MySQL复制+高可用技术
一、复制
1. Binlog
Mysql的binlog日志作用是用来记录mysql内部增删改等对mysql数据库有更新的内容的记录(对数据库的改动),对数据库的查询select或show等不会被binlog日志记录;主要用于数据库的主从复制以及增量恢复。对于数据更新操作,在事务提交前要先写入Binlog。
1.1 与Redo日志的不同
redo日志是innoDB的日志,基于物理层面的日志,因为它记录的是对每个物理页的更改。
Binlog是在逻辑层面上产生的而进行日志文件,可以记录对数据行的修改或者记录SQL语句(默认)。
1.2 工作模式
MySQL binlog的三种工作模式:
(1)Row level
日志中会记录每一行数据被修改的情况,然后在slave端对相同的数据进行修改。
优点:能清楚的记录每一行数据修改的细节
缺点:数据量太大
(2)Statement level(默认)
每一条被修改数据的sql都会记录到master的bin-log中,slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql再次执行
优点:解决了 Row level下的缺点,不需要记录每一行的数据变化,减少bin-log日志量,节约磁盘IO,提高新能
缺点:容易出现主从复制不一致
(3)Mixed(混合模式)
结合了Row level和Statement level的优点
模型的选择:
- 互联网公司使用MySQL的功能较少(不用存储过程、触发器、函数),选择默认的Statement level
- 用到MySQL的特殊功能(存储过程、触发器、函数)则选择Mixed模式
- 用到MySQL的特殊功能(存储过程、触发器、函数),又希望数据最大化一直则选择Row模式
2. 复制的流程
2.1 概述
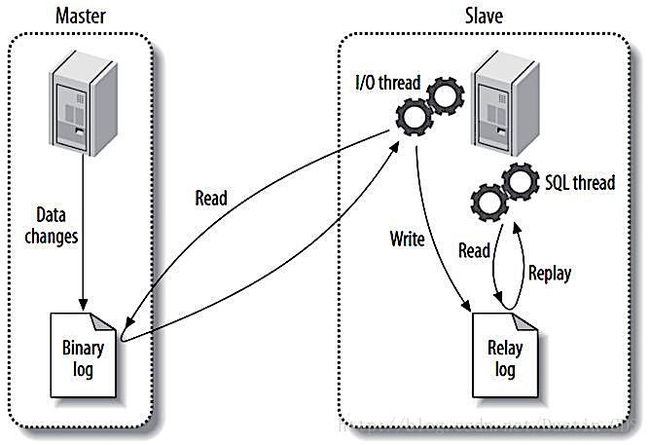
一台主库的数据可以同步到多态备库上,备库本身也可以作为另一台服务器的主库。MySQL支持基于语句的复制和基于行的复制,两种复制模式都是通过在主库上记录Binlog日志,然后在备库上进行异步重放的方式实现的。
注意:
- 所以,在同一时刻主备之间的数据是不一致的,而且延时没法保证。一些大的语句可能导致备库产生几秒、几分钟甚至几个小时的延时。
- 复制是无法扩展写操作的,只能扩展读操作和用作容灾备份。
主备复制涉及到三个线程,主库的DUMP线程,从库的IO线程和SQL线程。
(1)主库将所有操作都记录到binlog中。当复制开启时,主库的DUMP线程根据从库IO线程的请求将binlog中的内容发送到从库。
(2)从库的IO线程不会轮询,平时处于休眠状态,直到收到了DUMP线程发送的信号量才会被唤醒,将它收到的事件记录到中继日志(relay-log)中。
(3)从库的SQL线程重放relay-log中的事件。
(实际上,在MySQL 4.0之前,复制只有两个线程,master和slave端各一个。在Slave端,该线程同时负责接收主库发来的binlog事件,也负责事件的重放,所以没有使用relay-log,这样容易导致,当binlog事件的重放速度较慢时,会影响binlog事件的接受。)
2.2 主从复制步骤
基本步骤如下:
- 配置主库和从库;
- 在主库上创建复制的账号;
- 创建主库一致性快照;
- 根据主库的快照,建立从库;
- 开启复制;
(1)开启binlog并设置server-id
- 主库:
[mysqld]
log-bin=mysql-bin
server-id=1- 从库:
[mysqld]
server-id=2
#在从服务器上,可以选择不开启binlog注意:
- 在一组复制结构中,每个服务器必须配置一个唯一的server-id。该值的有效范围为1~232-1。
如果server-id设置为0的话,则MySQL会自动将它更改为1。此时,对复制没有影响。
如果server-id没有显式设置的话,则MySQL同样会将它设置为1,但是从连接的时候,IO线程会报错。
(2)主库上创建复制账号
mysql> CREATE USER 'repl'@'%.mydomain.com' IDENTIFIED BY 'slavepass';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%.mydomain.com';(3)创建主库的快照
