quartz定时器
一、关于 Quartz

-
Quartz 是一个完全由 Java 编写的开源作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制。
-
Quartz 可以与 J2EE 与 J2SE 应用程序相结合也可以单独使用。
-
Quartz 允许程序开发人员根据时间的间隔来调度作业。
-
Quartz 实现了作业和触发器的多对多的关系,还能把多个作业与不同的触发器关联。
二、Quartz 核心概念

核心组件
-
Scheduler:调度容器
-
Job:Job接口类,即被调度的任务
-
JobDetail :Job的描述类,job执行时的依据此对象的信息反射实例化出Job的具体执行对象。
-
Trigger:触发器,存放Job执行的时间策略。用于定义任务调度时间规则。
-
JobStore: 存储作业和调度期间的状态
-
Calendar:指定排除的时间点(如排除法定节假日)
job
Job 是一个接口,只有一个方法 void execute(JobExecutionContext context),开发者实现接口来定义任务。JobExecutionContext 类提供了调度上下文的各种信息。Job 运行时的信息保存在 JobDataMap 实例中。例如:
public class HelloJob implements BaseJob {
private static Logger _log = LoggerFactory.getLogger(HelloJob.class);
public HelloJob() { }
public void execute(JobExecutionContext context) throws JobExecutionException {
_log.error("Hello Job执行时间: " + new Date());
}
}
JobDetailImpl 类 / JobDetail 接口
JobDetailImpl类实现了JobDetail接口,用来描述一个 job,定义了job所有属性及其 get/set 方法。下面是 job 内部的主要属性:
| 属性名 |
说明 |
| class |
必须是job实现类(比如JobImpl),用来绑定一个具体job |
| name |
job 名称。如果未指定,会自动分配一个唯一名称。所有job都必须拥有一个唯一name,如果两个 job 的name重复,则只有最前面的 job 能被调度 |
| group |
job 所属的组名 |
| description |
job描述 |
| durability |
是否持久化。如果job设置为非持久,当没有活跃的trigger与之关联的时候,job 会自动从scheduler中删除。也就是说,非持久job的生命期是由trigger的存在与否决定的 |
| shouldRecover |
是否可恢复。如果 job 设置为可恢复,一旦 job 执行时scheduler发生hard shutdown(比如进程崩溃或关机),当scheduler重启后,该job会被重新执行 |
| jobDataMap |
除了上面常规属性外,用户可以把任意kv数据存入jobDataMap,实现 job 属性的无限制扩展,执行 job 时可以使用这些属性数据。此属性的类型是JobDataMap,实现了Serializable接口,可做跨平台的序列化传输 |
Trigger
是一个类,描述触发Job执行的时间触发规则。主要有 SimpleTrigger 和 CronTrigger 这两个子类。当仅需触发一次或者以固定时间间隔周期执行,SimpleTrigger是最适合的选择;而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如每早晨9:00执行,周一、周三、周五下午5:00执行等;
以下是 trigger 的属性:
| 属性名 |
属性类型 |
说明 |
| name |
所有trigger通用 |
trigger名称 |
| group |
所有trigger通用 |
trigger所属的组名 |
| description |
所有trigger通用 |
trigger描述 |
| calendarName |
所有trigger通用 |
日历名称,指定使用哪个Calendar类,经常用来从trigger的调度计划中排除某些时间段 |
| misfireInstruction |
所有trigger通用 |
错过job(未在指定时间执行的job)的处理策略,默认为MISFIRE_INSTRUCTION_SMART_POLICY。详见这篇blog^Quartz misfire |
| priority |
所有trigger通用 |
优先级,默认为5。当多个trigger同时触发job时,线程池可能不够用,此时根据优先级来决定谁先触发 |
| jobDataMap |
所有trigger通用 |
同job的jobDataMap。假如job和trigger的jobDataMap有同名key,通过getMergedJobDataMap()获取的jobDataMap,将以trigger的为准 |
| startTime |
所有trigger通用 |
触发开始时间,默认为当前时间。决定什么时间开始触发job |
| endTime |
所有trigger通用 |
触发结束时间。决定什么时间停止触发job |
| nextFireTime |
SimpleTrigger私有 |
下一次触发job的时间 |
| previousFireTime |
SimpleTrigger私有 |
上一次触发job的时间 |
| repeatCount |
SimpleTrigger私有 |
需触发的总次数 |
