Hadoop HA 集群搭建
hadoop HA原理概述
为什么会有 hadoop HA 机制呢?
- HA:High Available,高可用
在Hadoop 2.0之前,在HDFS 集群中NameNode 存在单点故障 (SPOF:A Single Point of Failure)。对于只有一个 NameNode 的集群,如果 NameNode 机器出现故障(比如宕机或是软件、硬件升级),那么整个集群将无法使用,直到 NameNode 重新启动。 - 那如何解决呢?HDFS 的 HA 功能通过配置 Active/Standby 两个 NameNodes 实现在集群中对 NameNode 的热备来解决上述问题。如果出现故障,如机器崩溃或机器需要升级维护,这时可通过此种方式将 NameNode 很快的切换到另外一台机器。
- 在一个典型的 HDFS(HA) 集群中,使用两台单独的机器配置为 NameNodes 。在任何时间点,确保 NameNodes 中只有一个处于 Active 状态,其他的处在 Standby 状态。其中ActiveNameNode 负责集群中的所有客户端操作,StandbyNameNode 仅仅充当备机,保证一旦 ActiveNameNode 出现问题能够快速切换。
- 为了能够实时同步 Active 和 Standby 两个 NameNode 的元数据信息(实际上 editlog),需提供一个共享存储系统,可以是 NFS、QJM(Quorum Journal Manager)或者 Zookeeper,ActiveNamenode 将数据写入共享存储系统,而 Standby 监听该系统,一旦发现有新数据写入,则读取这些数据,并加载到自己内存中,以保证自己内存状态与 Active NameNode 保持基本一致,如此这般,在紧急情况下 standby 便可快速切为 active namenode。为了实现快速切换,Standby 节点获取集群的最新文件块信息也是很有必要的。为了实现这一目标,DataNode 需要配置 NameNodes 的位置,并同时给他们发送文件块信息以及心跳检测。
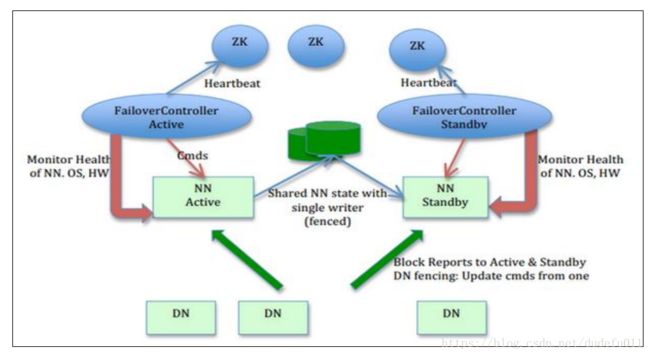
SecondaryNameNode 和 Standby Namenode 的区别?
在1.x版本中,SecondaryNameNode将fsimage跟edits进行合并,生成新的fsimage文件用http post传回NameNode节点。SecondaryNameNode不能做NameNode的备份。
在hadoop 2.x版本中才引入StandbyNameNode,从journalNode上拷贝的。StandbyNameNode是可以做namenode的备份。
Hadoop2的高可用并取代SecondaryNamenode
在hadoop2实际生产环境中,为什么还需要SecondeNamenode
secondary namenode和namenode的区别
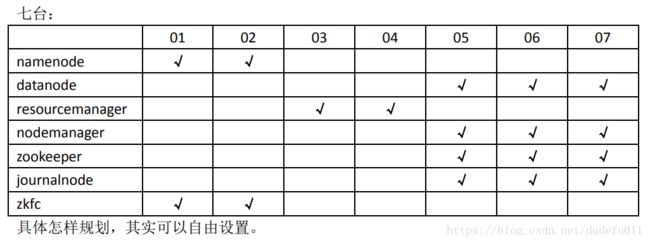
集群规划
描述:hadoop HA 集群的搭建依赖于 zookeeper,所以选取三台当做 zookeeper 集群我总共准备了四台主机,分别是 hadoop02,hadoop03,hadoop04,hadoop05其中 hadoop02 和 hadoop03 做 namenode 的主备切换,hadoop04 和 hadoop05 做resourcemanager 的主备切换

集群服务器准备
1、 修改主机名
2、 修改 IP 地址
3、 添加主机名和 IP 映射
4、 添加普通用户 hadoop 用户并配置 sudoer 权限
5、 设置系统启动级别
6、 关闭防火墙/关闭 Selinux
7、 安装 JDK
两种准备方式:
1、 每个节点都单独设置,这样比较麻烦。线上环境可以编写脚本实现
