File Descriptors
One of the first things a UNIX programmer learns is that every running program starts with three files already opened:
| Descriptive Name | Short Name | File Number | Description |
|---|---|---|---|
| Standard In | stdin | 0 | Input from the keyboard |
| Standard Out | stdout | 1 | Output to the console |
| Standard Error | stderr | 2 | Error output to the console |

This raises the question of what an open file represents. The value returned by an open call is termed a file descriptor and is essentially an index into an array of open files kept by the kernel.
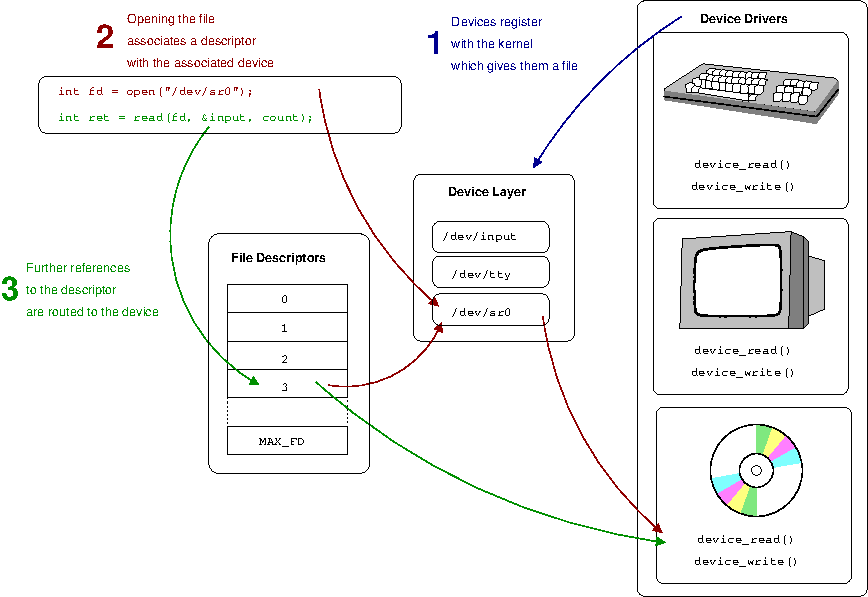
File descriptors are an index into a file descriptor table stored by the kernel. The kernel creates a file descriptor in response to an open call and associates the file descriptor with some abstraction of an underlying file-like object, be that an actual hardware device, or a file system or something else entirely. Consequently a process's read or write calls that reference that file descriptor are routed to the correct place by the kernel to ultimately do something useful.
In short, the file descriptor is the gateway into the kernel's abstractions of underlying hardware. An overall view of the abstraction for physical-devices is shown in Figure 1.3, “Abstraction”.
Starting at the lowest level, the operating system requires a programmer to create a device driver to be able to communicate with a hardware device. This device driver is written to an API provided by the kernel just like in Example 1.2, “Abstraction in include/linux/virtio.h”; the device driver will provide a range of functions which are called by the kernel in response to various requirements. In the simplified example above, we can see the drivers provide a read and write function that will be called in response to the analogous operations on the file descriptor. The device driver knows how to convert these generic requests into specific requests or commands for a particular device.
To provide the abstraction to user-space, the kernel provides a file-interface via what is generically termed a device layer. Physical devices on the host are represented by a file in a special file system such as /dev. In UNIX-like systems, so-called device-nodes have what are termed a major and a minor number, which allow the kernel to associate particular nodes with their underlying driver. These can be identified via ls as illustrated in Example 1.3, “Example of major and minor numbers”.
$ ls -l /dev/null /dev/zero /dev/tty
crw-rw-rw- 1 root root 1, 3 Aug 26 13:12 /dev/null
crw-rw-rw- 1 root root 5, 0 Sep 2 15:06 /dev/tty
crw-rw-rw- 1 root root 1, 5 Aug 26 13:12 /dev/zero
This brings us to the file descriptor, which is the handle user-space uses to talk to the underlying device. In a broad sense, what happens when a file isopened is that the kernel is using the path information to map the file descriptor with something that provides an appropriate read and write, etc., API. When this open is for a device (/dev/sr0 above), the major and minor number of the opened device node provides the information the kernel needs to find the correct device driver and complete the mapping. The kernel will then know how to route further calls such as read to the underlying functions provided by the device driver.
A non-device file operates similarly, although there are more layers in between. The abstraction here is the mount point; mounting a file system has the dual purpose of setting up a mapping so the file system knows the underlying device that provides the storage and the kernel knows that files opened under that mount-point should be directed to the file system driver. Like device drivers, file systems are written to a particular generic file system API provided by the kernel.
