用机器学习预测,手持98k化身吃鸡大师

全文共4559字,预计学习时长9分钟

近日,《绝地求生》(PUBG)MET亚洲邀请赛中国两个赛区的7支战队战队全部退赛的消息惊呆全网。

原因很简单:
“有人作弊了,官方却不管。”

《绝地求生》(PUBG)官方稍后也宣称,因不能确保MET Asia Series:PUBG Classic的竞技公平性的原因,特此声明:取消MET亚洲邀请赛为PGC输送赛区席位的资格。
线上线下哗然一片。

这是继《绝地求生:刺激战场》更名为《和平精英》,世界观大换血后又一圈内劲爆新闻,MET亚洲邀请赛为PUBG官方授权,现场徇私舞弊,无人管制,无疑为电子竞技圈又一大污点,导致不良风气乱心。
姑且不论主办方消极怠工、疏忽职守,那些涉嫌作弊的队伍和选手已然失去作为一名优秀电子竞技选手的骄傲。

是生性如此,为获胜不择手段?
还是担心水平不够,吃不到鸡?
作为普通玩家,我们又该怎样预测吃鸡玩家和比赛趋势,提高吃鸡概率?
下面小芯芯,将通过机器学习预测的方式,告诉大家如何在看比赛时成为吃鸡大师,以及更好更快地在绝地求生中吃鸡成功。


知己知彼百战不殆
《绝地求生》(PUBG)作为一款现象级电脑游戏,每月活跃玩家高达数百万。
主要背景和规则是:每场竞赛中,100名玩家乘坐飞机,被投送到一个海岛上的不同地点。他们必须搜寻物资、武器并与其他玩家展开大逃杀,直至最后一人存活。每位玩家可以选择与最多三名其他玩家组队或单人游戏。同时,玩家还必须在不断缩小和移动的“毒圈”内部活动。

接下来,我们将尝试在机器学习中完成特征工程,包括误差分析、特征空间评估、集成和调试处理,具体的实验工具为Weka和Lightside。
注意!这篇文章不会教授任何代码,但可以展示一个机器学习过程的综合案例,包括数据清理、数据集拆分、交叉验证和特性设计。
注意!前方高能!
第一步:数据收集
数据集传送门:
https://www.kaggle.com/c/pubg-finish-placement-prediction_blank
Kaggle中的数据集为本实验提供了超过445万个实例和28个特征。其中有代表每局游戏的匹配ID、代表每个队伍的队伍ID(从1到4不等)以及代表每个玩家的玩家ID。我们将数据格式化以确保一个实例仅统计一名玩家的赛后数据。特征则包括玩家在游戏中的表现,如扶起队友的次数、击杀次数、步行距离等。还有一些外部排名特征来表示玩家在游戏中的表现。每场游戏的最终排名百分位数为0-1(1表示第一名而0表示最后一名),我们将该百分位数重建为最终预测类。
本文选择“组队”模式,玩家可以匹配一个1-4人的小队与其他队伍对抗,因为数据集中的很多特征都与队伍表现有关。我们将代表每个玩家的实例转换为代表每个组的实例,并获取特征的平均值和一些标准偏差。每局游戏都任意选取两个队伍,看看哪一队排名更高。在训练集和测试集中,将最终排名百分位数转换为“获胜预测”,该值可以显示排名较高的队伍,以实现二元预测。

另外还添加了一些有意义的特征进行比较,将这些特征的差异也作为值,例如队伍人数差异、击杀等级差异、步行距离差异和装备获取数量差异。数据清理方面,删除了不合理的数据,例如同一局游戏中的重复玩家、负排名和人数大于4的队伍。
同时还按照随机顺序拆分数据集,拆分比例如下:交叉验证集70%,开发集20%,测试集10%。我们想预测的是,一局游戏中随机挑选两个队伍,哪个队伍会获胜,因此,该预测的分类是winnerPrediction。清理数据后,共有6576个实例,65个特征。在获胜预测中,“队伍二”和“队伍一”在每个拆分数据集中各占大约50%。
第二步:数据探索
首先对开发集进行了探索性数据分析,以更好地了解数据。以下是一些有趣的发现。
玩家更喜欢单排还是组队?
队伍规模的分布非常相似,集中在1人小队和2人小队。看来大多数玩家更喜欢单排或双排。

刚枪的队伍是否更有可能吃鸡?
用队伍二的击杀等级减去队伍一的击杀等级可以得出击杀等级差异分布,数据分析发现该差异呈正态分布。因此,在下图右侧,Y轴为正数时,队伍二排名较低,下图左侧,Y轴为负数时,队伍二排名较高。红色区域为队伍二获胜,蓝色区域则为队伍一获胜。下图表明,大多数情况下,击杀等级高的队伍更有可能吃鸡。

