泰坦尼克号数据挖掘项目实战——Task5 模型评估
任务5:记录5个模型(逻辑回归、SVM、决策树、随机森林、XGBoost)关于accuracy、precision,recall和F1-score、auc值的评分表格,并画出ROC曲线。
参考:【1】https://www.cnblogs.com/sddai/p/5696870.html
【2】http://www.cnblogs.com/bluepoint2009/archive/2012/09/18/precision-recall-f_measures.html
【3】https://blog.csdn.net/u013063099/article/details/80964865
【4】https://blog.csdn.net/xiaodongxiexie/article/details/67009112
首先简单介绍下这些指标都是什么:
评价分类器性能的指标一般是分类准确率(Accuracy),其定义是:对于给定的测试数据集,分类器正确分类的样本数和总样本数之比。对于二分类问题常见的评价指标是精确率(precision)与召回率(recall)。 通常以关注的类为正类,其他类为负类,分类器在测试数据集上的预测或正确或不正确,四种情况出现的总数分别记作:
TP ——将正类预测为正类数(True Positive)
FN ——将正类预测为负类数(False Negative)
FP ——-将负类预测为正类
TN ——-将负类预测为负类数
一、TP、TN、FP、FN概念
首先有关TP、TN、FP、FN的概念。大体来看,TP与TN都是分对了情况,TP是正类,TN是负类。则推断出,FP是把错的分成了对的,而FN则是把对的分成了错的。

二、正确率 、精确率(精准率)、召回率、F1值
1.准确率(Accuracy)。顾名思义,就是所有的预测正确(正类负类)的占总的比重。
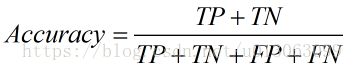
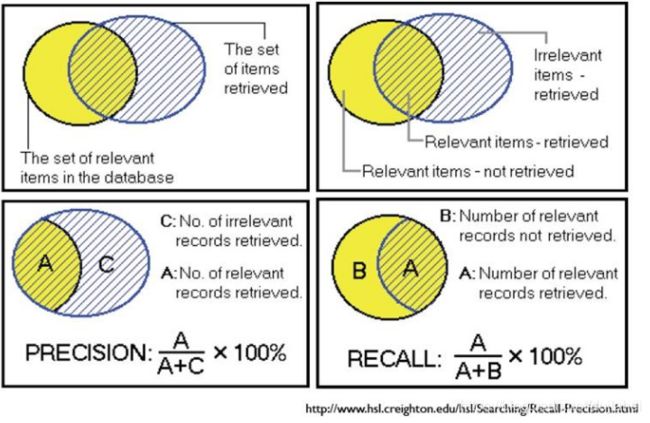
2.精确率(Precision),查准率。即正确预测为正的占全部预测为正的比例。个人理解:真正正确的占所有预测为正的比例。
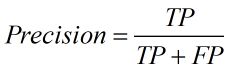
3.召回率(Recall),查全率。即正确预测为正的占全部实际为正的比例。个人理解:真正正确的占所有实际为正的比例。
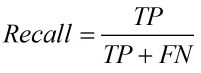
我们当然希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。比如极端情况下,我们只搜出了一个结果,且是准确的,那么P就是100%,但是R就很低;而如果我们把所有结果都返回,那么必然R是100%,但是P很低。因此在不同的场合中需要自己判断希望P比较高还是R比较高。
如果是做实验研究,可以绘制Precision-Recall曲线来帮助分析。注意:准确率和召回率是互相影响的,理想情况下肯定是做到两者都高,但是一般情况下准确率高、召回率就低,召回率低、准确率高,当然如果两者都低,那是什么地方出问题了 。一般情况,用不同的阀值,统计出一组不同阀值下的精确率和召回率。P-R曲线:查准率-查全率曲线:precision为纵轴,recall为横轴。

根据P-R曲线的性能度量方式:
- 若学习器的P-R曲线被另一个学习器完全“包住”,则后者的性能优于前者;
- 若两个学习器的P-R曲线发生了交叉,可以运用平衡点(Break-Even Point,BEP),即根据在“查准率=查全率”时的取值,判断学习器性能的好坏。
- 若两个学习器的P-R曲线发生了交叉,亦可以使用F1/F_\beta度量,分别表示查准率和查全率的调和平均和加权调和平均。其中,F2分数中,召回率的权重高于准确率,而F0.5分数中,准确率的权重高于召回率。 F_\beta的物理意义就是将准确率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是准确率的\beta倍。F1分数认为召回率和准确率同等重要,F2分数认为召回率的重要程度是准确率的2倍,而F0.5分数认为召回率的重要程度是准确率的一半。
- 若两个学习器的P-R曲线发生了交叉,亦可以使用AP\MAP:即计算P-R曲线下的面积
4.F1值。F1-Measure
前面已经讲了,P和R指标有的时候是矛盾的,那么有没有办法综合考虑他们呢?我想方法肯定是有很多的,最常见的方法应该就是F-Measure了,有些地方也叫做F-Score,其实都是一样的。
F-Measure是Precision和Recall加权调和平均:
![]()
当参数a=1时,就是最常见的F1了:
![]()
很容易理解,F1综合了P和R的结果,当F1较高时则比较说明实验方法比较理想。F1值为算数平均数除以几何平均数,且越大越好,将Precision和Recall的上述公式带入会发现,当F1值小时,True Positive相对增加,而false相对减少,即Precision和Recall都相对增加,即F1对Precision和Recall都进行了加权。
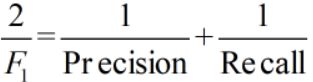
