监督学习应用--Titanic数据建模
监督学习建模流程
监督学习包括数据采集、数据处理、模型搭建及训练、模型测试、参数调优等阶段。这是一个不断反馈不断循环的过程。
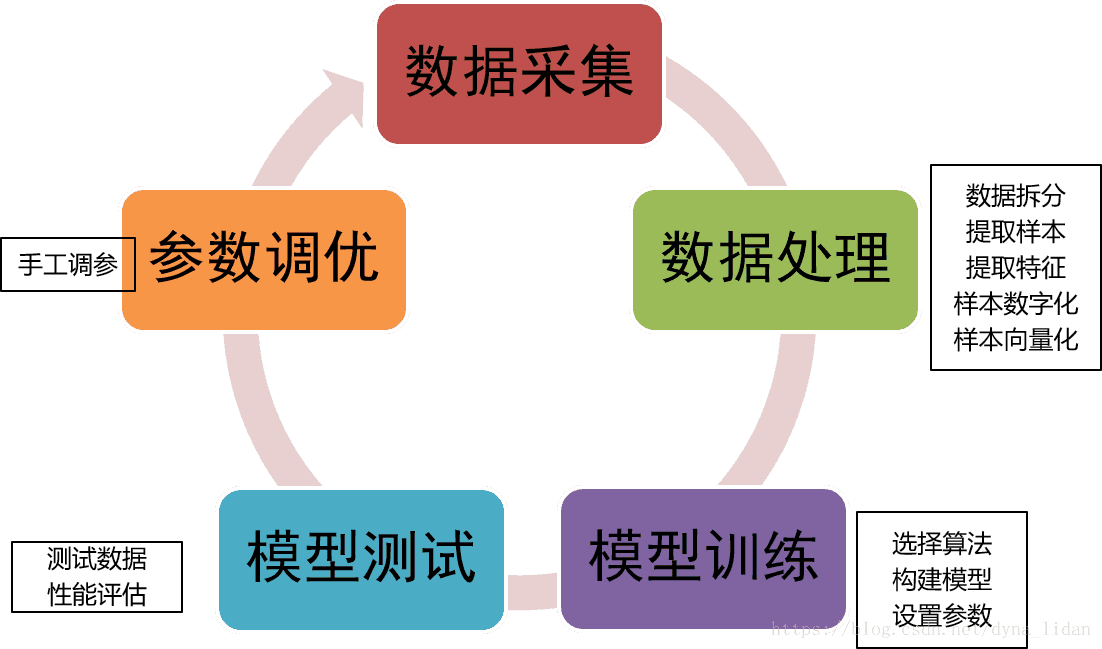
本文我们利用Titanic数据进行建模,分析乘客各种信息与是否获救之间的规律,从来对我们的测试集进行预测。(是否获救就是标签,乘客其他信息就是特征。)
*数据来源*
Titanic数据是机器学习竞赛平台Kaggle平台入门最好的数据,记录了沉船的泰坦尼克各种乘客信息以及最终是否获救的情况。导入数据:
`df=pd.read_csv('../p1_demo/titanic_dataset.csv',na_values='NULL')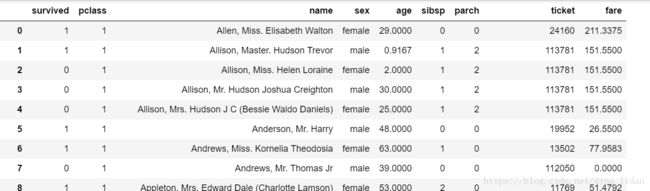
*可视化分析*
在数据处理之前可通过对数据进行可视化分析,对数据有个很好的了解和把握。
##可视化获救与没被获救的比例
df['survived'].hist()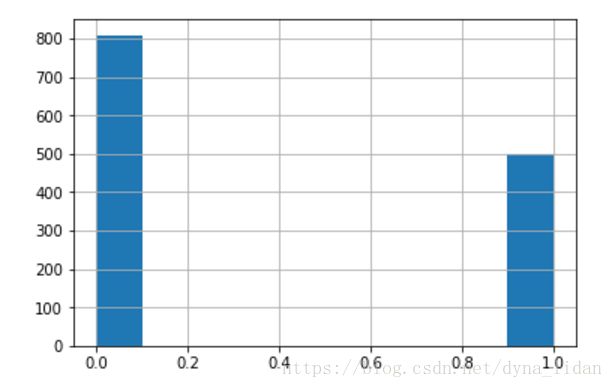
###不同船舱级别的获救情况
pd.crosstab(df['pclass'],df['survived']).plot(kind='bar')
pd.crosstab(df['pclass'],df['survived'])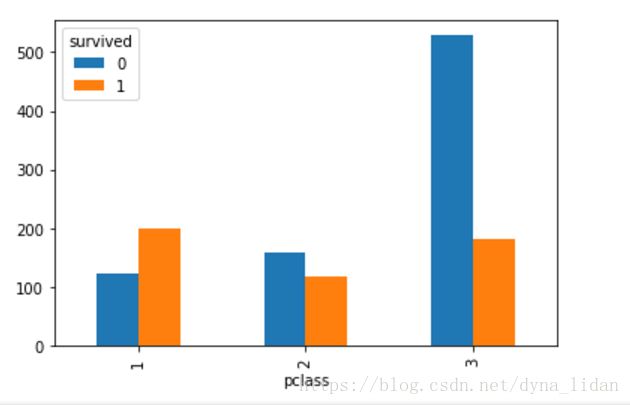
*数据处理*
包括异常值处理、缺失值填充、噪音数据过滤、数据形式转换、特征提取等操作。
以上Titanic数据算法不能直接识别,并且像年龄费用为连续型数据,我们需要处理成和其他特征一致的离散性特征。所以我们进行如下处理:

详细处理代码如下:
##姓名的处理
df['Name_length']=df['name'].apply(len)
##兄弟姐妹与配偶、父母小孩
df['FamilySize']=df['sibsp']+df['parch']+1
df['IsAlone']=0
df.loc[df['FamilySize']==1,'IsAlone']=1
##费用的处理
df['fare']=df['fare'].fillna(df['fare'].median())
df['categoricalFare']=pd.cut(df['fare'],4)
#print(train)
##年龄
age_avg=df['age'].mean()
age_std=df['age'].std()
age_null_count=df['age'].isnull().sum()
age_null_random_list=np.random.randint(age_avg-age_std,age_avg+age_std,size=age_null_count)
df['age'][np.isnan(df['age'])]=age_null_random_list
df['age'] = df['age'].astype(int)
df['categoricalage'] = pd.cut(df['age'], 5)
##对姓名的处理
def get_title(name):
title_search = re.search('([A-Za-z]+)\.', name) ##匹配出头衔(Miss,Master 等等)
# If the title exists, extract and return it.
if title_search:
return title_search.group(1)
return ""
df['Title'] = df['name'].apply(get_title)
df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')
df['Title'] = df['Title'].replace('Mlle', 'Miss')
