
全文共13449字,预计学习时长26分钟或更长
图片来源:https://www.pexels.com/photo/vehicles-parked-inside-elevated-parking-lot-63294/
如何让电脑识别不同的汽车品牌?想用手机拍任何一辆车就能知道车的牌子吗?本文将介绍一个能识别196种类型汽车的模型。
本模型将通过神经网络来实现目标。更准确地说,是使用一个深度神经网络,因此得名Deep CARs(深度计算机自动额定值系统)。
想要实现这一目标,需要完成两部分的学习,第1部分:构建汽车分类器;第2部分:部署分类器。本文将着重论述第1部分内容。
我们将使用一种叫做迁移学习的方法来训练分类器。

什么是迁移学习?
迁移学习是深度学习的一种方法,即为解决某个任务而开发的模型会被重复使用作为另一个任务的起点。例如,如果想要构建一个网络识别鸟类,与其从头开始编写一个复杂的模型,不如用一个现成的的模型,用于针对相同或相似任务的模型(在该实例中,可以使用一个识别其他动物的网络系统来完成任务)。迁移学习法的优势在于:学习过程更快、信息更准确,所需的训练数据也更少。在迁移学习中,现有的这个模型称为预训练模型。
大多数用于迁移学习的预训练模型都是基于大型卷积神经网络之上的。一些人使用的预训练的模型有VGGNet、ResNet、DenseNet、谷歌的Inception等等。这些网络大多是在ImageNet上训练的。ImageNet是一个庞大的数据集,包含100多万张标记图像,种类达1000个。
在Pytorch学习框架中,基于ImageNet这个庞大的数据库,很容易就能加载来自torchvision的预训练网络。这其中一些预训练模型将会用来训练这些的网络。
通过以下步骤在Google Colab之上建立模型
相关笔记:https://github.com/ivyclare/DeepCars---Transfer-Learning-With-Pytorch/blob/master/Ivy__Deep_Cars_Identifying_Car_Brands.ipynb
1. 加载数据并执行转换
2. 构建和训练模型
3. 用不可视数据测试模型
导入库
这一步只是加载库,确保GPU是打开的。由于将使用深层网络的预训练模型,所以对CPU进行训练并不是个好的选择,原因是需要它花费很长的时间。GPU与此同时执行线性代数计算,训练速度会提高100倍。
如果没有运行GPU,使用的是Colab工具的情况下,那就在电脑上点击编辑 =>电脑设置。确保运行时间设为python3 并且低于硬件加速器的速度,选择GPU。
接下来,检测cuda(统一计算设备架构)是否可行。大多数深层学习框架使用CUDA在GPU上计算前后次数。
#importing libraries
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import torch
from torchvision import datasets,transforms,models
from torch import nn,optim
import torch.nn.functional as F
from torch.utils.data import *
import time
import json
import copy
import os
from PIL import Image
from collections import OrderedDict
# check if CUDA is available
train_on_gpu = torch.cuda.is_available()
if not train_on_gpu:
print('CUDA is not available. Training on CPU ...')
else:
print('CUDA is available! Training on GPU ...')
