基于近期学习的 Docker 内容,整理与 Docker 网络相关的知识。实验环境:Centos 7.4
Docker 版本如下:
Client:
Version: 18.03.1-ce
API version: 1.37
Go version: go1.9.5
Git commit: 9ee9f40
Built: Thu Apr 26 07:20:16 2018
OS/Arch: linux/amd64
Experimental: false
Orchestrator: swarm
Server:
Engine:
Version: 18.03.1-ce
API version: 1.37 (minimum version 1.12)
Go version: go1.9.5
Git commit: 9ee9f40
Built: Thu Apr 26 07:23:58 2018
OS/Arch: linux/amd64
Experimental: false1. Linux 网络命名空间与 Veth
1.1 Linux 网络命名空间
以下摘自 linux 网络命名空间 Network namespaces - CSDN博客 :
Linux命名空间是一个相对较新的内核功能,对于实现容器至关重要。 命名空间将全局系统资源包装到一个抽象中,该抽象只会与命名空间中的进程绑定,从而提供资源隔离。Linux内核提供了6种类型的命名空间:pid,net,mnt,uts,ipc和user。网络命名空间为命名空间中的所有进程提供了全新的网络堆栈。 这包括网络接口,路由表和iptables规则。
我们可以使用:
ip netns list查看当前系统中存在的网络空间
或者通过以下指令增加或删除:
# 增加
ip netns add ns1
# 删除
ip netns delete ns1这里,我们使用如下指令,查看 ns1 网络命名空间中网络情况:
[root@localhost vagrant]# ip netns exec ns1 ip a
1: lo: mtu 65536 qdisc noop state DOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 可以看到,在新创建的 ns1 中,仅存在一个处于 DOWN 状态的本地回环端口。
此时,我们使用以下指令执行时,会发现网络不通:
[root@localhost vagrant]# ip netns exec ns1 ping localhost -c 4
connect: 网络不可达此时我们需要借助 ip link,将 lo 端口 UP 起来:
ip netns exec ns1 set dev lo up此时,对本地端口的 ping 请求就可达了:
[root@localhost vagrant]# ip netns exec ns1 ping localhost -c 4
PING localhost (127.0.0.1) 56(84) bytes of data.
64 bytes from localhost (127.0.0.1): icmp_seq=1 ttl=64 time=0.031 ms
64 bytes from localhost (127.0.0.1): icmp_seq=2 ttl=64 time=0.060 ms
64 bytes from localhost (127.0.0.1): icmp_seq=3 ttl=64 time=0.070 ms
64 bytes from localhost (127.0.0.1): icmp_seq=4 ttl=64 time=0.036 ms
--- localhost ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3004ms
rtt min/avg/max/mdev = 0.031/0.049/0.070/0.017 ms注:ip link 指令可以查到本机网络接口情况,这一指令在 Veth 中还会提到。
1.2 Veth
关于 Veth 的特点,以下摘自:Linux虚拟网络设备之veth - Linux程序员 - SegmentFault 思否:
veth和其它的网络设备都一样,一端连接的是内核协议栈。
veth设备是成对出现的,另一端两个设备彼此相连
一个设备收到协议栈的数据发送请求后,会将数据发送到另一个设备上去。
这里,我们再新建一个 ns2 的网络命名空间,并通过 Veth,实现 ns1 和 ns2 之间的连通,步骤如下:
1.2.1 准备 ns1 和 ns2 网络命名空间
首先,我们通过:
ip netns add ns2创建 ns2 网络命名空间。
注:也可仿照上述 ns1 的做法,将 ns2 中 lo 置于 UP 状态。
1.2.2 创建 Veth pair
下面,我们执行如下指令,创建 Veth pair:
ip link add veth-ns1 type veth peer name veth-ns2之后,我们可以通过 ip link 指令,看到接口列表中新增了我们刚刚添加的那个 veth pair:
[root@localhost vagrant]# ip link
...
