详解scheduleAtFixedRate与scheduleWithFixedDelay原理
前言
前几天,肥佬分享了一篇关于定时器的文章你真的会使用定时器吗?,从使用角度为我们详细地说明了定时器的用法,包括 fixedDelay、fixedRate,为什么会有这样的区别呢?下面我们从源码角度分析下二者的区别与底层原理。
jdk 定时器
这里不再哆嗦延迟队列、线程池的知识了,请移步下面的链接
- 延迟队列原理,http://cmsblogs.com/?p=2448
- 线程池原理,http://cmsblogs.com/?p=2448
可能大家对 ScheduledThreadPoolExecutor 并不陌生,它便是我们常用的定时器,即便如此,仍然有很多小伙伴使用 API 的姿势不正确,更别说底层原理了。我非常负责任地告诉你,定时器的原理很简单,我们可以把它看成是延迟队列 + 线程池的加强版,我们都知道线程池需要从队列中获取任务,如果我们在指定的时间(定时调度)才能从队列中获取任务,那么这个调度任务便可以在指定时间被执行。那么如何才能在指定时间从队列中获取任务呢?这个得借助延迟队列(java.util.concurrent.ScheduledThreadPoolExecutor.DelayedWorkQueue),如果延迟队列达到临界条件那么这个任务便可以出队列了(临界条件:当前时间已经到达下次运行时间 nextRunTime ),然后由线程池中的线程获取到该任务并运行该任务。
下图描述了 ScheduledThreadPoolExecutor 的原理,线程从延迟队列中阻塞获取任务,直到该任务到达下一次运行时间,线程拿到该任务后调用任务的 run() 方法执行任务,运行完之后,设置下一次运行的时间,再扔到延迟队列中,这样便又可以在下一次调度时间拿到该任务,并调度该任务,从而构成一个闭环操作,完成任务的定时调度,这个便是调度线程池的核心原理了。
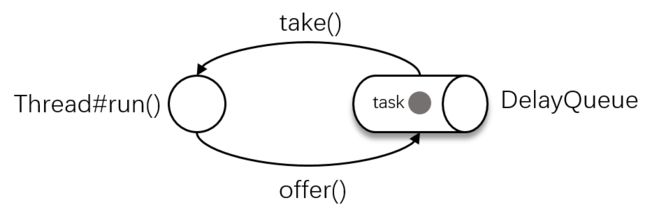
我们熟悉的 scheduleAtFixedRate、scheduleWithFixedDelay 方法,还有 cron 表达式,他们的主要区别在于计算下一次调度时间的逻辑不同,这样导致调度的效果有很大的区别
我们先来看看类图:
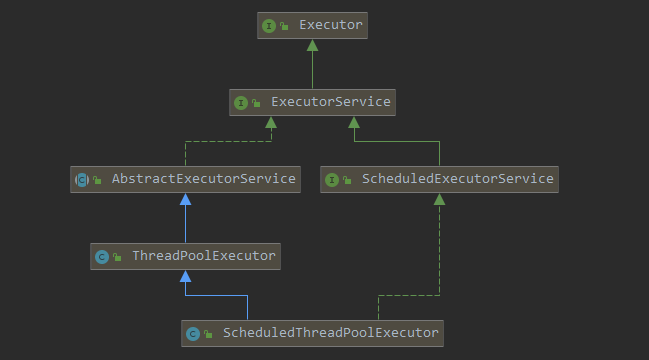
由类图可知,ScheduledThreadPoolExecutor 继承至线程池 ThreadPoolExecutor,并且它提供了 schedule、scheduleAtFixedRate、scheduleWithFixedDelay 方法的扩展
schedule(Runnable command, long delay, TimeUnit unit):在指定的延迟时间(delay)之后调度,并且只会调度一次scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit):在指定的延迟时间(delay)调度第一次,后续以period为一个时间周期进行调度,该方法并不 care 每次任务执行的耗时,如果某次耗时超过调度周期(period),则下一次调度从上一次任务结束时开始scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit):在指定的延迟时间(delay)调度第一次,后续以period为一个时间周期进行调度,该方法非常 care 上一次任务执行的耗时,如果某次耗时超过调度周期(period),则下一次调度时间为上一次任务结束时间+调度周期时间
其实从字面意思,也可以猜测其运行效果,at 是指到达对应的时间点,而 with 是有夹带的意思
下面我们来分析一波源码
scheduleAtFixedRate & scheduleWithFixedDelay
scheduleAtFixedRate 方法的逻辑很简单,只是构造了一个 ScheduledFutureTask 任务,然后丢到延迟队列中,具体的代码如下所示:
public ScheduledFuture scheduleAtFixedRate(Runnable command,
long initialDelay,
long period,
TimeUnit unit) {
// 省略参数校验代码......