df['Title'] = df['Title'].replace('Ms', 'Miss')
df['Title'] = df['Title'].replace('Mme', 'Mrs')
# 将头衔映射到0,1,2,3,4,5
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
df['Title'] = df['Title'].map(title_mapping)
df['Title'] = df['Title'].fillna(0)
# Mapping Sex
df['sex'] = df['sex'].map({'female': 0, 'male': 1} ).astype(int)
# Mapping Fare
df.loc[ df['fare'] <= 7.91, 'fare'] = 0
df.loc[(df['fare'] > 7.91) & (df['fare'] <= 14.454), 'fare'] = 1
df.loc[(df['fare'] > 14.454) & (df['fare'] <= 31), 'fare'] = 2
df.loc[ df['fare'] > 31, 'fare'] = 3
df['fare'] = df['fare'].astype(int)
# Mapping Age
df.loc[ df['age'] <= 16, 'age'] = 0
df.loc[(df['age'] > 16) & (df['age'] <= 32), 'age'] = 1
df.loc[(df['age'] > 32) & (df['age'] <= 48), 'age'] = 2
df.loc[(df['age'] > 48) & (df['age'] <= 64), 'age'] = 3
df.loc[ df['age'] > 64, 'age'] = 4 ;*数据拆分*
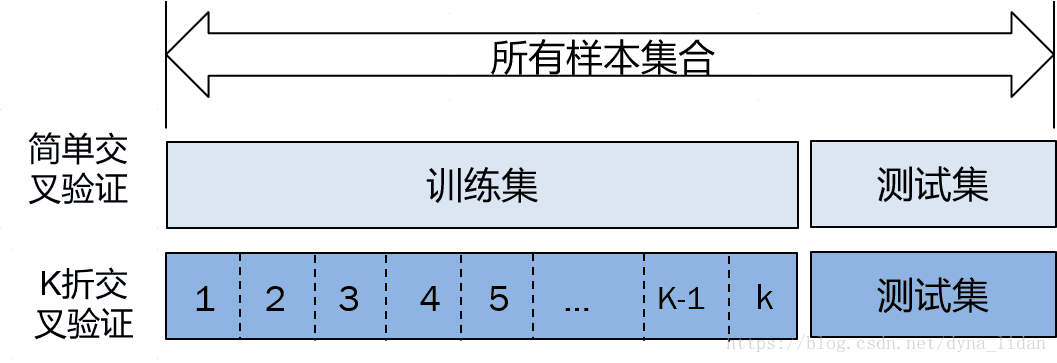
简单拆分:将数据拆分为训练数据和测试数据。训练数据用来给算法进行训练学习,测试数据用来对训练好的模型进行测试。
k折交叉验证拆分:在简单拆分的基础上,对训练数据继续拆分成k份,每次拿出一份,剩下的k-1份拿来给算法进行训练,得到k个模型,通过对k个模型同时对测试集进行测试,并得到最终的预测结果。
拆分代码:
##将数据转换成算法识别的数据,array的形式。
x=df[["pclass","sex","age","fare","Name_length","FamilySize","IsAlone","Title"]].values
y=df["survived"].values
PassengerId=list(df.index)
print(x.shape)
from sklearn.cross_validation import KFold
###训练集:测试集合=1200:109
train_x=x[:1200]
train_y=y[:1200]
###print(train_x.shape)
test_x=x[1200:]
test_y=y[1200:]
test_PassengerId=PassengerId[1200:]
###获取训练数据量大小,测试数据量大小
ntrain=train_x.shape[0]
ntest=test_x.shape[0]
###交叉验证数据的分类,5折交叉验证
NFOLDS = 5
SEED=0
kf = KFold(ntrain, n_folds= NFOLDS, random_state=SEED)
##print(train_x) *算法选择与模型训练*
sklearn包含了各种常用的机器学习算法。直接通过一个函数就可以调用。比如选择逻辑回归:
from sklearn.linear_model import LogisticRegression