./mysqldump -uroot -pabc -h127.0.0.1 --all-databases --master-data > dbdump.db注意:
如果不使用—master-data参数,需要在一个独立的客户端会话里执行flush all tables with read lock,以保证制作数据镜像的时候没有新的数据写入。
如果不想复制所有的数据库或者想忽略某个表,不要使用—all-databases, 分别使用下面2个参数:—database your_db_name, —ignore-table,例如,我想复制主上janey数据下除里表ta,tb以外的表命令:
./mysqldump -uroot -pabc -h127.0.0.1 --databases janey --ignore-table janey.ta --ignore-table janey.tb --master-data > dbdump.db(4)根据快照建立从库
把生成的dbdump.db文件通过scp或者其他方式拷贝到从节点上,在从节点上恢复数据:
./mysql -uroot -pabc -h127.0.0.1 < dbdump.db(5)CHANGE MASTER TO命令设置从库
mysql> CHANGE MASTER TO
MASTER_HOST='master_host_name',
MASTER_USER='replication_user_name',
MASTER_PASSWORD='replication_password',
MASTER_LOG_FILE='recorded_log_file_name',
MASTER_LOG_POS=recorded_log_position;在执行CHANGE MASTER TO命令后,从库并不会连接到主库,而只是将这些信息写入到从库数据目录下的master.info和relay-log.info中。
如果没有显式指定MASTER_LOG_FILE,则默认为空,因为此时还没有和主库建立连接,并不知道主库binlog的文件名称,只有等到和主库建立连接时才能知道。
如果MASTER_LOG_POS没有显式指定,则默认为4,即忽略binlog的头4个字节,从第一个事件开始读取。
(6)开启复制功能
mysql> start slave;
mysql> show slave status;2.3 复制的模式
MySQL的复制有三种格式。
2.3.1 基于语句的复制
Statement-based replication(SBR),即master上执行的SQL语句原封不动的在slave上重放。该复制格式在MySQL 3.23就已经出现了。
优点:
节省binlog的空间。
可用于审核,毕竟所有的DML语句都是直接记录在binlog中。
缺点:
- 很多函数在主从上执行的结果并不一致
LOAD_FILE(),UUID(), UUID_SHORT(),USER(),FOUND_ROWS(),SYSDATE(), GET_LOCK(),IS_FREE_LOCK(),IS_USED_LOCK(),MASTER_POS_WAIT(), RAND(),RELEASE_LOCK(),SLEEP(),VERSION()DELETE和UPDATE操作,带了LIMIT子句,却没有带ORDER BY,可能导致主从执行的结果并不一致。
相对于基于行的复制,master上执行INSERT … SELECT操作需要更多的行锁。
自定义函数(UDF)必须确保执行的结果是确定的。
2.3.2 基于行的复制
Row-based replication(RBR),MySQL 5.1引入的,相对于SBR,它记录的是DML操作涉及到的行。
优点:
安全。master上所有的变更都能复制到slave上。
在执行以下操作时,只需更少的行锁。
INSERT … SELECT
带有AUTO_INCREMENT列的INSERT操作
UPDATE和DELETE中,WHERE条件没有用上索引。
缺点:
会产生大量的日志。
譬如一张表有1w条记录,如果我不带任何条件执行delete操作,则在基于statement的复制中,在binlog中只会记录delete from table这一条记录,但是在基于row的复制中,则会记录1w笔记录,每笔记录类似于delete from table where ..。
这会带来以下问题:
如果利用binlog进行恢复,会需要更长的时间.