ScheduledFutureTask sft =
new ScheduledFutureTask(command,
null,
triggerTime(initialDelay, unit), // (1)
unit.toNanos(period));
RunnableScheduledFuture t = decorateTask(command, sft); // (2)
sft.outerTask = t;
delayedExecute(t); // (3)
return t;
}
- (1). 构造
ScheduledFutureTask对象,triggerTime方法计算了第一次调度的时间,unit.toNanos(period)也是将调度周期转换为纳秒,这个地方便是scheduleAtFixedRate和scheduleWithFixedDelay方法的主要区别,后者传入的是负数unit.toNanos(-period) - (2). 包装
ScheduledFutureTask,方便子类扩展 - (3). 将任务丢到延迟队列中,并且创建线程,然后线程会从延迟队列中阻塞获取队列中的任务,然后再就是运行任务了,再然后请看下文的分析
ScheduledFutureTask 是一个内部类,它实现了 Runnable 接口,构造函数如下所示,我们重点关注下第三个、第四个参数 ns、period,ns 参数会赋值给成员变量 time 代表任务第一次调度的时间,而 period 代表调度周期,scheduleAtFixedRate 方法传入 period 的是正数,scheduleWithFixedDelay 传入的是负数。
ScheduledFutureTask(Runnable r, V result, long ns, long period) {
super(r, result);
this.time = ns;
this.period = period;
this.sequenceNumber = sequencer.getAndIncrement();
}
ScheduledFutureTask 被扔到延迟队列中,那什么时候可以出队列呢?它实现了 Delayed 接口,如果该值返回负数便可以出队列了(调度时间小于当前时间)。出队列后,然后由线程池中的 Thread 调用其 run() 方法.
public long getDelay(TimeUnit unit) {
return unit.convert(time - now(), NANOSECONDS);
}
public void run() {
boolean periodic = isPeriodic(); // (1)
if (!canRunInCurrentRunState(periodic))
cancel(false);
else if (!periodic)
ScheduledFutureTask.super.run(); // (2)
else if (ScheduledFutureTask.super.runAndReset()) { // (3)
setNextRunTime(); // (4)
reExecutePeriodic(outerTask); // (5)
}
}
- (1). 判断是不是周期性调度,通过构造函数传入的
period值判断,如果大于0,则说明是周期性调度,否则只调度一次 - (2). 如果不是周期性调度,只调度一次
- (3). 运行调度任务
- (4).
setNextRunTime方法会计算下一次运行时间(重要) - (5). 将任务重新丢到队列中,如果有必要的话,会创建线程来执行任务
分析到这里,调度线程池的原理已经水落石出了,我们再来研究下 setNextRunTime。前面也说了,scheduleAtFixedRate、scheduleWithFixedDelay 这两个 api 方法传递的 period 值是有正负之分的,因此计算下一次调度时间也是有差异的,具体代码如下:
private void setNextRunTime() {
long p = period;
if (p > 0)
time += p; // (1)
else
time = triggerTime(-p); // (2)
}
scheduleAtFixedRate方法对应的调度周期period大于0,走逻辑(1),下一次调度时间 = 上一次调度时间 + 调度周期,试想如果任务执行的耗时大于调度周期period,那么指定的下一次调度时间会小于当前时间,意味着这个任务又可以从延迟队列中移出,立马被执行scheduleWithFixedDelay方法对应的period小于0,走逻辑(2),变量 p 是负责,调用triggerTime方法得到的时间是 当前时间(当前任务结束时间) + 调度周期,由此可见,上一次任务的执行结束时间起到了关键作用,不管上一次任务耗时是否超过period周期,下一次任务的开始时间始终从上一次结束时间开始计算
写在最后
关于 spring-schedule 的代码,在此不再做过多的分析,底层实现仍然是 jdk 的定时器 ScheduledThreadPoolExecutor,而我们熟悉的 cron 表达式便是计算下一次调度时间的关键,感兴趣的同学可以查看以下相关代码
- ScheduledAnnotationBeanPostProcessor,处理
Scheduled注解,封装任务并交给定时器执行 - org.springframework.scheduling.support.CronTrigger,根据
cron表达式计算下一次调度时间