| timesTriggered |
SimpleTrigger私有 |
已经触发过的次数 |
| repeatInterval |
SimpleTrigger私有 |
触发间隔时间 |
Calendar
org.quartz.Calendar和 java.util.Calendar不同,它是一些日历特定时间点的集合(可以简单地将org.quartz.Calendar看作java.util.Calendar的集合——java.util.Calendar代表一个日历时间点,无特殊说明后面的Calendar即指org.quartz.Calendar)。一个Trigger可以和多个Calendar关联,以便排除或包含某些时间点。假设,我们安排每周星期一早上10:00执行任务,但是如果碰到法定的节日,任务则不执行,这时就需要在Trigger触发机制的基础上使用Calendar进行定点排除。
Scheduler
调度器,代表一个Quartz的独立运行容器,好比一个『大管家』,这个大管家应该可以接受 Job, 然后按照各种Trigger去运行,Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。Scheduler定义了多个接口方法,允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
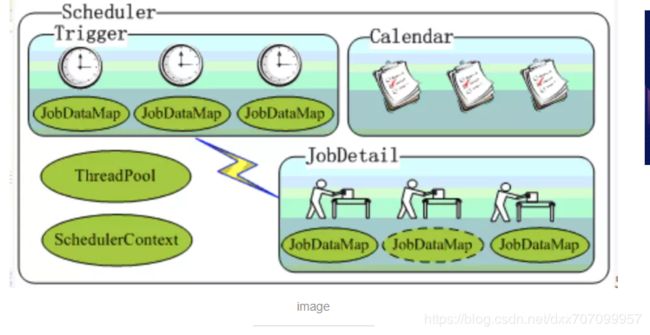
Scheduler 可以将 Trigger 绑定到某一 JobDetail 中,这样当 Trigger 触发时,对应的 Job 就被执行。可以通过 SchedulerFactory创建一个 Scheduler 实例。Scheduler 拥有一个 SchedulerContext,它类似于 ServletContext,保存着 Scheduler 上下文信息,Job 和 Trigger 都可以访问 SchedulerContext 内的信息。SchedulerContext 内部通过一个 Map,以键值对的方式维护这些上下文数据,SchedulerContext 为保存和获取数据提供了多个 put() 和 getXxx() 的方法。可以通过Scheduler# getContext()获取对应的SchedulerContext实例;
ThreadPool
Scheduler 使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提高运行效率。
进行一个定时任务的简单实例
public class JobTest implements BaseJob {
private static org.slf4j.Logger log = LoggerFactory.getLogger(JobTest.class);
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
log.error("JobTest 执行时间: " + new Date());
}
}
@Testpublic void quartzTest() throws SchedulerException{
// 1. 创建 SchedulerFactory
SchedulerFactory factory = new StdSchedulerFactory();
// 2. 从工厂中获取调度器实例
Scheduler scheduler = factory.getScheduler();
// 3. 引进作业程序
JobDetail jobDetail = JobBuilder.newJob(JobTest.class).withDescription("this is a ram job") //job的描述
.withIdentity("jobTest", "jobTestGrip") //job 的name和group
.build();
long time= System.currentTimeMillis() + 3*1000L; //3秒后启动任务
Date statTime = new Date(time);
// 4. 创建Trigger
//使用SimpleScheduleBuilder或者CronScheduleBuilder
Trigger trigger = TriggerBuilder.newTrigger()
.withDescription("this is a cronTrigger")
.withIdentity("jobTrigger", "jobTriggerGroup")
//.withSchedule(SimpleScheduleBuilder.simpleSchedule())
.startAt(statTime) //默认当前时间启动
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?")) //两秒执行一次
.build();
// 5. 注册任务和定时器
scheduler.scheduleJob(jobDetail, trigger);
// 6. 启动 调度器
scheduler.start();
_log.info("启动时间 : " + new Date());
}
三、Quartz 设计分析
quartz.properties文件
Quartz 有一个叫做quartz.properties的配置文件,它允许你修改框架运行时环境。缺省是使用 Quartz.jar 里面的quartz.properties 文件。你应该创建一个 quartz.properties 文件的副本并且把它放入你工程的 classes 目录中以便类装载器找到它。
// 调度标识名 集群中每一个实例都必须使用相同的名称 (区分特定的调度器实例)