4: veth-ns2@veth-ns1: mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 8e:3c:d3:98:29:9d brd ff:ff:ff:ff:ff:ff
5: veth-ns1@veth-ns2: mtu 1500 qdisc noop state DOWN mode DEFAULT qlen 1000
link/ether 92:8a:2f:d6:e0:72 brd ff:ff:ff:ff:ff:ff 1.2.3 将 Veth pair 两端分别加入到 ns1 和 ns2
执行以下指令:
# 将 Veth pair 的 veth-ns1 添加到 ns1
ip link set veth-ns1 netns ns1
# 将 Veth pair 的 veth-ns2 添加到 ns2
ip link set veth-ns2 netns ns2此时,我们再次执行 ip link,会发现,之前创建 Veth pair 的两端已经分别存在于 ns1 和 ns2 中:
ip netns exec ns1 ip link
ip netns exec ns2 ip link1.2.4 为 Veth pair 的两端分别配置 IP 地址
执行以下指令:
ip netns exec ns1 ip addr add 192.168.1.1/24 dev veth-ns1
ip netns exec ns2 ip addr add 192.168.1.2/24 dev veth-ns2注意,这一步一定要在 Veth pair 的两端加入到 ns1、ns2 之后进行。
1.2.5 将 Veth pair 的两端置为 UP 状态
执行以下指令:
ip netns exec ns1 ip link set dev veth-ns1 up
ip netns exec ns2 ip link set dev veth-ns2 up此时,我们便可以通过 ip a 看到目前该网络空间的情况了:
###### ns1 ######
[root@localhost vagrant]# ip netns exec ns1 ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
5: veth-ns1@if4: mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 92:8a:2f:d6:e0:72 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet 192.168.1.1/24 scope global veth-ns1
valid_lft forever preferred_lft forever
inet6 fe80::908a:2fff:fed6:e072/64 scope link
valid_lft forever preferred_lft forever
###### ns1 ######
[root@localhost vagrant]# ip netns exec ns2 ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
4: veth-ns2@if5: mtu 1500 qdisc noqueue state UP qlen 1000
link/ether 8e:3c:d3:98:29:9d brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.1.2/24 scope global veth-ns2
valid_lft forever preferred_lft forever
inet6 fe80::8c3c:d3ff:fe98:299d/64 scope link
valid_lft forever preferred_lft forever 1.2.6 检验连通
通过两端互 ping 的方式,检测连通性:
ns1 -> ns2
[root@localhost vagrant]# ip netns exec ns1 ping 192.168.1.2 -c 4
PING 192.168.1.2 (192.168.1.2) 56(84) bytes of data.
64 bytes from 192.168.1.2: icmp_seq=1 ttl=64 time=0.037 ms
64 bytes from 192.168.1.2: icmp_seq=2 ttl=64 time=0.040 ms
64 bytes from 192.168.1.2: icmp_seq=3 ttl=64 time=0.046 ms
64 bytes from 192.168.1.2: icmp_seq=4 ttl=64 time=0.044 ms
--- 192.168.1.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3000ms
rtt min/avg/max/mdev = 0.037/0.041/0.046/0.008 msns2 -> ns1
[root@localhost vagrant]# ip netns exec ns2 ping 192.168.1.1 -c 4
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.030 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.038 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.068 ms
64 bytes from 192.168.1.1: icmp_seq=4 ttl=64 time=0.067 ms
--- 192.168.1.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3006ms
rtt min/avg/max/mdev = 0.030/0.050/0.068/0.019 ms1.2.7 总结
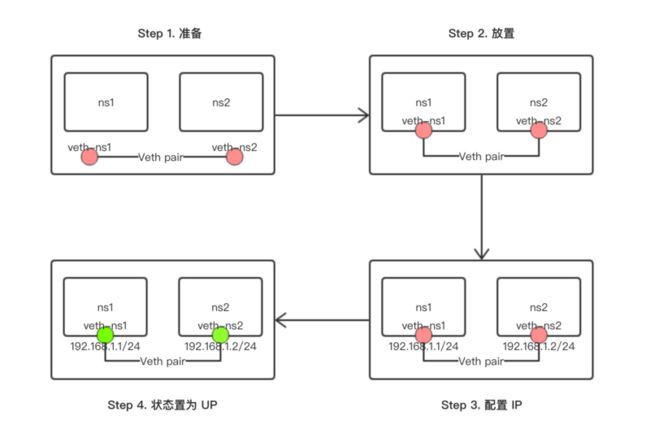
以上过程的核心步骤示意如下:
2. Docker bridge 型网络 与 bridge0
2.1 bridge 连通实验
执行 ip link,我们可以看到:
[root@localhost vagrant]# ip link
...
3: docker0: mtu 1500 qdisc noqueue state UP mode DEFAULT
link/ether 02:42:7f:68:8e:01 brd ff:ff:ff:ff:ff:ff 这里存在一个 docker0,这在 Docker bridge 型网络中起到至关重要的作用。
注意:根据 Docker 官方文档:Networking features in Docker for Mac | Docker Documentation,在 Mac OS 中是没有 bridge0 的。推荐使用 Centos 系统进行试验。
接着,我们使用如下指令创建一个 Container,用以观察容器 bridge 型网络的实现方式:
docker run -d --name box1 busybox /bin/sh -c "while true; do sleep 3600; done;"注:
- 使用一个死循环指令可以使得容器不会立刻停止;
- Docker 容器默认的网络为 bridge
然后执行 ip link 观察变化,可以发现,列表中多出了如下部分:
[root@localhost vagrant]# ip link
...