1. 加载数据并执行转换
1.1 下载数据集
现在导入了库,从Kaggle中加载数据集:https://www.kaggle.com/c/virtual-hack/data。该数据集中包含196个汽车品牌。
图片来源:https://www.pexels.com/@pixabay
此时,下载数据集并使用Pytorch dataloader加载。因为数据将直接下载到谷歌驱动器中,所以必须获得授权访问。
#Mounting google drive inorder to access data
from google.colab import drive
drive.mount('/content/drive')
运行此操作后,单击出现的链接,登录个人帐户,单击允许,然后将生成的文本复制粘贴到你的笔记本中。这篇文章(https://towardsdatascience.com/setting-up-kaggle-in-google-colab-ebb281b61463)将阐释如何轻松获取API(应用程序编程接口)的关键,下载数据集。
添加unzip \*.zip来解压下载的文件。相关代码应该是这样的:
# Downloading the data from Kaggle
!pip install kaggle
!mkdir .kaggle
import json
token = {"username":"yourusername","key":"184ee8bd3b41486d62e7eb9257bd812d4"}
with open('/content/.kaggle/kaggle.json', 'w') as file:
json.dump(token, file)
!chmod 600 /content/.kaggle/kaggle.json
!cp /content/.kaggle/kaggle.json ~/.kaggle/kaggle.json
!kaggle config set -n path -v{/content}
!kaggle competitions download -c virtual-hack -p /content
#Unzipping dowloaded files
!unzip \*.zip
注意,有训练和测试两个目录。稍后编程员将使用模型来预测测试集的值。与此同时,必须将训练数据分为训练和验证两部分。分解之前,需要先理解什么是转换,然后编写转换条目。
1.2 数据转换
数据集下载完成后,对数据执行转换操作。转换是将数据从一种形式转换成另一种形式。两个主要的转换将应用到图像中:
· 数据扩张
在没有收集新数据的情况下,这是一种增加用于训练的数据集的多样性和大小的策略。调整大小、裁剪、水平翻转、填充甚至生成对抗网络(GANs)等技术应用于数据集上的图像,和“新”图像的生成上。这样做有两个主要优势:1.从有限数据中生成更多的数据;2.防止过度拟合。
然而,不要寄希望于在数据集中看到这些生成的图像。它们只会在分批操作期间呈现,因此,即使训练期间数据集中图像数量没有进行肉眼的增加,实际图像在训练期间也会有增加。
在模型中,应用了3种扩张策略:调整大小(随机调整大小)、裁剪(随机裁切)和水平翻转(水平翻转图像)。
对于测试数据,并不执行随机调整大小、随机旋转和随机水平翻转的转换操作。相反,只是将测试图像的规模调整到256×256,并裁剪出224×224的中心,以便能够与预训练模型一起使用。
· 数据规范化
数据扩张后,利用ImageNet中所有图像的均值和标准差将目标图像转化为一个张量从而进行规范统一。通常,大型数据集本身的平均值和标准偏差是有用到的。如果给出的数据集不是太大,ImageNet中使用的数据集为:[0.485,0.456,0.406],[0.229,0.224,0.225]
# Tansform with data augmentation and normalization for training
# Just normalization for validation
data_transforms = {
'train': transforms.Compose([
transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
#transforms.RandomResizedCrop(299), #size for inception architecture
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'valid': transforms.Compose([
#transforms.Resize(256),
transforms.CenterCrop(224),
transforms.CenterCrop(299),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
#transforms.CenterCrop(299),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],[0.229, 0.224, 0.225])
]),
}
执行这些转换后,利用Pytorch的ImageFolder来加载数据。但是需要先验证数据,所以才需要将训练集分成两部分。只有1%的数据用于验证,其余则用于训练。
#Loading in the dataset
train_dir = 'car_data/train'
test_dir = 'car_data/test'
label_dir = 'names.csv'
batch_size=32
dataset = datasets.ImageFolder(train_dir,transform=data_transforms['train'])
# splitting our data
valid_size = int(0.1 * len(dataset))
train_size = len(dataset) - valid_size
dataset_sizes = {'train': train_size, 'valid': valid_size}
# now we get our datasets
train_dataset, valid_dataset = torch.utils.data.random_split(dataset, [train_size, valid_size])
# Loading datasets into dataloader
dataloaders = {'train': DataLoader(train_dataset, batch_size = batch_size, shuffle = True),
'valid': DataLoader(valid_dataset, batch_size = batch_size, shuffle = False)}
print("Total Number of Samples: ",len(dataset))
print("Number of Samples in Train: ",len(train_dataset))
print("Number of Samples in Valid: ",len(valid_dataset))
