集合框架
集合框架继承关系图:
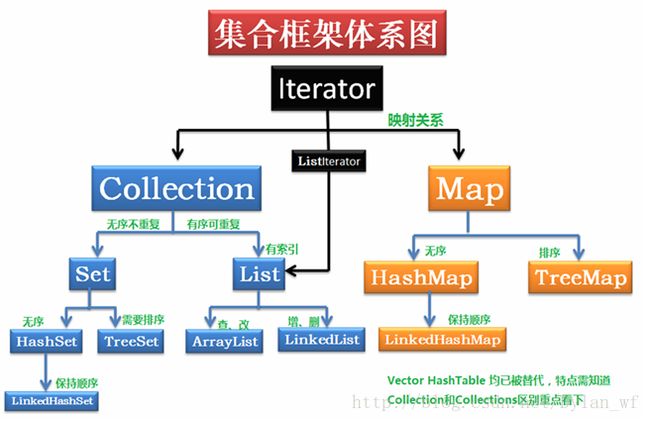
Java集合框架提供了一套性能优良,使用方便的接口和类,位于java.util包内。集合框架包含三大内容,对外的接口,接口的实现类,和对集合运算的算法。
对外的接口:表示集合的抽象数据类型(Collection,List,Set,Map,Iterator)。
**接口的实现类:**ArrayList,LinkedList,HashSet,TreeSet,HashMap,TreeMap
算法:**Java提供了进行集合操作的工具类**Collections
Collection:无序 不唯一
Set(相当于数学中的集合):无序 唯一
List(相当于数学中的数组):有序 不唯一
Map(相当于键值对):Key(键):无序,唯一,Value(值):无序,不唯一。
Iterator:定义访问和遍历元素的接口
List接口:
常用类:ArrayList和LinkedList,都不唯一,有序。
ArrayList:对数组进行封装,实现了长度可变的数组,在内存中分配连续的空间,故而查询效率高,增删慢。查询快,增删慢,线程不安全,效率高
LinkedList:采用链表存储方式,故而在插入删除元素时效率高。查询慢,增删快,线程不安全,效率高(链表形式)
ArrayList常用方法使用案例
package test;
import java.util.List;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
List list=new ArrayList();//声明集合
list.add(dog1);//list.add()返回值类型boolean
list.add(dog3);
list.add(dog4);
//指定位置添加元素,从0开始计算
list.add(2,dog2);
//list.size()返回元素个数
System.out.println("共有"+list.size()+"条狗");
for(int i=0;i<list.size();i++){
//list.get(int index)返回索引指定位置元素,类型Object,需要强转处理
Dog dog=(Dog) list.get(i);
System.out.println(dog.getName()+"\t"+dog.getAge());
}
//删除集合中第一个和dog3元素
list.remove(0);//list.remove(index),返回object类型
list.remove(dog3);//list.remove(object),返回boolean类型
System.out.println("删除后共有"+list.size()+"条狗");
for(int i=0;i<list.size();i++){
//list.get(int index)返回索引指定位置元素,类型Object,需要强转处理
Dog dog=(Dog) list.get(i);
System.out.println(dog.getName()+"\t"+dog.getAge());
}
//判断是否包含指定狗dog3元素
if(list.contains(dog3)){//list.contains(object)返回boolean类型
System.out.println("包含");
}else{
System.out.println("不包含");
}
}LinkedList常用方法使用案例
上一案例中所以方法都可以适用于LinkedList。
除此之外还有些特有的特殊方法,如下:
package test;
import java.util.List;
import java.util.LinkedList;
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
LinkedList list=new LinkedList();//声明集合,注意和ArrayList不同
list.add(dog1);//list.add()返回值类型boolean
list.add(dog4);
list.addFirst(dog2);//list.addFirst()列表首部添加
list.addLast(dog3);//列表尾部添加
list.removeFirst();//移除并返回第一个元素
list.removeLast();//移除并返回最后一个元素
Dog dog=(Dog)list.getLast();//返回最后一个元素
//Dog dog=(Dog)list.removeLast();//注意:因为removeLast也可以返回,故此处有相同效果
System.out.println("姓名"+dog.getName());
}
}Set接口:
Set接口描述的是一种比较简单的集合,集合中的对象并不按特定顺序排列,且不能保存重复的对象,即Set接口可以存储一组唯一,无序的对象
HashSet:唯一无序,线程不安全,允许集合内元素值为null。底层数据结构是哈希表。
HashSet是如何保证元素唯一性的呢?