11: veth4f19367@if10: mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT
link/ether 42:01:42:6c:52:5a brd ff:ff:ff:ff:ff:ff link-netnsid 0 接着,为了观察网络桥接情况,我们需要安装一个软件:
yum install bridge-utils然后使用:
[root@localhost vagrant]# brctl show
bridge name bridge id STP enabled interfaces
docker0 8000.02427f688e01 no veth4f19367可以看到,创建 box1 容器后,新增的 Veth 通过桥接连接到了 docker0 上,使得容器和宿主机之间可以互相连通。
为了检测连通性,首先我们执行:
[root@localhost vagrant]# ip a
...
3: docker0: mtu 1500 qdisc noqueue state UP
link/ether 02:42:7f:68:8e:01 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:7fff:fe68:8e01/64 scope link
valid_lft forever preferred_lft forever
...
得到宿主机的 IP 为 172.17.0.1/16
然后通过:
[root@localhost vagrant]# docker exec box1 ip a
...
10: eth0@if11: mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever 得到 box1 这一容器的 IP 为 172.17.0.2/16
之后,便可以通过以下方式检测二者互相的连通性:
宿主机( 172.17.0.1 )-> 容器( 172.17.0.2 )
[root@localhost vagrant]# ping 172.17.0.2 -c 4
PING 172.17.0.2 (172.17.0.2) 56(84) bytes of data.
64 bytes from 172.17.0.2: icmp_seq=1 ttl=64 time=0.049 ms
64 bytes from 172.17.0.2: icmp_seq=2 ttl=64 time=0.054 ms
64 bytes from 172.17.0.2: icmp_seq=3 ttl=64 time=0.057 ms
64 bytes from 172.17.0.2: icmp_seq=4 ttl=64 time=0.082 ms
--- 172.17.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3001ms
rtt min/avg/max/mdev = 0.049/0.060/0.082/0.014 ms容器( 172.17.0.2 )-> 宿主机( 172.17.0.1 )
[root@localhost vagrant]# docker exec box1 ping 172.17.0.1 -c 4
PING 172.17.0.1 (172.17.0.1): 56 data bytes
64 bytes from 172.17.0.1: seq=0 ttl=64 time=0.068 ms
64 bytes from 172.17.0.1: seq=1 ttl=64 time=0.258 ms
64 bytes from 172.17.0.1: seq=2 ttl=64 time=0.084 ms
64 bytes from 172.17.0.1: seq=3 ttl=64 time=0.087 ms
--- 172.17.0.1 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.068/0.124/0.258 ms同理,我们可以再创建一个 box2 容器,检测 box1 与 box2 之间的连通性。由于方法相同,这里简述如下:
# 创建 box2 容器
docker run -d --name box2 busybox /bin/sh -c "while true; do sleep 3600; done;"
# 【省略】通过 ip a 分别查询 box1 和 box2 的 ip
# 连通测试 box1 -> box2
docker exec box1 ping 172.17.0.3 -c 4
# 连通测试 box2 -> box1
docker exec box2 ping 172.17.0.2 -c 42.2 总结
如上,Docker 中实现 bridge 型网络互连的方式如下图:

此外,bridge 型网络中,容器与公网连通的方式如下:
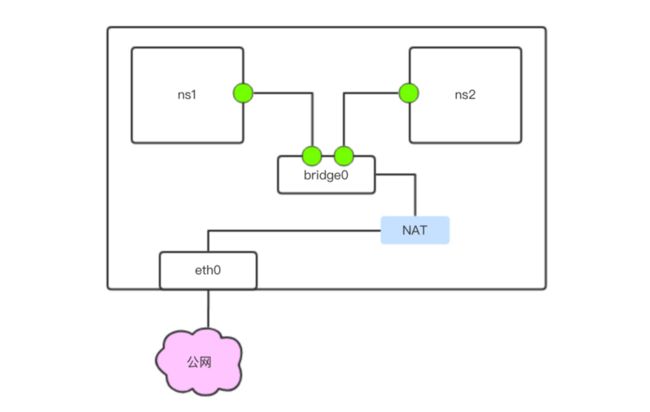
注:bridge 指的是网络类型,bridge0 是接口名。
3. 以容器名进行网络连接
在 Docker 容器中,以 IP 方式进行彼此连通,会使得很多业务场景首先,我们更期望使用域名或者别名进行网络访问,从而在 IP 地址变化时,依然保证系统各模块的稳定( 每次创建容器,其 IP 地址不是恒定的 )。
由此,我们可以使用如下方式实现这一功能。
首先,我们需要将先前启动的容器停止并删除:
docker rm -f $(docker ps -aq)注:这一指令会停止并删除所有容器。
3.1 Docker link
此方法旨在使用 docker 启动时的 --link 参数,步骤如下:
3.1.1 准备 box1、box2 两个容器
docker run -d --name box1 busybox /bin/sh -c "while true; do sleep 3600; done;"
# 注意,这里添加了 --link box1 参数
docker run -d --name box2 --link box1 busybox /bin/sh -c "while true; do sleep 3600; done;"3.1.2 连通测试——以 IP
box1 -> box2
[root@localhost vagrant]# docker exec box1 ping 172.17.0.3 -c 4