移动和隐蔽,哪种策略更好?
用队伍二的步行距离减去队伍一的步行距离可以得出步行距离差异分布,同样呈正态分布。因此,图的右侧Y轴为正数时,队伍二的步行距离大于队伍一,图的左侧Y轴为负数时,队伍二的步行距离小于队伍一。红色区域为队伍二获胜,蓝色区域则为队伍一获胜。下图表明,大多数情况下,移动距离更多的队伍更有可能吃鸡。

第三步:数据误差分析和检验
我们选择从逻辑回归开始,因为所有的特征都是数字数据,预测也是二进制的,权重模型会非常实用。而用树状模型分析65个特征费时费力。分析的基线性能如下(准确率0.8905,kappa系数0.7809)。
1. 水平差异分析
一些实例预测队伍二会获胜,但实际是队伍一获胜,首先检查了这部分实例,即将水平差异由大到小排序,然后查看权重相对较大的特征。我们发现,步行距离差异有较大的水平差异和特征权重。步行距离差异是由同一场比赛中队伍二的步行距离减去队伍一的步行距离计算得出的,因此负数表示队伍二走得较少,正数表示队伍二走得较多。这意味着,步行距离越多就越有可能吃鸡(这在游戏中很重要,关乎玩家的生存时间)。但是也有例外,可能某个队伍喜欢刚枪,经常在野外移动,导致很快就被淘汰,而另一组则打得更谨慎,大部分藏匿在一个地点,最终存活时间更长。
为了进一步解决这个问题,我们还下载了CSV文件中的预测标签,查看了那些预测队伍二获胜而实际队伍一获胜的实例,然后将步行距离差异从大到小排列,以便查看队伍二步行距离更长却输掉游戏的特例。
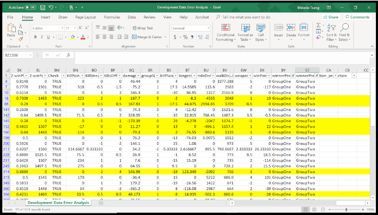
我们发现有时队伍二步行距离确实比队伍一长,但队伍一载具移动距离更长(在游戏中,玩家可以选择驾驶发现的载具)。如下图标黄的实例所示,很多队伍步行距离确实没有其他队伍长,但驾驶距离要长得多。同时,驾驶距离也是第二大水平特征差异。因此,仅仅测量步行距离或驾驶距离都不能很好地表示总移动距离。这两个特性似乎都存在一定问题,需要更合适的表示方法。
因此,我们结合步行距离和驾驶距离提出了3点新特征:队伍一、队伍二的总移动距离以及两队之间的距离差异。
我们在开发集中测试了新的特征空间,取得了一项不起眼的改进。虽然不起眼,预测队伍二获胜但实际队伍一获胜的实例减少了5个,并且预测结果更正为队伍一。
然而将其应用于交叉验证集时,性能却降低了。最合理的解释就是这项改进在开发集中过度拟合,并且没有推广到新数据集中。

2. 垂直差异分析
紧接着,通过检查垂直绝对差异进行另一项误差分析。由于新的开发集会引入更多误差,导致实例预测队伍一获胜但实际是队伍二获胜,我们的目标就是弄清楚,在这些实例中,队伍一和队伍二有何相似之处。击杀排名第1的特征垂直差异较小,但特征权重较大。该排名仅反映队伍一的击杀量排名。队伍一的获胜平均击杀排名是34,失败平均击杀排名是43。例外是,有时队伍一的击杀排名达到了34但仍输了。前面已经提到了,有时候一个队伍更喜欢刚枪,所以击杀敌人更多,击杀排名更高,但同时他们被击杀的风险也就越大。
此处的启示是,逻辑回归擅长全局分析,但也可能会受到一些极端情况的影响。因此需要一种可以忽略极端例外情况的算法,且一次仅查看一组较小的数据。决策树是一个不错的模型,但由于总共有68个数字数据特征,所以决策树需要花费大量时间来构建模型。但是,如果综合决策树和逻辑回归的优点呢?逻辑模型树(LMT)是一个很好的选择,因为它可以捕获非线性模式和更大的差异。于是我们开始尝试LMT,并将结果与其他两种算法的结果进行比较,最终发现开发集有了明显的改进。
将该模型应用于交叉验证集,同样取得了显著的改进。