org.quartz.scheduler.instanceName:DefaultQuartzScheduler
// ID设置为自动获取 每一个必须不同 (所有调度器实例中是唯一的)
org.quartz.scheduler.instanceId :AUTO
// 数据保存方式为持久化
org.quartz.jobStore.class :org.quartz.impl.jdbcjobstore.JobStoreTX
// 表的前缀
org.quartz.jobStore.tablePrefix : QRTZ_
// 设置为TRUE不会出现序列化非字符串类到 BLOB 时产生的类版本问题
// org.quartz.jobStore.useProperties : true
// 加入集群 true 为集群 false不是集群
org.quartz.jobStore.isClustered : false
// 调度实例失效的检查时间间隔
org.quartz.jobStore.clusterCheckinInterval:20000
// 容许的最大作业延长时间
org.quartz.jobStore.misfireThreshold :60000
// ThreadPool 实现的类名
org.quartz.threadPool.class:org.quartz.simpl.SimpleThreadPool
// 线程数量
org.quartz.threadPool.threadCount : 10
// 线程优先级
// threadPriority 属性的最大值是常量 java.lang.Thread.MAX_PRIORITY,等于10。最小值为常量 java.lang.Thread.MIN_PRIORITY,为1
org.quartz.threadPool.threadPriority : 5
// 自创建父线程
//org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
// 数据库别名
org.quartz.jobStore.dataSource : qzDS
// 设置数据源
org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver
org.quartz.dataSource.qzDS.URL:jdbc:mysql://localhost:3306/quartz
org.quartz.dataSource.qzDS.user:root
org.quartz.dataSource.qzDS.password:123456
org.quartz.dataSource.qzDS.maxConnection:10
Quartz 调度器
Quartz框架的核心是调度器。调度器负责管理Quartz应用运行时环境。启动时,框架初始化一套worker线程,这套线程被调度器用来执行预定的作业。这就是 Quartz 怎样能并发运行多个作业的原理。Quartz 依赖一套松耦合的线程池管理部件来管理线程环境。
两种作业存储方式
1. RAMJobStore
- 通常的内存来持久化调度程序信息。这种作业存储类型最容易配置、构造和运行。
- 因为这种方式的调度程序信息是被分配到 JVM 内存中,所以,当应用程序停止运行时,所有调度信息将被丢失。如果你需要在重新启动之间持久化调度信息,则将需要第二种类型的作业存储。
2. JDBC作业存储
- 需要JDBC驱动程序和后台数据库来持久化调度程序信息(支持集群)
表关系和解释

表关系
表名称 | 说明
qrtz_blob_triggers | Trigger作为Blob类型存储(用于Quartz用户用JDBC创建他们自己定制的Trigger类型,JobStore 并不知道如何存储实例的时候)
qrtz_calendars | 以Blob类型存储Quartz的Calendar日历信息, quartz可配置一个日历来指定一个时间范围
qrtz_cron_triggers | 存储Cron Trigger,包括Cron表达式和时区信息。
qrtz_fired_triggers | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息
qrtz_job_details | 存储每一个已配置的Job的详细信息
qrtz_locks | 存储程序的非观锁的信息(假如使用了悲观锁)
qrtz_paused_trigger_graps | 存储已暂停的Trigger组的信息
qrtz_scheduler_state | 存储少量的有关 Scheduler的状态信息,和别的 Scheduler 实例(假如是用于一个集群中)
qrtz_simple_triggers | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数
qrtz_triggers | 存储已配置的 Trigger的信息
qrzt_simprop_triggers
利用 SpringBoot + Quartz 搭建的界面化的 Demo
在网上找到一个搭好的 Demo,感谢大神!原文: Spring Boot集成持久化Quartz定时任务管理和界面展示
本工程所用到的技术或工具
Spring Boot
Mybatis
Quartz
PageHelper
VueJS
ElementUI
MySql数据库
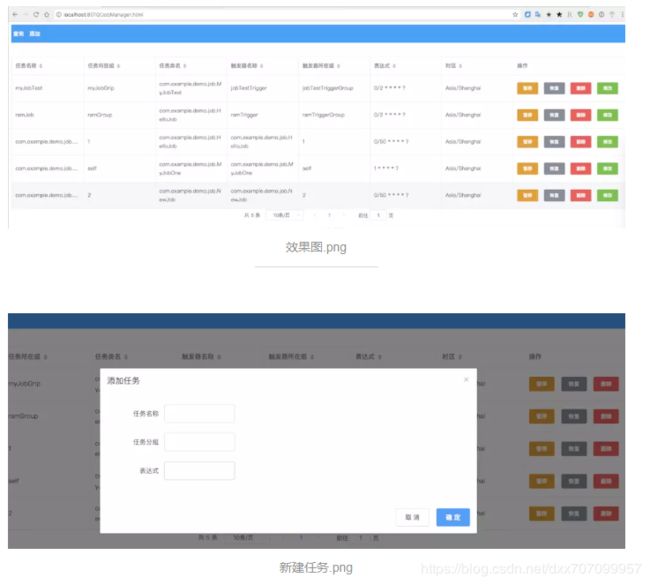
先看图:
源码地址
-
我的github
-
我的码云
-
原项目github
参考资料
-
quartz原理揭秘和源码解读
-
quartz由浅入深
-
Quartz官方文档
-
Spring Boot集成持久化Quartz定时任务管理和界面展示