print("Number of Classes: ",len(dataset.classes))
print(dataset.classes[0])
· 可视化标签
将标签可视化,了解文件结构。
以打印名称csv输出
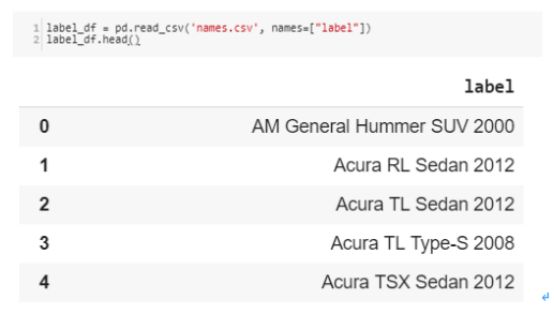
汽车的名称出现在0上面。因此,在读取csv文件时,必须添加一个标题名称以便得到正确的输出结果。需要提醒的是,标签是从0到195开始的(敲黑板)
1.3 可视化图像
现在可以加载看到这些数据。使用imshow()(来自挑战课程)的方法来显示图像。
## Method to display Image for Tensor
def imshow(image, ax=None, title=None, normalize=True):
"""Imshow for Tensor."""
if ax is None:
fig, ax = plt.subplots()
image = image.numpy().transpose((1, 2, 0))
if normalize:
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
ax.imshow(image)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.tick_params(axis='both', length=0)
ax.set_xticklabels('')
ax.set_yticklabels('')
return ax
print(" Sizes of Datasets: ", len(valid_dataset), len(train_dataset))
# Displaying Training Images
images, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(figsize=(16,5), ncols=5)
for ii in range(5):
ax = axes[ii]
#ax.set_title(label_map[class_names[labels[ii].item()]])
imshow(images[ii], ax=ax, normalize=True)
训练集里的图像看起来如下图所见。能发现其中一些图像是已经发生了翻转或旋转的变化。

转换后的训练集图像
2. 构建和训练模型
综上所述,将使用基于ImageNet的预训练模型。
构建和训练将采取的步骤如下:
2.1 加载预训练模型
接下来将尝试不同的架构比如densenet161、inceptionv3、resnet121和vggnet。在这一阶段,需要加载不同的模型,指定模型完全连接层中输入要素的数量,因为构建自定义分类器时需要这一前提。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = 'resnet' #vgg
# Densenet
if model_name == 'densenet':
model = models.densenet161(pretrained=True)
num_in_features = 2208
print(model)
# VGGNet
elif model_name == 'vgg':
model = models.vgg19(pretrained=True)
num_in_features = 25088
print(model.classifier)
# Resnet
elif model_name == 'resnet':
model = models.resnet152(pretrained=True)
#model = models.resnet34(pretrained=True)
num_in_features = 2048 #512
print(model.fc)
# Inception
elif model_name == 'inception':
model = models.inception_v3(pretrained=True)
model.aux_logits=False
num_in_features = 2048
print(model.fc)
else:
print("Unknown model, please choose 'densenet' or 'vgg'")
2.2 冻结参数,创建自定义分类器
由于预训练模型中的大多数参数都已经过训练,所以笔者并不倾向于这些数据。于是会为早期卷积层保留预训练的权重(这里的目的为特征提取)。所以,将requires_grad字段重置为错误。
在这之后,替换掉完全连接的网络,该网络与预训练的神经元拥有相同的输入、自定义隐藏层和输出内容。build_classifer方法是灵活的,当网络中不需要隐藏层或者当需要多个隐藏层时,它就会起作用。同时也定义了激活函数(在本例中是relu)和dropout层。
# Freezing parameters
for param in model.parameters():
param.require_grad = False
# Create Custom Classifier
def build_classifier(num_in_features, hidden_layers, num_out_features):
classifier = nn.Sequential()
# when we don't have any hidden layers
if hidden_layers == None:
classifier.add_module('fc0', nn.Linear(num_in_features, 196))
#when we have hidden layers
else:
layer_sizes = zip(hidden_layers[:-1], hidden_layers[1:])
classifier.add_module('fc0', nn.Linear(num_in_features, hidden_layers[0]))
classifier.add_module('relu0', nn.ReLU())
classifier.add_module('drop0', nn.Dropout(.6))
for i, (h1, h2) in enumerate(layer_sizes):
classifier.add_module('fc'+str(i+1), nn.Linear(h1, h2))
classifier.add_module('relu'+str(i+1), nn.ReLU())
classifier.add_module('drop'+str(i+1), nn.Dropout(.5))
classifier.add_module('output', nn.Linear(hidden_layers[-1], num_out_features))
return classifier
现在指定超参数和隐藏层。
#define our hidden layers
hidden_layers = None #[1050,500]