在写数据到binlog中时,因为数据量大,会导致binlog的锁定时间较长,影响数据库的并发。
较大的日志会对磁盘IO和网络IO产生较大的压力。
增大slave的延迟。
- 不会对二进制日志进行校验。
- 不推荐基于库级别的复制
2.3.3 MIXED
MIXED是上述两者的的结合,会根据执行的语句和涉及的存储引擎自动在这两种模式间切换。默认情况下,采用的是基于语句的复制模式,在遇到unsafe statements时,会切换为基于行的复制模式。
2.4 复制中涉及的文件
2.4.1 relay-log
relay-log保存着从库IO线程从主库读取到的binlog事件。和binlog格式一样,可通过mysqlbinlog解析其中的内容。可通过配置relay_log和relay_log_index参数设置relay-log和relay-log.index文件的名称。
relay-log在如下情况下会发生切换:
slave IO线程启动的时候。
执行FLUSH LOGS操作的时候。
达到参数max_relay_log_size设置的大小,默认为0,即以max_binlog_size的值作为max_relay_log_size的大小。
slave SQL线程在重放完一个relay-log文件中的所有事件后,会自动删除relay-log文件(由relay_log_purge参数控制),所以没有显式删除relay-log的命令。
2.4.2 master.info
该文件保存了主库的主机名,端口,复制账号的用户名和密码,以及从库接受主库binlog事件的位置信息,通过这些位置信息,从库的IO线程知道下次从哪里获取主库的binlog事件。
该位置信息对应于show slave status;中的Master_Log_File和Read_Master_Log_Pos。
2.4.3 relay-log.info
该文件记录从库的重放信息,这样即便数据库发生重启,SQL线程也知道该从哪里开始重放。该位置信息对应于show slave status\G中的Relay_Master_Log_File和Exec_Master_Log_Pos。
2.4.4 推荐的复制配置
sync_binlog=1
每次提交事务前都会将binlog刷新到磁盘。同理建议开启:
sync_master_info=1
sync_relay_log=1
sync_relay_info=12.5 半同步复制
从MySQL5.5开始,MySQL以插件的形式支持半同步复制。如何理解半同步呢?首先我们来看看异步,全同步的概念:
异步复制(Asynchronous replication)
MySQL默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主如果crash掉了,此时主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
全同步复制(Fully synchronous replication)
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
半同步复制(Semisynchronous replication)
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
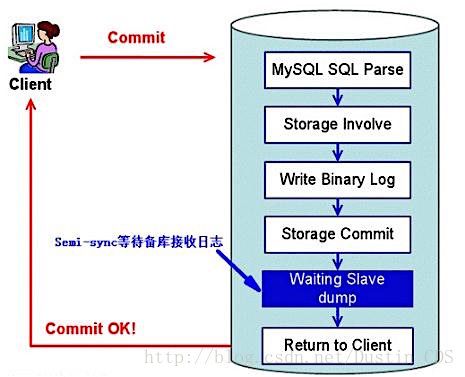
2.5.1 潜在问题
客户端事务在存储引擎层提交后,在等待从库确认的过程中,主库宕机了,此时,可能的情况有两种