2、 虚拟机环境可是在做完以上 7 步之后,就进行克隆
3、 然后接着再给你的集群配置 SSH 免密登陆和搭建时间同步服务
8、 配置 SSH 免密登录
9、 同步服务器时间
集群安装
1、安装 Zookeeper 集群(略)
2、 安装 hadoop 集群
修改配置文件:
core-site.xml :
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://myha01/value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/data1/hadoopdata/value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181value>
property>
<property>
<name>ha.zookeeper.session-timeout.msname>
<value>1000value>
<description>msdescription>
property>
configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>/home/hadoop/data1/hadoopdata/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>/home/hadoop/data1/hadoopdata/dfs/datavalue>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>myha01value>
property>
<property>
<name>dfs.ha.namenodes.myha01name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.myha01.nn1name>
<value>hadoop01:9000value>
property>
<property>
<name>dfs.namenode.http-address.myha01.nn1name>
<value>hadoop01:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.myha01.nn2name>
<value>hadoop02:9000value>
property>
<property>
<name>dfs.namenode.http-address.myha01.nn2name>
<value>hadoop02:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://hadoop02:8485;hadoop03:8485;hadoop04:8485/myha01value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/home/hadoop/data1/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.myha01name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
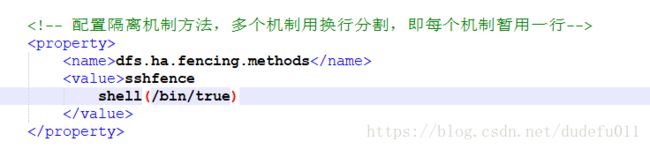
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.msname>
<value>60000value>
property>
configuration>
mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>hadoop01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>hadoop01:19888value>