classifier = build_classifier(num_in_features, hidden_layers, 196)
print(classifier)
# Defining model hyperparameters
if model_name == 'densenet':
model.classifier = classifier
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adadelta(model.parameters()) # Adadelta #weight optim.Adam(model.parameters(), lr=0.001, momentum=0.9)
# Decay Learning Rate by a factor of 0.1 every 4 epochs
sched = optim.lr_scheduler.StepLR(optimizer, step_size=4)
elif model_name == 'vgg':
model.classifier = classifier
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.classifier.parameters(), lr=0.0001)
sched = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)
elif model_name == 'resnet':
model.fc = classifier
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
sched = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=3, threshold = 0.9)
elif model_name == 'inception':
model.fc = classifier
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001,momentum=0.9)
else:
pass
然后指定标准,指定不同的优化器,如Adam, Adadelta, SGD等,包含学习率和动量。对不同的预训练网络使用这些超参数,选择那些有用的超参数。针对resnet和vggnet使用两种不同的调度程序。具体做法如下:
torch.optim.lr_scheduler提供了几种依据epoch数量调整学习率的方法。
torch.optim.lr_scheduler.ReduceLROnPlateau(https://pytorch.org/docs/stable/optim.html#torch.optim.lr_scheduler.ReduceLROnPlateau) 允许基于一些验证测量的动态学习率降低。详情:https://pytorch.org/docs/stable/optim.html。
2.3 训练与验证
为了PyTorch训练模型,通常会在每个epoch迭代时对其执行以下操作:
· 在网络中使用前向(传播)进行前向传播
· 使用标准函数中的网络输出计算损耗
· 使用loss.backwards()对网络执行反向传播来计算梯度
· 利用优化器更新权重optimizer. step()
optimizer.zero_grad()用于归零累积梯度
早停法技术是用于防止过度拟合的。验证数据集上的性能开始下降时,该法可中止训练。当在训练过程中获得最佳精度时,它会保存模型(检查点)。这样的话,如果因断电或某原因中断训练,检查点仍可恢复,训练还可以继续进行。
该模型改编自 PyTorch Website:https://pytorch.org/tutorials/beginner/transfer_learning_tutorial.html
# Training
def train_model(model, criterion, optimizer, sched, num_epochs=5,device='cuda'):
start = time.time()
train_results = []
valid_results = []
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'valid']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
if(phase == 'train'):
train_results.append([epoch_loss,epoch_acc])
if(phase == 'valid'):
valid_results.append([epoch_loss,epoch_acc])
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))
# deep copy the model (Early Stopping) and Saving our model, when we get best accuracy
if phase == 'valid' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
model_save_name = "resnetCars.pt"
path = F"/content/drive/My Drive/{model_save_name}"
torch.save(model.state_dict(), path)
print()
# Calculating time it took for model to train
time_elapsed = time.time() - start
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Best val Acc: {:4f}'.format(best_acc))
#load best model weights
model.load_state_dict(best_model_wts)
return model,train_results,valid_results
现在训练该模型。
epochs = 60
#move model to GPU
model.to(device)
model,train_results,valid_results = train_model(model, criterion, optimizer, sched, epochs)
Epoch 1/60
----------
train Loss: 0.5672 Acc: 0.8441
valid Loss: 0.6750 Acc: 0.8329
Epoch 2/60
----------
train Loss: 0.6184 Acc: 0.8357
valid Loss: 0.5980 Acc: 0.8415
Epoch 3/60
----------
train Loss: 0.5695 Acc: 0.8487
valid Loss: 0.5503 Acc: 0.8575
...