事务还没发送到从库上
此时,客户端会收到事务提交失败的信息,客户端会重新提交该事务到新的主上,当宕机的主库重新启动后,以从库的身份重新加入到该主从结构中,会发现,该事务在从库中被提交了两次,一次是之前作为主的时候,一次是被新主同步过来的。
事务已经发送到从库上
此时,从库已经收到并应用了该事务,但是客户端仍然会收到事务提交失败的信息,重新提交该事务到新的主上。
2.5.2 Loss-Less半同步复制
针对上述潜在问题,MySQL 5.7引入了一种新的半同步方案:Loss-Less半同步复制。针对上面这个图,Waiting Slave dump被调整到Storage Commit之前。效果是,如果在等待从库确认的过程中,主库宕机了,事务不会被提交,也就不会生效。
3. 复制的拓扑
3.1 主->备->备
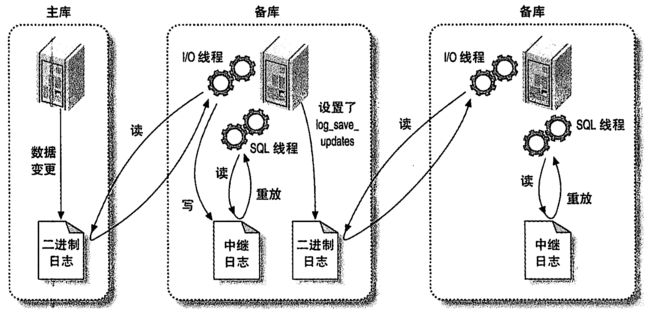
备库上设置log_slave_updates选项可以让备库变成其他服务器的备份。它的作用上备库将自己执行的事件记录到它的Binlog里。
3.2 一主多备

适用的场景是:少量写,大量读。
3.3 被动主主复制

被动模式下的主主复制是指 2台服务器地位一样, 但其中一台为只读,并且业务中也只写某1台服务器。好处是:如果供写入的服务器出了故障,能迅速的切换到从服务器,或者出于检修等目的,把写入功能切换到另一台服务器也比较方便。
拥有从服务器的主主复制,在实际应用中也很多:
3.4 主-分发-多备

二、高可用
1. 主从或主主半同步复制
使用双节点数据库,搭建单向或者双向的半同步复制。在5.7以后的版本中,由于lossless replication、logical多线程复制等一些列新特性的引入,使得MySQL原生半同步复制更加可靠。
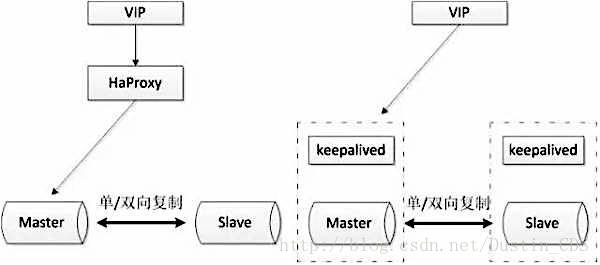
通常会和proxy、keepalived等第三方软件同时使用,即可以用来监控数据库的健康,又可以执行一系列管理命令。如果主库发生故障,切换到备库后仍然可以继续使用数据库。
2. MHA+半同步复制
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上;MHA Node运行在每台MySQL服务器上。

MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器。
3. 共享存储
共享存储实现了数据库服务器和存储设备的解耦,不同数据库之间的数据同步不再依赖于MySQL的原生复制功能,而是通过磁盘数据同步的手段,来保证数据的一致性。
3.1 SAN共享储存
SAN的概念是允许存储设备和处理器(服务器)之间建立直接的高速网络(与LAN相比)连接,通过这种连接实现数据的集中式存储。常用架构如下:
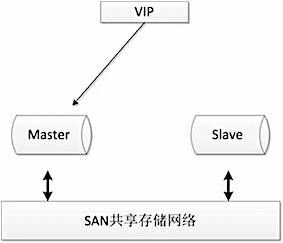
使用共享存储时,MySQL服务器能够正常挂载文件系统并操作,如果主库发生宕机,备库可以挂载相同的文件系统,保证主库和备库使用相同的数据。
3.2 DRBD磁盘复制
DRBD是一种基于软件、基于网络的块复制存储解决方案,主要用于对服务器之间的磁盘、分区、逻辑卷等进行数据镜像,当用户将数据写入本地磁盘时,还会将数据发送到网络中另一台主机的磁盘上,这样的本地主机(主节点)与远程主机(备节点)的数据就可以保证实时同步。当本地主机出现问题,远程主机上还保留着一份相同的数据,可以继续使用,保证了数据的安全。DRBD是linux内核模块实现的快级别的同步复制技术,可以与SAN达到相同的共享存储效果。