3. 集成
Boosting算法可以在迭代过程中对先前模型分类错误的实例进行专项检查,因此在该研究中,Boosting是提高准确度的好方法。于是尝试在开发集中使用配备了LMT分类器的AdaBoost,可是性能下降了。
由于特征空间相对复杂,接下来试图减少可能成为坏指标的特征。尝试属性选择分类器并使用主体成分作为属性评估器,因为主体成分可以减少特征空间的维数,同时尽可能地保留信息。但最终性能还是下降了。
然后又尝试了cfs子集评估器,因为很多特征都是相互关联的(例如击杀排名和击杀得分)。该评估器可以有选择性地保留特征之间有用的关联,防止特征重复,但性能依然不及基线性能。
接下来又尝试了另一个不错的评估器——SVM属性评估器,因为它采用的是向后选择法,适用于较大的特征空间,但是Weka和Lightside不支持这种方法。
4. 特征空间评估
除了之前尝试过的包装器(wrapper)方法外,我们还想知道过滤器(filter)方法是否可以提升性能,因为过滤器可以单独选择算法以外的特征。
再次尝试了属性选择评估器,同样将主体成分作为评估器。三种不同的空间分别为原始特征空间(68个特征)、40个特征和20个特征,并且做了一个实验来测试这三种特征空间。但其他两种新的特征空间均降低了性能。我们又测试了其他评估器,结果不变,最后决定维持原特征空间。
5. 调试处理
我们想调试LMT算法中的两个参数。实例最小数量的默认值是15,但我们想改成50,看看加入更多节点拆分的实例能否提升每个节点的准确性,从而提升整体性能。Boosting迭代的默认值是-1,这表明没有迭代。我们想将默认值改为3,测试一下是否能提升分类精确度。
因此,我们测试了以下四种设定:(1)节点拆分实例最小数量为15,Boosting迭代值为-1(即无迭代),(2)实例数量为50,Boosting迭代值为-1,(3)实例数量为15,Boosting迭代值为3,(4)实例数量为50,Boosting迭代值为3。注意,设定(1)为默认设定。将精确度作为性能的衡量标准。
阶段1:
(1) 90.81 (2) 90.81 (3) 91.05(4) 91.05
设定(3)的精确度最高,且比设定(4)更加简洁,因此设定(3)为理想设定。
阶段2:

根据阶段1的数据,设定(3)为理想设定。在阶段2中,依然将设定(3)作为每一个fold函数的理想设定。在本例中,没有进行任何重要的测试,也没有证据证明这种优化是有价值的。
似乎各节点实例的最小权重对模型性能的影响并不大。但是,增加迭代次数可能会提高多次尝试的准确性。
如果在一个全新的数据集中使用设定(3),我们估计最终性能的分类精度会在91.66左右,这是在5个fold函数中进行性能测试得出的平均精度。
第四步:最终评估
最后,用LMT在交叉验证集中训练了一个模型,并使用了设定(3)。从误差分析中添加了3个新特征后,我们保持特征空间不变。从最终测试集中得出的最终性能为:精确度0.9179,接近调试处理中的估计值,而Kappa系数为0.8359。

树状图
观察上图可以发现,模型的起始点是步行距离差异,从驾驶和移动距离差异的某个值开始分裂,这证明了我们在误差分析中新增特征的重要性。虽然一些节点仅与一个队伍相关,例如2-killStreaks,但很多其他节点都共用了两个队伍的差异,甚至用到了winPoints的标准差。这也体现了保留原始特征同时添加组合特征的实用性。
吾日三省吾身
缜密计算后,本次项目分析依然还存在一些缺陷:
第一,只测试了其中一种游戏模式的数据,测试结果可能不适用于所有模式。
第二,没有预测排名,而是将项目范围转换为二进制分类。我们从一局游戏中随机选出两个队伍,尝试预测哪个队伍会获胜。如此一来,就删除了其他队伍的表现,同时也就删除了一些相关的差异和因素,这也可能会影响真实对战中的结果预测。
综上所述,我们通过机器学习预测的方式发现了一些影响游戏结果的重要因素,并且可以用机器“快、狠、准”预测一局游戏中的吃鸡玩家和比赛趋势,成为名副其实的业内行家、吃鸡大师。


留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:黄琎、温媛
相关链接:
https://towardsdatascience.com/how-do-we-survive-in-pubg-903e261b260
如需转载,请后台留言,遵守转载规范
推荐文章阅读
ACL2018论文集50篇解读
EMNLP2017论文集28篇论文解读
2018年AI三大顶会中国学术成果全链接
ACL2017 论文集:34篇解读干货全在这里
10篇AAAI2017经典论文回顾
长按识别二维码可添加关注
读芯君爱你