PING 172.17.0.3 (172.17.0.3): 56 data bytes
64 bytes from 172.17.0.3: seq=0 ttl=64 time=0.071 ms
64 bytes from 172.17.0.3: seq=1 ttl=64 time=0.158 ms
64 bytes from 172.17.0.3: seq=2 ttl=64 time=0.110 ms
64 bytes from 172.17.0.3: seq=3 ttl=64 time=0.146 ms
--- 172.17.0.3 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.071/0.121/0.158 msbox2 -> box1
[root@localhost vagrant]# docker exec box2 ping 172.17.0.2 -c 4
PING 172.17.0.2 (172.17.0.2): 56 data bytes
64 bytes from 172.17.0.2: seq=0 ttl=64 time=0.081 ms
64 bytes from 172.17.0.2: seq=1 ttl=64 time=0.082 ms
64 bytes from 172.17.0.2: seq=2 ttl=64 time=0.091 ms
64 bytes from 172.17.0.2: seq=3 ttl=64 time=0.109 ms
--- 172.17.0.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.081/0.090/0.109 ms3.1.3 连通测试——以容器名
box1 -> box2
[root@localhost vagrant]# docker exec box1 ping box2 -c 4
ping: bad address 'box2'box2 -> box1
[root@localhost vagrant]# docker exec box2 ping box1 -c 4
PING box1 (172.17.0.2): 56 data bytes
64 bytes from 172.17.0.2: seq=0 ttl=64 time=0.073 ms
64 bytes from 172.17.0.2: seq=1 ttl=64 time=0.106 ms
64 bytes from 172.17.0.2: seq=2 ttl=64 time=0.173 ms
64 bytes from 172.17.0.2: seq=3 ttl=64 time=0.078 ms
--- box1 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.073/0.107/0.173 ms3.2 自定义 bridge 类型网络
对 Docker 而言,我们可以新建一个 bridge 类型的网络,并将需要以彼此的容器名互联的容器添加到这一网络中,即可实现上述需求。注意,一定要使用新建的 bridge 网络,采用默认的那个是不行的。
为了进行试验,我们需要先将 3.1 中创建的容器删除,然后进行如下步骤:
3.2.1 新建 bridge 类型网络
执行如下指令,创建 bridge 类型网络:
docker network create my-bridge --driver bridge3.2.2 创建容器
这里,我们创建三个容器:box1、box2、box3,并将 box1 和 box2 加入新创建的 my-bridge 网络中:
docker run -d --name box1 --network my-bridge busybox /bin/sh -c "while true; do sleep 3600; done;"
docker run -d --name box2 --network my-bridge busybox /bin/sh -c "while true; do sleep 3600; done;"
docker run -d --name box3 busybox /bin/sh -c "while true; do sleep 3600; done;"然后,我们同一下指令,检测容器是否存在于网络中:
检查 my-bridge 网络中有哪些容器:
# 指令
docker network inspect my-bridge
# 结果
"Containers": {
"70b929cee25b665ff0d55cd4e979fcf8dd21190c6200d49af0f2bef07efb723e": {
"Name": "box2",
"EndpointID": "6c19d556751f3e745f947cc0b0e2995312b6712055fac4d79a52114b6f21ddd2",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"92d63195660f1e666028294144ddd65be06e38827debaad1ebd90ce9c79dbaa7": {
"Name": "box1",
"EndpointID": "9b28b2e724ff19e1cbce1fb05afe4a439f51735c0a2a7671c8002fa58c087199",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
}检查 bridge 网络中有哪些容器:
# 指令
docker network inspect bridge
# 结果
"Containers": {
"5526023acd4197c9abf6f17c9a59585322cd2154b70238872083e48b7012ab4e": {
"Name": "box3",
"EndpointID": "6ceb455b487e533439c715a48849986a62ecda68d51d141f228ebdb7d06cf560",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
}3.2.3 测试
首先,我们对处于 my-bridge 这一自定义网络中的容器 box1、box2 之间的连通性进行测试( 通过容器名 ):