公式转化之后为:
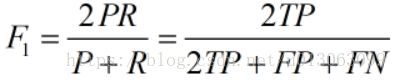
下面这张图,可以帮助加深对精确率和召回率的理解:
三、ROC曲线、AUC值
1.ROC曲线。接收者操作特征曲线(receiver operating characteristic curve),是反映敏感性和特异性连续变量的综合指标,ROC曲线上每个点反映着对同一信号刺激的感受性。下图是ROC曲线例子。
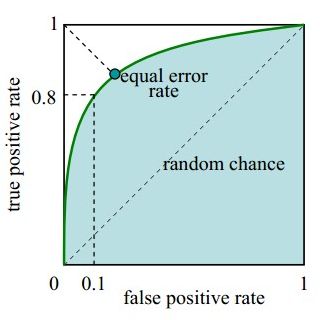
横坐标:1-Specificity,假阳率(False positive rate,FPR,FPR=FP/(FP+TN)),预测为正但实际为负的样本占所有负例样本的比例;
纵坐标:Sensitivity,真阳率(True positive rate,TPR,TPR=TP/(TP+FN)),预测为正且实际为正的样本占所有正例样本的比例。
在一个二分类模型中,假设采用逻辑回归分类器,其给出针对每个实例为正类的概率,那么通过设定一个阈值如0.6,概率大于等于0.6的为正类,小于0.6的为负类。对应的就可以算出一组(FPR,TPR),在平面中得到对应坐标点。随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
真正的理想情况,TPR应接近1,FPR接近0,即图中的(0,1)点。ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。
2.AUC值。
AUC (Area Under Curve) 被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围一般在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
从AUC判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
一句话来说,AUC值越大的分类器,正确率越高。
以上为对基本概念的补充学习,接下来回归到这次任务,记录5个模型(逻辑回归、SVM、决策树、随机森林、XGBoost)关于accuracy、precision,recall和F1-score、auc值的评分表格,并画出ROC曲线。
####Task 5 对模型进行评估
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score
import matplotlib.pyplot as plt
# 逻辑回归的accuracy、precision,recall和F1-score auc
TrainData, TestData,TrainLabel,TestLabel = train_test_split(train_X, target_Y, test_size=0.3,random_state = 2018)
lr = LogisticRegression()
lr.fit(TrainData, TrainLabel)
TestPred=lr.predict(TestData)
print('准确率:', accuracy_score(TestLabel, TestPred))
print('精确率:', precision_score(TestLabel, TestPred, average='binary'))
print('召回率:', recall_score(TestLabel, TestPred, average='binary'))
print('F1-score:', f1_score(TestLabel, TestPred))
fpr, tpr, _ = roc_curve(TestLabel, lr.predict_proba(TestData)[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('LR ROC Curve')
plt.legend(loc="lower right")
plt.show()
#SVM
from sklearn.svm import SVC
TrainData, TestData,TrainLabel,TestLabel = train_test_split(train_X, target_Y, test_size=0.3,random_state = 2018)
svm = SVC(probability=True)
svm.fit(TrainData, TrainLabel)
TestPred=lr.predict(TestData)
print('准确率:', accuracy_score(TestLabel, TestPred))
print('精确率:', precision_score(TestLabel, TestPred, average='binary'))
print('召回率:', recall_score(TestLabel, TestPred, average='binary'))
print('F1-score:', f1_score(TestLabel, TestPred))