There are indeed many other layers that complicate the picture in real-life. For example, the kernel will go to great efforts to cache as much data from disks as possible in otherwise-free memory; this provides many speed advantages. It will also try to organise device access in the most efficient ways possible; for example trying to order disk-access to ensure data stored physically close together is retrieved together, even if the requests did not arrive in sequential order. Further, many devices are of a more generic class such as USB or SCSI devices which provide their own abstraction layers to write to. Thus, rather than writing directly to devices, file systems will go through these many layers. Understanding the kernel is to understand how these many APIs interrelate and coexist.
The Shell
The shell is the gateway to interacting with the operating system. Be it bash, zsh, csh or any of the many other shells, they all fundamentally have only one major task — to allow you to execute programs (you will begin to understand how the shell actually does this when we talk about some of the internals of the operating system later).
But shells do much more than allow you to simply execute a program. They have powerful abilities to redirect files, allow you to execute multiple programs simultaneously and script complete programs. These all come back to the everything is a file idiom.
Redirection
Often we do not want the standard file descriptors mentioned in the section called “File Descriptors” to point to their default places. For example, you may wish to capture all the output of a program into a file on disk or, alternatively, have it read its commands from a file you prepared earlier. Another useful task might like to pass the output of one program to the input of another. With the operating system, the shell facilitates all this and more.
| Name | Command | Description | Example |
|---|---|---|---|
| Redirect to a file | > filename |
Take all output from standard out and place it into filename. Note using>> will append to the file, rather than overwrite it. |
ls > filename |
| Read from a file | < filename |
Copy all data from the file to the standard input of the program | echo < filename |
| Pipe | program1 | program2 |
Take everything from standard out of program1 and pass it to standard input of program2 |
ls | more |
Implementing pipe
The implementation of ls | more is just another example of the power of abstraction. What fundamentally happens here is that instead of associating the file descriptor for the standard-output with some sort of underlying device (such as the console, for output to the terminal), the descriptor is pointed to an in-memory buffer provided by the kernel commonly termed a pipe. The trick here is that another process can associate its standard input with the other side of this same buffer and effectively consume the output of the other process. This is illustrated in Figure 1.4, “A pipe in action”.
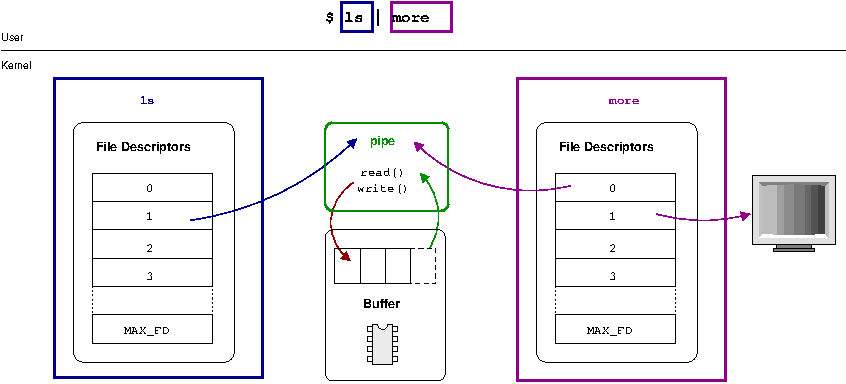
The pipe is an in-memory buffer that connects two processes together. file descriptors point to the pipe object, which buffers data sent to it (via a write) to be drained (via a read).
Writes to the pipe are stored by the kernel until a corresponding read from the other side drains the buffer. This is a very powerful concept and is one of the fundamental forms of inter-process communication or IPC in UNIX-like operating systems. The pipe allows more than just a data transfer; it can act as a signaling channel. If a process reads an empty pipe, it will by default block or be put into hibernation until there is some data available (this is discussed in much greater depth in Chapter 5, The Process). Thus two processes may use a pipe to communicate that some action has been taken just by writing a byte of data; rather than the actual data being important, the mere presence of any data in the pipe can signal a message. Say for example one process requests that another print a file — something that will take some time. The two processes may set up a pipe between themselves where the requesting process does a read on the empty pipe; being empty, that call blocks and the process does not continue. Once the print is done, the other process can write a message into the pipe, which effectively wakes up the requesting process and signals the work is done.
Allowing processes to pass data between each other like this springs another common UNIX idiom of small tools doing one particular thing. Chaining these small tools gives flexibility that a single monolithic tool often can not.