[root@localhost vagrant]# docker exec box1 ping box2 -c 1
PING box2 (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.052 ms
--- box2 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.052/0.052/0.052 ms
[root@localhost vagrant]# docker exec box2 ping box1 -c 1
PING box1 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.053 ms
--- box1 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.053/0.053/0.053 ms然后我们测试 box3 与 box1、box2 之间的连通性( 通过容器名 ):
[root@localhost vagrant]# docker exec box1 ping box3 -c 1
ping: bad address 'box3'
[root@localhost vagrant]# docker exec box2 ping box3 -c 1
ping: bad address 'box3'
[root@localhost vagrant]# docker exec box3 ping box1 -c 1
ping: bad address 'box1'
[root@localhost vagrant]# docker exec box3 ping box2 -c 1
ping: bad address 'box2'然后,我们测试一下这三个容器对公网的连通性:
[root@localhost vagrant]# docker exec box1 ping www.baidu.com -c 1
PING www.baidu.com (115.239.210.27): 56 data bytes
64 bytes from 115.239.210.27: seq=0 ttl=61 time=22.467 ms
--- www.baidu.com ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 22.467/22.467/22.467 ms
[root@localhost vagrant]# docker exec box2 ping www.baidu.com -c 1
PING www.baidu.com (115.239.210.27): 56 data bytes
64 bytes from 115.239.210.27: seq=0 ttl=61 time=19.068 ms
--- www.baidu.com ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 19.068/19.068/19.068 ms
[root@localhost vagrant]# docker exec box3 ping www.baidu.com -c 1
PING www.baidu.com (115.239.211.112): 56 data bytes
64 bytes from 115.239.211.112: seq=0 ttl=61 time=20.087 ms
--- www.baidu.com ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 20.087/20.087/20.087 ms可以发现:
- box1 和 box2 之间是相互连通的( 通过容器名 );
- box3 之于 box1、box2 都是不连通的( 通过容器名 );
- 这三个容器对公网都是连通的。
3.3 Docker network connect
对于已经启动的容器,可以通过 docker network connect 将其加入某一网络中。
接着 3.2 中的试验,我们将 box3 容器加入到 my-bridge 网络中,然后重新检测其对 box1、box2 的连通性:
3.3.1 将 box3 加入 my-bridge 网络中
docker network connect my-bridge box33.3.2 检验 my-bridge 网络中现有容器情况
# 指令
docker network inspect my-bridge
# 结果
"Containers": {
"5526023acd4197c9abf6f17c9a59585322cd2154b70238872083e48b7012ab4e": {
"Name": "box3",
"EndpointID": "b7fe8d2697ab20ec5a92886768e33345dd7d161488ac30488e8800e4b0fb0166",
"MacAddress": "02:42:ac:12:00:04",
"IPv4Address": "172.18.0.4/16",
"IPv6Address": ""
},
"70b929cee25b665ff0d55cd4e979fcf8dd21190c6200d49af0f2bef07efb723e": {
"Name": "box2",
"EndpointID": "6c19d556751f3e745f947cc0b0e2995312b6712055fac4d79a52114b6f21ddd2",
"MacAddress": "02:42:ac:12:00:03",
"IPv4Address": "172.18.0.3/16",
"IPv6Address": ""
},
"92d63195660f1e666028294144ddd65be06e38827debaad1ebd90ce9c79dbaa7": {
"Name": "box1",
"EndpointID": "9b28b2e724ff19e1cbce1fb05afe4a439f51735c0a2a7671c8002fa58c087199",
"MacAddress": "02:42:ac:12:00:02",
"IPv4Address": "172.18.0.2/16",
"IPv6Address": ""
}
