, 0, 0.4)
predict = torch.FloatTensor([[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0],
[0, 0.2, 0.7, 0.1, 0]])
v = crit(Variable(predict.log()),
Variable(torch.LongTensor([2, 1, 0])))
# 显示预期的目标分布。
plt.figure( )
plt.imshow(crit.true_dist)
None
#如果模型对给定的选择非常有信心,标签平滑实际上开始惩罚模型
crit = LabelSmoothing(5, 0, 0.1)
def loss(x):
d = x + 3 * 1
predict = torch.FloatTensor([[0, x / d, 1 / d, 1 / d, 1 / d],
])
#print(predict)
return crit(Variable(predict.log()),
Variable(torch.LongTensor([1]))).item()
plt.figure( )
plt.plot(np.arange(1, 100), [loss(x) for x in range(1, 100)])
None
#第一个例子
def data_gen(V,batch,nbatches):
"为src-tgt复制任务生成随机数据"
for i in range(nbatches):
data = torch.from_numpy(np.random.randint(1,V,size = (batch,10)))
data[:,0] =1
src = Variable(data,requires_grad = False)
tgt = Variable(data,requires_grad = False)
yield Batch(src,tgt,0)
#损失计算
class SimpleLossCompute:
"一个简单的损失计算和训练函数"
def __init__(self,generator,criterion,opt =None):
self.generator = generator
self.criterion = criterion
self.opt = opt
def __call__(self,x,y,norm):
x =self.generator(x)
loss = self.criterion(x.contiguous().view(-1,x.size(-1)),y.contiguous().view(-1)) /norm
loss.backward()
if self.opt is not None:
self.opt.step()
self.opt.optimizer.zero_grad()
return loss.data.item()*norm
#贪婪解码
V =11
criterion =LabelSmoothing(size =V,padding_idx =0,smoothing =0.0)
model =make_model(V,V,N=2)
model_opt = NoamOpt(model.src_embed[0].d_model, 1, 400,
torch.optim.Adam(model.parameters(), lr=0, betas=(0.9, 0.98), eps=1e-9))
for epoch in range(10):
model.train()
run_epoch(data_gen(V,30,20),model,
SimpleLossCompute(model.generator,criterion,model_opt))
model.eval()
print(run_epoch(data_gen(V, 30, 5), model,
SimpleLossCompute(model.generator, criterion, None)))
#为了简单起见,此代码使用贪婪解码来预测翻译。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
ys = torch.ones(1, 1).fill_(start_symbol).type_as(src.data)
for i in range(max_len-1):
out = model.decode(memory, src_mask,
Variable(ys),
Variable(subsequent_mask(ys.size(1))
.type_as(src.data)))
prob = model.generator(out[:, -1])
_, next_word = torch.max(prob, dim = 1)
next_word = next_word.data[0]
ys = torch.cat([ys,
torch.ones(1, 1).type_as(src.data).fill_(next_word)], dim=1)
return ys
model.eval()
src = Variable(torch.LongTensor([[1,2,3,4,5,6,7,8,9,10]]) )
src_mask = Variable(torch.ones(1, 1, 10) )
print(greedy_decode(model, src, src_mask, max_len=10, start_symbol=1))
https://github.com/duanzhihua/annotated-transformer