property>
configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>hadoop03value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>hadoop04value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181,hadoop04:2181,hadoop05:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.log-aggregation-enablename>
<value>truevalue>
property>
<property>
<name>yarn.log-aggregation.retain-secondsname>
<value>86400value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.store.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStorevalue>
property>
configuration>hadoop-env.sh: 修改JAVA_HOME
slaves文件:修改映射
注意:配置文件是最容易出错的地方,建议复制,不建议手写,容易出错。格式化namenode之后,如果出错了,建议删除临时文件日志目录,每台机器都要删除,重新格式化,注意顺序步骤。
如果DFSZKFailoverController自动死掉,则有可能是因为以下配置问题:
错误配置,会导致DFSZKFailoverController死掉:

正确写法,注意sshfence不能换行:
分发安装包到其他机器
scp -r hadoop-2.7.5 hadoop@hadoop02:$PWD
scp -r hadoop-2.7.5 hadoop@hadoop03:$PWD
scp -r hadoop-2.7.5 hadoop@hadoop04:$PWD
scp -r hadoop-2.7.5 hadoop@hadoop05:$PWD并分别配置环境变量
vi ~/.bashrc
添加两行:
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.6.5
export PATH= PATH: P A T H : HADOOP_HOME/bin:$HADOOP_HOME/sbin
保存退出
集群初始化操作:(注意:严格按照以下步骤执行)
1、 先启动 zookeeper 集群
启动:zkServer.sh start
检查启动是否正常:zkServer.sh status
2、 分别在每个 zookeeper(也就是规划的三个 journalnode 节点,不一定跟 zookeeper
节点一样)节点上启动 journalnode 进程
[hadoop@hadoop01 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop02 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop03 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop04 ~]$ hadoop-daemon.sh start journalnode
[hadoop@hadoop05 ~]$ hadoop-daemon.sh start journalnode然后用 jps 命令查看是否各个 datanode 节点上都启动了 journalnode 进程
如果报错,根据错误提示改进