}可以发现,box3 已经加入到了 my-bridge 网络之中。
3.3.3 检验 box3 对 box1、box2 之间的连通性( 通过容器名 )
[root@localhost vagrant]# docker exec box3 ping box1
PING box1 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.075 ms
^C
[root@localhost vagrant]# docker exec box3 ping box1 -c 1
PING box1 (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.066 ms
--- box1 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.066/0.066/0.066 ms
[root@localhost vagrant]# docker exec box3 ping box2 -c 1
PING box2 (172.18.0.3): 56 data bytes
64 bytes from 172.18.0.3: seq=0 ttl=64 time=0.069 ms
--- box2 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.069/0.069/0.069 ms
[root@localhost vagrant]# docker exec box1 ping box3 -c 1
PING box3 (172.18.0.4): 56 data bytes
64 bytes from 172.18.0.4: seq=0 ttl=64 time=0.050 ms
--- box3 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.050/0.050/0.050 ms
[root@localhost vagrant]# docker exec box2 ping box3 -c 1
PING box3 (172.18.0.4): 56 data bytes
64 bytes from 172.18.0.4: seq=0 ttl=64 time=0.052 ms
--- box3 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.052/0.052/0.052 ms可以发现,现在 box1、box2、box3 之间可以互相通过容器名连通了。
4. Overlay 网络实现多 Docker 节点中容器间通信
4.1 多 Docker 节点中容器间通信问题
在实际生产中,往往存在不同主机间 Docker 容器的互访问题,如下图所示:
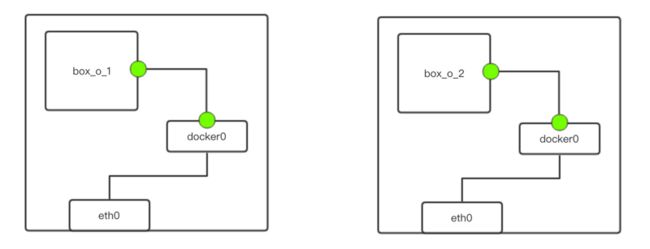
由于 box_o_1 和 box_o_2 处于各自机器的 Docker 中,若想互相访问,可以通过层层路由配置,使数据包可以在二者之间传递。
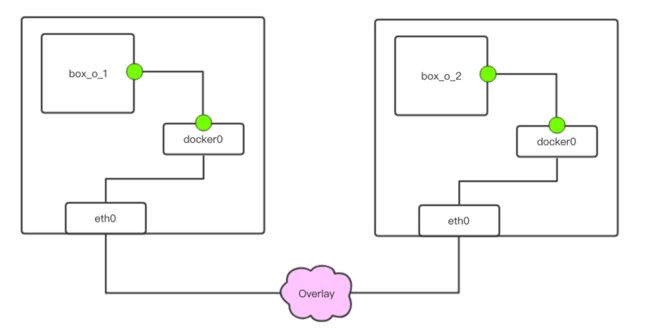
这一过程在管理和扩展上都比较麻烦。针对这一问题,Docker 采用 Overlay 网络来解决。
4.2 Overlay 网络与 VXLAN
简而言之,Overlay 可以使得我们将报文在 IP 报文之上再次封装。以 4.1 中的图举例,Overlay 使得数据可以先通过传统网络由左侧节点到达右侧节点,数据包在右侧节点拆包后,其内容又是一个标准的网络数据包,进而能够传递到 box_o_2 容器中。
在 Overlay 网络中,VXLAN 技术为其核心,以下内容摘自:Overlay之VXLAN架构:
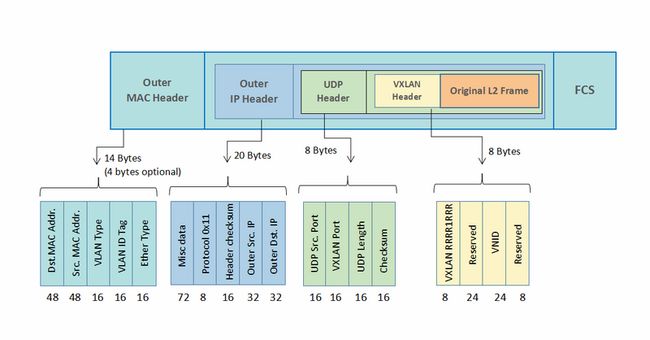
VXLAN: VXLAN是将以太网报文封装成UDP报文进行隧道传输,UDP目的端口为已知端口,源端口可按流分配,标准5元组方式有利于在IP网络转发过程中进行负载分担;隔离标识采用24比特来表示;未知目的、广播、组播等网络流量均被封装为组播转发。
VXLAN 报文结构如下,下图取自:QinQ vs VLAN vs VXLAN:
4.3 在 Docker 中使用 Overlay
4.3.1 实验目的及前置准备
在这一实验中,我们需要准备:
- 两台已安装 Docker 的机器。这里的机器系统为:Centos7.4,机器 IP 分别为:192.168.33.10 及 192.168.33.11;
- 两台 Docker 机器之间彼此互通。
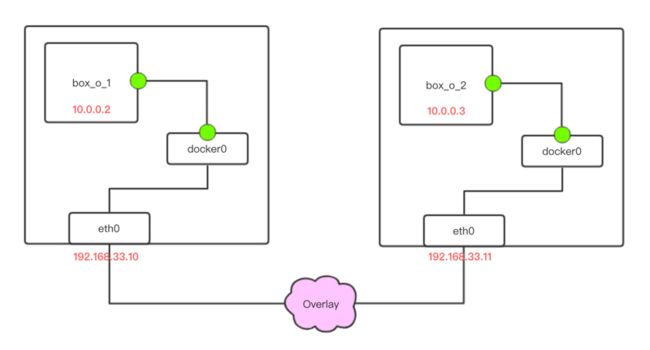
实验的目的是实现位于两台机器上两个容器彼此互通。
4.3.2 etcd
当我们在其中一台机器上创建一个 overlay 类型的网络时,会报错如下:
[vagrant@192-168-33-10 ~]$ docker network create -d overlay my-overlay
Error response from daemon: This node is not a swarm manager. Use "docker swarm init" or "docker swarm join" to connect this node to swarm and try again.这里是提示我们,单机模式时,是无法创建 overlay 类型网络的。要想实现,这一需求,可以使用 Docker 编排工具,如 swarm。
但这篇博客的重点不在 swarm,我们可以在 docker 启动时,为其指定一个分布式存储,从而使得我们能够实验 overlay 网络。
etcd 是一个分布式键值存储系统,其 Github 地址为:GitHub - coreos/etcd: Distributed reliable key-value store for the most critical data of a distributed system。
关于 etcd 的安装细节可以参考另一篇博文:分布式 key-value 存储系统 etcd 的安装备忘。这里直接贴出安装指令:
# 在两台机器上下载、解压 etcd,并进入 etcd 目录
wget https://github.com/coreos/etcd/releases/download/v3.3.8/etcd-v3.3.8-linux-amd64.tar.gz