是通过元素的两个方法,hashCode和equals来完成。
如果元素的HashCode值相同,才会判断equals是否为true。
如果元素的hashcode值不同,不会调用equals。
注意,对于判断元素是否存在,以及删除等操作,依赖的方法是元素的hashcode和equals方法。
常用方法:
boolean add(Object o)//添加元素
void clear()//移除所有元素
int size()//元素数量
boolean is Empty()//判断是否set为空
boolean contains(Object o)//是否包含这个元素
boolean remove(Object o)//如果元素存在,则移除
package test;
import java.util.HashSet;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
Set set=new HashSet();//声明集合
set.add(dog1);//添加
set.add(dog4);
set.add(dog2);
set.add(dog3);
set.remove(dog1);//移除元素
System.out.println("共有"+set.size()+"条狗");
for(Object obj :set){//hashset无get方法,只能用增强for循环来遍历
Dog dog=(Dog)obj;
System.out.println(dog.toString());
}
}
}
另一种遍历:
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
Set set=new HashSet();//声明集合
set.add(dog1);//添加
set.add(dog4);
set.add(dog2);
set.add(dog3);
set.remove(dog1);//移除元素
System.out.println("共有"+set.size()+"条狗");
for(Iterator it=set.iterator();it.hasNext();){//hashset无get方法,只能用增强for循环来遍历
System.out.println(it.next());
}
}
}TreeSet:
有序的存放:TreeSet 线程不安全,可以对Set集合中的元素进行排序
通过compareTo或者compare方法来保证元素的唯一性,元素以二叉树的形式存放。
TreeSet存储对象的时候, 可以排序, 但是需要指定排序的算法
Integer能排序(有默认顺序), String能排序(有默认顺序), 自定义的类存储的时候出现异常(没有顺序)
如果想把自定义类的对象存入TreeSet进行排序, 那么必须实现Comparable接口
在类上implement Comparable
重写compareTo()方法
在方法内定义比较算法, 根据大小关系, 返回正数负数或零
在使用TreeSet存储对象的时候, add()方法内部就会自动调用compareTo()方法进行比较, 根据比较结果使用二叉树形式进行存储
package test;
import java.util.Iterator;
import java.util.Set;
import java.util.TreeSet;
public class Test {
public static void main(String[] args) {
Set ts = new TreeSet();//定义TreeSet
ts.add("abc");//添加数据,int和String类型支持,其他类型需要实现Comparable接口
ts.add("xyz");
ts.add("rst");
Iterator it = ts.iterator();//迭代
while (it.hasNext()) {
System.out.println(it.next());
}
}
}
Map接口:
Map接口存储一组成对的键值对,提供Key到Value的映射,Key无序唯一,Value无序不唯一。
Hash存储方式是哈希表,通过把关键码(key value)映射到表中一个位置来访问记录,以加快查找速度。存放记录的数组成为哈希表,这种存储方式优点是查询指定元素效率高
HashMap使用方法
package test;
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) {
Map map = new HashMap();//定义HashMap
map.put("CN", "中国");//存储键值对
map.put(2, 2);//键值对可以是任意类型
//Object get(Object key)通过键来查找值,注意结果还是Object类型需要强转
int i=(int) map.get(2);
System.out.println(i);
System.out.println("Map有几组数据:"+map.size());//返回元素个数
System.out.println(map.keySet());//返回键的集合
System.out.println(map.values());//返回值的集合
map.remove(2);//删除键对应的键值对
map.containsKey(2);//判断是否存在该键
map.clear();//删除所有映射关系(键值对)
if(map.isEmpty()){//判断map是否还存在映射关系(键值对)
System.out.println("空");
}
}
}迭代器Iterator
迭代器为集合而生,专门实现集合的遍历,提供了遍历集合统一编程接口。
Collection接口的Iterator()方法返回一个Iterator,通过Iterator接口的两个方法即可方便的遍历。
boolean hasNext( )//判断是否存在另一个可访问的元素
object next( )//返回要访问的下一个元素
package test;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
//放入map对象
Map map=new HashMap();
map.put(dog1.getName(), dog1);
map.put(dog2.getName(), dog2);
map.put(dog3.getName(), dog3);
map.put(dog4.getName(), dog4);
//迭代
Set keys=map.keySet();//取出key集合
Iterator it=keys.iterator();//迭代,获取Iterator对象
while(it.hasNext()){//遍历
String key=(String) it.next();//取出key(强转)
Dog dog=(Dog) map.get(key);//根据key获得对应的dog对象
int i=dog.getAge();
System.out.println(key+"\t"+i);
}
}
}核心代码:
Iterator it=a.iterator();//迭代,获取Iterator对象
while(it.hasNext()){//判断是否存在另一个可访问元素,配合while()即遍历作用
String key=(String) it.next();//返回要访问的下一个元素例2:迭代ArrayList
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
//放入map对象
List list=new ArrayList();
list.add(dog1);
list.add(dog2);
list.add(dog3);
list.add(dog4);
//迭代
Iterator it=list.iterator();//迭代,获取Iterator对象
while(it.hasNext()){//遍历
Dog dog=(Dog) it.next();
System.out.println(dog.getName()+"\t"+dog.getAge());
}
}
}
增强型for循环
for语句的简化版本,通常称为foreach语句。
语法:
for(元素类型t 元素变量X :数组或者集合对象){
//引用了X的语句
}其中,t类型必须是属于集合或者对象的元素类型。
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
//放入map对象
List list=new ArrayList();
list.add(dog1);
list.add(dog2);
list.add(dog3);
list.add(dog4);
for(Object obj:list){
Dog dog=(Dog) obj;
System.out.println(dog.getName()+"\t"+dog.getAge());
}
}
}
泛型应用:
上面的代码每次都要强转类型,可以通过泛型在创建集合时就指定集合中元素的类型,从而取出集合中的元素时无需强转。
上面代码用泛型优化修改后:
public class Test {
public static void main(String[] args) {
Dog dog1=new Dog("欧欧1",3);
Dog dog2=new Dog("美美2",2);
Dog dog3=new Dog("菲菲3",4);
Dog dog4=new Dog("亚亚4",5);
//放入map对象
List list=new ArrayList();//引入泛型
list.add(dog1);
list.add(dog2);
list.add(dog3);
list.add(dog4);
for(Dog dog:list){
System.out.println(dog.getName()+"\t"+dog.getAge());
}
}
} 注意:泛型机制是给编译器看的,本身不参与编译,底层机制没有泛型概念。