这看起来非常有发展空间。模型似乎在每一个epoch中都进行学习。此外,模型似乎没有过度拟合,因为练训和验证度量没有太大的差异。第二次训练是通过ResNet结构得到了该模型的特定epoch结果。一开始的精确度很低,但随着时间的推移有所提高。影响精确度的超参数有很多,如优化器、调度程序、epoch数量和体系结构等。对这些值进行调整,要么精确度非常低(低到0,甚至是负值),要么从0.013这样的精度开始,随着时间间隔的增加而增加精准度(耐心是关键)。
3. 用不可视数据测试模型
一旦对验证的准确度感到满意,就加载保留的模型,在测试数据的基础上做预测。课堂比赛要求提交的是以Id,Predicted的形式放在一个csv文件夹里。这里的Id是指没有拓展的图像文件名。jpg 和Predicted属于为每个模型图像预测的类别(应该在1到196之间)。记住标签从0到195开始,所以必须在预测的类中添加1才能得到正确的值。
加载保存的模型
model.load_state_dict(torch.load('/content/drive/MyDrive/ResnetCars.pt'))
model.to(device)
现在加载测试数据集,通过数据集传播模型。因为只做了预测,所以无需计算梯度。借助torch.no_grad()来进行操作,将其设为evaluation model.eval()。开始预测。
# import pathlib libary to get filename without the extension
from pathlib import Path
# Load the datasets with ImageFolder
label_df = pd.read_csv('names.csv', names=["label"])
test_dir = 'car_data/test'
with torch.no_grad():
print("Predictions on Test Set:")
model.eval()
dataset = datasets.ImageFolder(test_dir,transform=data_transforms['test'])
testloader = torch.utils.data.DataLoader(dataset, batch_size=64,
shuffle=False, num_workers=2)
image_names = []
pred = []
for index in testloader.dataset.imgs:
image_names.append(Path(index[0]).stem)
results = []
file_names = []
predicted_car = []
predicted_class = []
for inputs,labels in testloader:
inputs = inputs.to(device)
#labels = labels.to(device)
outputs = model(inputs)
_, pred = torch.max(outputs, 1)
for i in range(len(inputs)):
file_names.append(image_names[i])
predicted_car.append(int(pred[i] + 1))
results.append((file_names, predicted_car))
得到结果之后,打印数据框架,将结果写入.csv文件,以便能将结果能上传到比赛官网上。
print("Predictions on Test Set:")
df = pd.DataFrame({'Id': image_names, 'Predicted': results})
pd.set_option('display.max_colwidth', -1)
# df = df.sort_values(by=['Id'])
df.to_csv('/content/drive/My Drive/predictions.csv')
df

提交的CSV文件
如图可以看到Khush Patel(https://medium.com/@iKhushPatel)的惊人内核(https://www.kaggle.com/ikhushpatel/ignite-car-classification-ikhushpatel-khush),以99.18%的准确率成为赢家。他使用了inceptionV3架构,以及CrossEntropyLoss 和SGD优化器。
你可以在inclass competition on Kaggle上参与进来:https://www.kaggle.com/c/virtual-hack/overview
留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:陈曼芳、孙梦琪
相关链接:
https://towardsdatascience.com/deep-cars-transfer-learning-with-pytorch-3e7541212e85
如需转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你