tar -zvxf etcd-v3.3.8-linux-amd64.tar.gz
cd etcd-v3.3.8-linux-amd64
# 在 192.168.33.10 中执行
nohup ./etcd --name my-etcd-1 \
--listen-client-urls http://192.168.33.10:2379 \
--advertise-client-urls http://192.168.33.10:2379 \
--listen-peer-urls http://192.168.33.10:2380 \
--initial-advertise-peer-urls http://192.168.33.10:2380 \
--initial-cluster my-etcd-1=http://192.168.33.10:2380,my-etcd-2=http://192.168.33.11:2380 \
--initial-cluster-token my-etcd-token \
--initial-cluster-state new \
>/dev/null 2>&1 &
# 在 192.168.33.11 中执行
nohup ./etcd --name my-etcd-2 \
--listen-client-urls http://192.168.33.11:2379 \
--advertise-client-urls http://192.168.33.11:2379 \
--listen-peer-urls http://192.168.33.11:2380 \
--initial-advertise-peer-urls http://192.168.33.11:2380 \
--initial-cluster my-etcd-1=http://192.168.33.10:2380,my-etcd-2=http://192.168.33.11:2380 \
--initial-cluster-token my-etcd-token \
--initial-cluster-state new \
>/dev/null 2>&1 &最终可以通过以下方式检测集群的启动情况:
[vagrant@192-168-33-10 etcd-v3.3.8-linux-amd64]$ ./etcdctl --endpoints http://192.168.33.10:2379 cluster-health
member 42ab269b4f75b118 is healthy: got healthy result from http://192.168.33.11:2379
member 7118e8ab00eced36 is healthy: got healthy result from http://192.168.33.10:2379
cluster is healthy注:建议 etcd 启动后,重新 ssh 一次,以免出现 etcd 的一些莫名其妙的报错信息。
4.3.3 借助 etcd 重启 docker
接下来我们要借助 etcd,重启 docker,并为其指定分布式存储:
首先,在两台机器上停止 docker:
systemctl stop docker然后,重启 docker。注意,这一步需要在 etcd 启动后进行:
# 在 192.168.33.10 中执行:
sudo /usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-store=etcd://192.168.33.10:2379 --cluster-advertise=192.168.33.10:2375 &
# 在 192.168.33.11 中执行:
sudo /usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock --cluster-store=etcd://192.168.33.11:2379 --cluster-advertise=192.168.33.11:2375 &4.3.4 创建 overlay 网络
接下来,我们再次创建 overlay 网络
在 192.168.33.10 中执行:
[vagrant@192-168-33-10 etcd-v3.3.8-linux-amd64]$ docker network create -d overlay my-overlay
989fbe070eed940a0c3ec4182e7d04413a16eb9e33547b0d88002a7ec5138a07由于在 docker 启动时指定了分布式存储,因而我们无需再在 192.168.33.11 中创建这一 overlay 网络,创建过程已经在节点之间同步了:
# 192.168.33.10 中的网络创建行为已经在 192.168.33.11 中同步了
[vagrant@192-168-33-11 etcd-v3.3.8-linux-amd64]$ docker network ls
NETWORK ID NAME DRIVER SCOPE
16498c285808 bridge bridge local
b5cb83566f18 host host local
989fbe070eed my-overlay overlay global
80fe629bd0c3 none null local为了证明这一点,我们可以在 etcd 中看到这一存储:
[vagrant@192-168-33-11 etcd-v3.3.8-linux-amd64]$ ./etcdctl --endpoints http://192.168.33.11:2379 ls /docker/network/v1.0/network
/docker/network/v1.0/network/989fbe070eed940a0c3ec4182e7d04413a16eb9e33547b0d88002a7ec5138a07可以看到,这一网络的 Hash 名正是我们在先前创建时所生成的名字。
注:不同的 docker 版本可能使得这一路径不同。
4.3.5 创建容器,并使其加入 my-overlay 网络
# 在 192.168.33.10 上启动 box1
[vagrant@192-168-33-10 ~]$ docker run -d --name box1 --network my-overlay busybox /bin/sh -c "while true; do sleep 3600; done"
