1.回归模型预测波士顿房价
#导入load_boston数据
from sklearn.datasets import load_boston
data = load_boston()
#多元线性回归模型
from sklearn.model_selection import train_test_split
# 训练集与测试集划分为7:3
x_train,x_test,y_train,y_test = train_test_split(data.data,data.target,test_size=0.3)
print(x_train.shape,y_train.shape)
#线性回归模型:建立13个变量与房价之间的预测模型,并检测模型好
#线性回归模型公式:y=^bx+^a
from sklearn.linear_model import LinearRegression
mlr = LinearRegression()
mlr.fit(x_train,y_train)
print('系数b',mlr.coef_,"\n截距a",mlr.intercept_)
#检测模型的好坏
from sklearn.metrics import regression
y_predict = mlr.predict(x_test)
#计算模型的预测指标
print('线性回归模型判断指数')
print("预测的均方误差:",regression.mean_squared_error(y_test,y_predict))
print("预测的平均绝对误差:",regression.mean_absolute_error(y_test,y_predict))
#打印模型分数
print("模型的分数:",mlr.score(x_test,y_test))
#多项式回归模型:建立13个变量与房价之间的预测模型,并检测模型好坏。
# 多项式回归模型公式y = a0 + a1 * x + a2 * (x**2) + ... + an * (x ** n) + e
from sklearn.preprocessing import PolynomialFeatures
#多项式的训练集与测试集
poly2 =PolynomialFeatures(degree=2)
x_poly_train = poly2.fit_transform(x_train)
x_poly_test = poly2.transform(x_test)
#多项回归模型
mlrp=LinearRegression()
mlrp.fit(x_poly_train,y_train)
#预测值
y_predict2 = mlrp.predict(x_poly_test)
#检测模型预测指数的好坏
print("多项式回归模型判断指数")
print("预测的均方误差:",regression.mean_squared_error(y_test,y_predict2))
print("预测平均绝对误差:",regression.mean_absolute_error(y_test,y_predict2))
#打印模型分数
print("模型的分数:",mlrp.score(x_poly_test,y_test))
D:\PY-chrame\venv\Scripts\python.exe D:/PY-chrame/da.py
(354, 13) (354,)
系数b [-1.09516478e-01 3.91540238e-02 5.06501937e-02 1.39431350e+00
-2.18805816e+01 2.97403470e+00 1.05732778e-02 -1.41167412e+00
3.15647470e-01 -1.38088168e-02 -1.05008483e+00 6.15406136e-03
-5.53452057e-01]
截距a 46.69144630560215
线性回归模型判断指数
预测的均方误差: 24.39136560804038
预测的平均绝对误差: 3.375744717006874
模型的分数: 0.7305566210865768
多项式回归模型判断指数
预测的均方误差: 10.004803145076025
预测平均绝对误差: 2.296647007952124
模型的分数: 0.8894802362404708
Process finished with exit code 0
2.新闻文本分类:
#导入数据 import os import numpy as np import sys from datetime import datetime import gc path = 'E:\\258' #导入jieba进行jieba分词 import jieba # 导入停用词: with open(r'D:\\stopsCN.txt',encoding='utf-8') as f: stopwords = f.read().split('\n') def processing(tokens): # 去掉非字母汉字的字符 tokens = "".join([char for char in tokens if char.isalpha()]) # 结巴分词 tokens = [token for token in jieba.cut(tokens,cut_all=True) if len(token) >=2] # 去掉停用词 tokens = " ".join([token for token in tokens if token not in stopwords]) return tokens #存放数据列表 tokenList = [] #存放目标列表 targetList = [] for root,dirs,files in os.walk(path): for f in files: filePath = os.path.join(root,f) with open(filePath,encoding='utf-8') as f: content = f.read() # 获取新闻类别标签,并处理该新闻 target = filePath.split('\\')[-2] targetList.append(target) tokenList.append(processing(content))
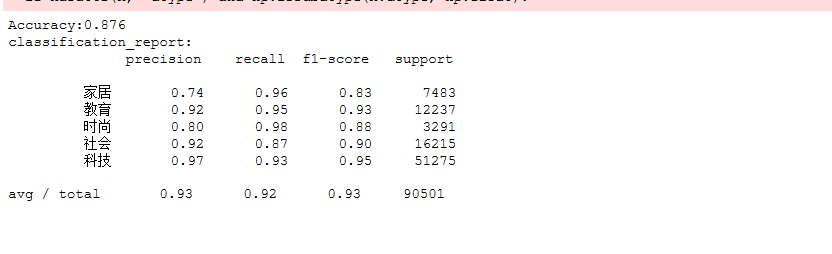
#划分数据集,并用TF-IDF来提取文本特征建立特征向量,且用高斯分布型,多项式型进行检测 from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import GaussianNB,MultinomialNB from sklearn.metrics import classification_report #划分训练集与测试集7:3 x_train,x_test,y_train,y_test = train_test_split(tokenList,targetList,test_size=0.3,stratify=targetList) #用TF-IDF来提取文本特征建立特征向量, vectorizer = TfidfVectorizer() X_train = vectorizer.fit_transform(x_train) X_test = vectorizer.transform(x_test) # 建立多项型模型进行检测 mnb = MultinomialNB() module = mnb.fit(X_train, y_train) #进行预测 y_predict = module.predict(X_test) #交叉验证检测模型 from sklearn.model_selection import cross_val_score scores=cross_val_score(mnb,X_test,y_test,cv=10) print("Accuracy:%.3f"%scores.mean()) # 输出分类指标的文本报告 print("classification_report:\n",classification_report(y_predict,y_test))
# 将预测结果和实际结果进行对比 import collections import matplotlib.pyplot as plt # 统计测试集和预测集的各类新闻个数 testCount = collections.Counter(y_test) predCount = collections.Counter(y_predict) print('实际:',testCount,'\n', '预测', predCount) # 建立标签列表,实际结果列表,预测结果列表, nameList = list(testCount.keys()) testList = list(testCount.values()) predictList = list(predCount.values()) x = list(range(len(nameList))) print("新闻类别:",nameList,'\n',"实际:",testList,'\n',"预测:",predictList)