3、在第一个 namenode 上执行格式化操作
然后会在 core-site.xml 中配置的临时目录中生成一些集群的信息
把他拷贝的第二个 namenode 的相同目录下
<name>hadoop.tmp.dirname>
<value>/home/hadoop/data/hadoopdata/value>这个目录下,千万记住:两个 namenode 节点该目录中的数据结构是一致的
[hadoop@hadoop02 ~]$ scp -r ~/data/hadoopdata/ hadoop03:~/data
或者也可以在另一个 namenode 上执行:hadoop namenode -bootstrapStandby
[hadoop@hadoop02 ~]$ hadoop namenode -format4、格式化 ZKFC
[hadoop@hadoop02 ~]$ hdfs zkfc -formatZK在第一台机器上即可
5、启动 HDFS
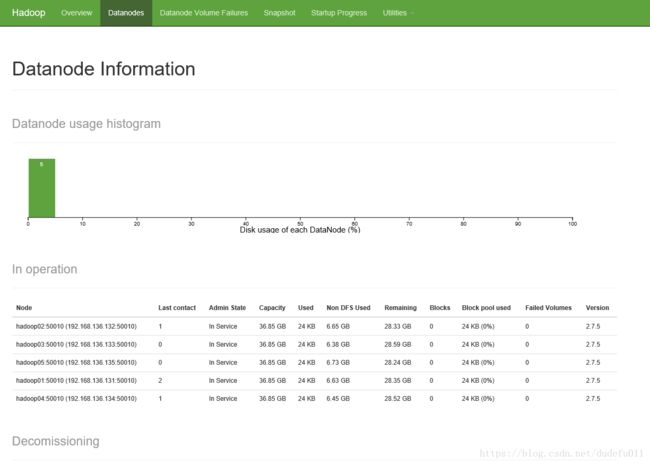
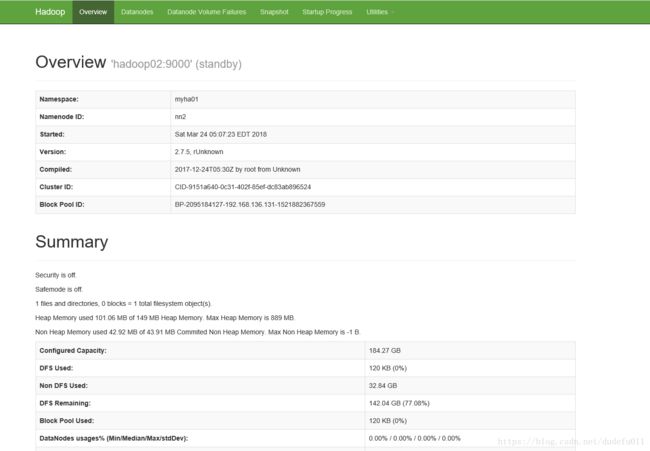
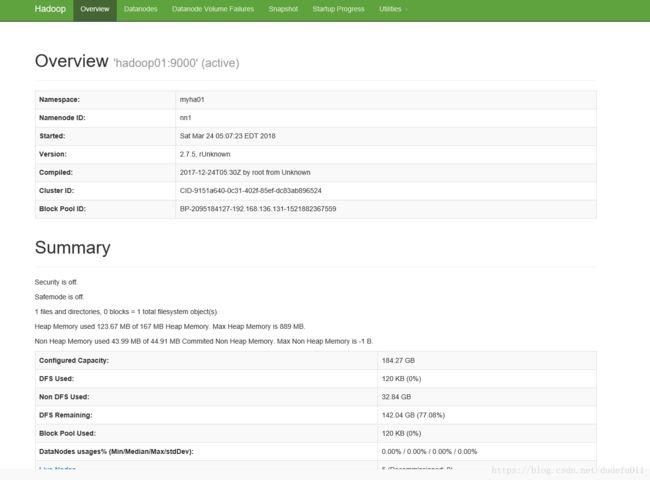
[hadoop@hadoop02 ~]$ start-dfs.sh查看各节点进程是否启动正常:依次为 2345 四台机器的进程
最终效果:
访问 web 页面 http://hadoop01:50070
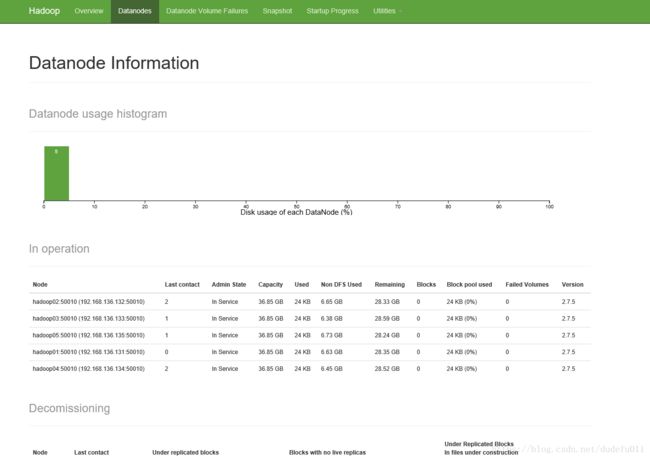
访问 web 页面 http://hadoop02:50070
启动 YARN
[hadoop@hadoop04 ~]$ start-yarn.sh
在主备 resourcemanager 中随便选择一台进行启动,正常启动之后,检查各节点的进程:
若备用节点的 resourcemanager 没有启动起来,则手动启动起来
[hadoop@hadoop04 ~]$ yarn-daemon.sh start resourcemanager访问页面:http://hadoop03:8088

访问页面:http://hadoop04:8088 自动跳转至hadoop03机器
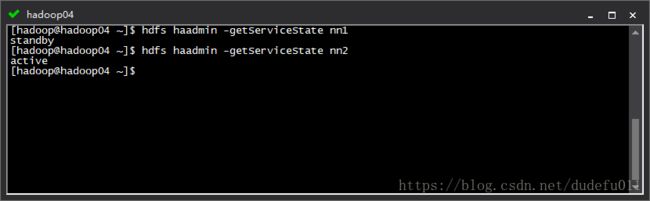
查看各主节点的状态
HDFS:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
YARN:
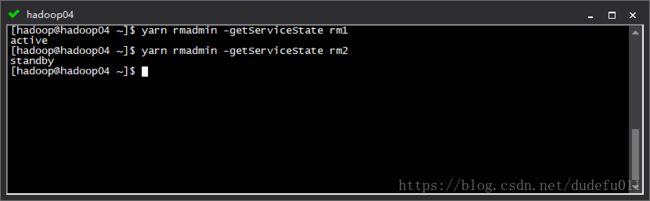
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
启动 mapreduce 任务历史服务器
[hadoop@hadoop01 ~]$ mr-jobhistory-daemon.sh start historyserver按照配置文件配置的历史服务器的 web 访问地址去访问:
http://hadoop01:19888
集群启动测试
1、干掉 active namenode, 看看集群有什么变化
干掉active namenode,standby namenode瞬间转为active状态;重新启动刚才那台干掉的节点后,该节点变为standby 状态。
2、在上传文件的时候干掉 active namenode, 看看有什么变化
会报错,但是可以上传成功。
3、干掉 active resourcemanager, 看看集群有什么变化
hadoop03上的yarn节点就不能访问,hadoop05上的yarn节点可以正常访问。
4、在执行任务的时候干掉 active resourcemanager,看看集群
执行wordcount程序,执行的时候,在hadoop03节点上杀死ResourceManager,最终能够成功执行。