fpr, tpr, _ = roc_curve(TestLabel, svm.predict_proba(TestData)[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('SVM ROC Curve')
plt.legend(loc="lower right")
plt.show()
#决策树
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(TrainData, TrainLabel)
TestPred=dtc.predict(TestData)
print('准确率:', accuracy_score(TestLabel, TestPred))
print('精确率:', precision_score(TestLabel, TestPred, average='binary'))
print('召回率:', recall_score(TestLabel, TestPred, average='binary'))
print('F1-score:', f1_score(TestLabel, TestPred))
fpr, tpr, _ = roc_curve(TestLabel, dtc.predict_proba(TestData)[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('DTC ROC Curve')
plt.legend(loc="lower right")
plt.show()
#随机森林
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(TrainData, TrainLabel)
TestPred=rfc.predict(TestData)
print('准确率:', accuracy_score(TestLabel, TestPred))
print('精确率:', precision_score(TestLabel, TestPred, average='binary'))
print('召回率:', recall_score(TestLabel, TestPred, average='binary'))
print('F1-score:', f1_score(TestLabel, TestPred))
fpr, tpr, _ = roc_curve(TestLabel, rfc.predict_proba(TestData)[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('rfc ROC Curve')
plt.legend(loc="lower right")
plt.show()
#XGBoost
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
xgboost = AdaBoostClassifier()
xgboost.fit(TrainData, TrainLabel)
TestPred = xgboost.predict(TestData)
print('准确率:', accuracy_score(TestLabel, TestPred))
print('精确率:', precision_score(TestLabel, TestPred, average='binary'))
print('召回率:', recall_score(TestLabel, TestPred, average='binary'))
print('F1-score:', f1_score(TestLabel, TestPred))
fpr, tpr, _ = roc_curve(TestLabel, xgboost.predict_proba(TestData)[:, 1])
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('XGBoost ROC Curve')
plt.legend(loc="lower right")
plt.show()| 模型 | 准确率 | 精确率 | 召回率 | F1 | AUC | ROC曲线 |
| 逻辑回归 | |
|
|
|
0.88 | 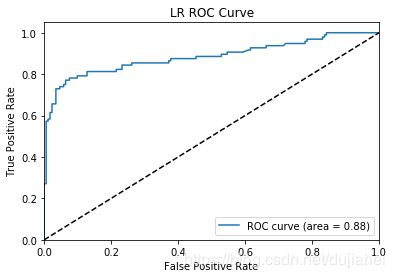 |
| SVM | |
|
|
|
0.79 | 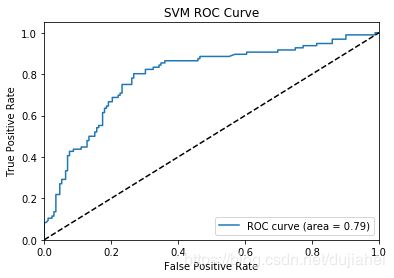 |
| 决策树 | |
|
|
|
0.78 | 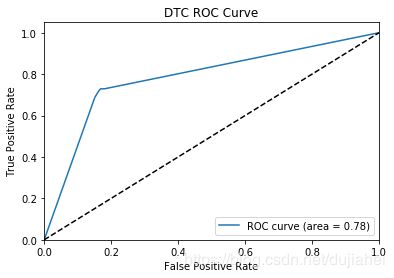 |
| 随机森林 | |
|
0.75 |
|
0.9 | 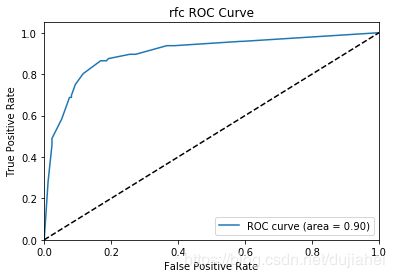 |
| XGBoost | |
|
|
|
0.88 | 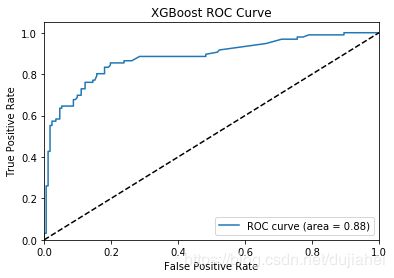 |
从accuracy、precision,recall和F1-score上来看,逻辑回归分类的效果最好,从ROC曲线和AUC数值来看,随机森林的效果最好。