# 在 192.168.33.11 上启动 box2
[vagrant@192-168-33-11 ~]$ docker run -d --name box2 --network my-overlay busybox /bin/sh -c "while true; do sleep 3600; done"接着,我们使用以下指令,查看该网络中的容器情况:
docker network inspect my-overlay
"Containers": {
"46397d0f23812e4252858b8e28c76f6fe5ecc34a95389af0abb22473058cd930": {
"Name": "box1",
"EndpointID": "b9826147f5b9bdd9e504ecd5860caf85d52151da1c03d47a9627403c55099b2e",
"MacAddress": "",
"IPv4Address": "10.0.0.2/24",
"IPv6Address": ""
},
"ep-740ffaf6b455a7f3214ac83d9452d2229f1b19b847c4fba478a1b3650af97927": {
"Name": "box2",
"EndpointID": "740ffaf6b455a7f3214ac83d9452d2229f1b19b847c4fba478a1b3650af97927",
"MacAddress": "",
"IPv4Address": "10.0.0.3/24",
"IPv6Address": ""
}
}可以发现,及时处于不同的主机上,我们也在打印的信息中看到这两个容器。此外,这两个容器的 IP 并没有重复,这也是借助分布式存储系统起到的效果。
4.3.6 连接测试
192.168.33.10 - box1(10.0.0.2) -> 192.168.33.11 - box2(10.0.0.3)
[vagrant@192-168-33-10 ~]$ docker exec box1 ping box2 -c 4
PING box2 (10.0.0.3): 56 data bytes
64 bytes from 10.0.0.3: seq=0 ttl=64 time=0.785 ms
64 bytes from 10.0.0.3: seq=1 ttl=64 time=0.643 ms
64 bytes from 10.0.0.3: seq=2 ttl=64 time=0.601 ms
64 bytes from 10.0.0.3: seq=3 ttl=64 time=0.638 ms
--- box2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.601/0.666/0.785 ms
[vagrant@192-168-33-10 ~]$ docker exec box1 ping 10.0.0.3 -c 4
PING 10.0.0.3 (10.0.0.3): 56 data bytes
64 bytes from 10.0.0.3: seq=0 ttl=64 time=1.020 ms
64 bytes from 10.0.0.3: seq=1 ttl=64 time=0.690 ms
64 bytes from 10.0.0.3: seq=2 ttl=64 time=1.003 ms
64 bytes from 10.0.0.3: seq=3 ttl=64 time=0.918 ms
--- 10.0.0.3 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.690/0.907/1.020 ms192.168.33.11 - box2(10.0.0.3) -> 192.168.33.10 - box1(10.0.0.2)
[vagrant@192-168-33-11 ~]$ docker exec box2 ping box1 -c 4
PING box1 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: seq=0 ttl=64 time=0.593 ms
64 bytes from 10.0.0.2: seq=1 ttl=64 time=0.691 ms
64 bytes from 10.0.0.2: seq=2 ttl=64 time=0.690 ms
64 bytes from 10.0.0.2: seq=3 ttl=64 time=0.671 ms
--- box1 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.593/0.661/0.691 ms
[vagrant@192-168-33-11 ~]$ docker exec box2 ping 10.0.0.2 -c 4
PING 10.0.0.2 (10.0.0.2): 56 data bytes
64 bytes from 10.0.0.2: seq=0 ttl=64 time=0.987 ms
64 bytes from 10.0.0.2: seq=1 ttl=64 time=0.699 ms
64 bytes from 10.0.0.2: seq=2 ttl=64 time=0.769 ms
64 bytes from 10.0.0.2: seq=3 ttl=64 time=1.054 ms
--- 10.0.0.2 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.699/0.877/1.054 ms可见,采用 overlay 网络,可以实现不同机器上,docker 容器间的互通。
下面,我们补充之前的图,用于展示这一实验中的网络拓扑情况:
参考链接
- linux 网络命名空间 Network namespaces - CSDN博客
- Linux虚拟网络设备之veth - Linux程序员 - SegmentFault 思否
- Overlay之VXLAN架构 - CSDN博客
- QinQ vs VLAN vs VXLAN
- 分布式 key-value 存储系统 etcd 的安装备忘 - DB.Reid - SegmentFault 思否