clf=LogisticRegression()交叉验证训练过程:
###交叉验证
def get_oof(clf, train_x, train_y, test_x):
"""初始化
oof_train: 训练数据结果
oof_test: 测试数据结果
oof_test_skf: 储存5次交叉训练模型对测试数据的预测结果"""
oof_train = np.zeros((ntrain,))
oof_test = np.zeros((ntest,))
oof_test_skf = np.empty((NFOLDS, ntest)) ##生成一个NFOLDS*ntest的空数组。
##根据每次切分数据进行训练并对测试数据进行预测
for i, (train_index, test_index) in enumerate(kf):
x_tr = train_x[train_index]
y_tr = train_y[train_index]
x_te = train_x[test_index]
clf.fit(x_tr, y_tr)
oof_train[test_index] = clf.predict(x_te)
oof_test_skf[i, :] = clf.predict(test_x)
##按第0维求平均,得到5次预测的平均。
oof_test[:] = oof_test_skf.mean(axis=0)
###返回验证集合、测试集合的预测结果。
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)*用模型对测试集进行预测*
oof_train, oof_test = get_oof(clf,train_x, train_y, test_x)
def process_pre(pre_y):
for i in range(pre_y.shape[0]):
if pre_y[i][0]>0.5:
pre_y[i][0]=1
else:
pre_y[i][0]=0
pre_y=pre_y.ravel()
return pre_y
##模型在测试集合的预测结果
pre_y=process_pre(oof_test)*模型性能分析*
1、通过直观地展示预测结果与实际的对比
plt.figure(figsize=(15,5))
plt.scatter(test_PassengerId,pre_y,color='green')
plt.scatter(test_PassengerId,test_y,color='blue')
plt.title('Predicted value VS True value')2、用度量指标对模型进行性能分析
1. 准确率:所有样本中预测正确的占比
针对我们感兴趣的类别:
2. 精度(查准率):预测结果中预测正确的能力。
3. 召回率(查全率):从实际类别中找到某一类别的能力。
4. F1-score=:平衡精度与召回率的度量指标。
from sklearn.metrics import classification_report,confusion_matrix
n_classes=2
##准确率
accuracy=np.mean(pre_y==test_y)
print('accuracy:'+str(accuracy))
##混淆矩阵
cmx=confusion_matrix(test_y,pre_y)
print(cmx)
##精度和召回率
performance=classification_report(test_y,pre_y,labels=range(n_classes))
print('Performance :'+'\n'+str(performance))
最后说明:在数据量这么少的情况下,准确率能达到80%以上已经非常好了。虽然Kaggle平台上很多很好的能到100%。那是因为用了很多特殊的技巧,这种技巧需要根据具体数据、业务、环境下才能使用,我们本文的目的是让大家对整个建模流程有个了解和把握。