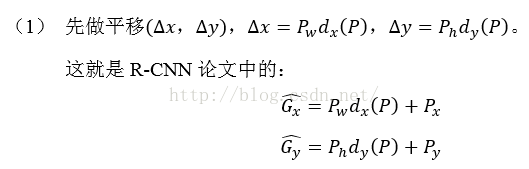CAFFE玩了也有段时间了,现在开始准备研究一下物体检测,现在知道的有RCNN、spp-net、Fast-RCNN和Faster-RCNN,作为菜鸟我还是从头学习,决定先看RCNN,因为有项目要做还要上课,可能得用一段时间才能看完,慢慢写,开始以翻译为主,以后有自己的想法了再慢慢更新,如果有理解错误的地方还希望各位博客园的大神指教--这也是我第一次用博客园,纪念一下,顺便熟悉一下怎么用
论文全称《Rich feature hierarchies for accurate object detection and semantic segmentation》
链接:http://www.cs.berkeley.edu/~rbg/papers/r-cnn-cvpr.pdf
源码的地址:http://www.cs.berkeley.edu/˜rbg/rcnn
摘要:这个方法结合了两个关键的见解,1:使用一个高容量的卷积神经网络将region proposals自底而上的传播,用来定位和分割目标,2:如果有标签的训练数据比较少,可以使用训练好的参数作为辅助,进行fine-tuning,能够得到非常好的识别效果提升。因为该方法是将region proposals和CNN相结合的,所以叫做RCNN。
引文:
不同于图像分类,检测需要在图片中定位物体。一个方法是将帧定位视作一个回归问题(Szegedy的工作表明这个方法不太好);另一个可替代的方法是使用滑动窗口探测器,通过这种方法使用CNNs至少已经有20年的时间了,通常用于一些特定的种类如人脸,行人等,为了保证较高的空间分辨率,这些CNNs通常只有两个卷积层和池化层。作者也考虑过使用一个滑动窗口的方法,然而由于更深的网络,更大的输入图片和滑动步长,使得使用滑动窗口来定位的方法充满了挑战。
作者通过在recongnition using regions操作的方法来解决CNN的定位问题,这个方法在目标检测和语义分割中都取得了成功。测试阶段,这个方法对每一个输入的图片产生近2000个不分种类的“region proposals,使用CNNs从每个region proposals”中提取一个固定长度的特征向量,然后对每个region proposal提取的特征向量使用特定种类的线性SVM进行分类。作者使用了仿射图像变形的方法来对每个不同形状的region proposals产生一个固定长度的CNN输出的特征向量。具体的流程图如下: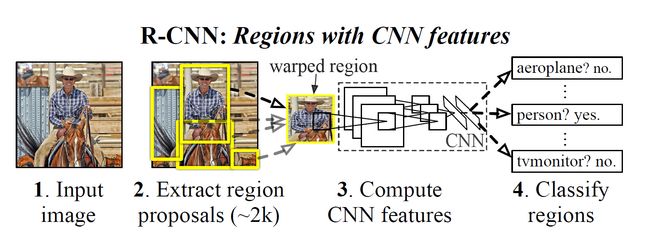
在检测中面临的第二个挑战时目前可用的有标签的数据是远远不够来训练一个大的CNN网络的。对于这个问题,比较方便的解决办法是先使用无监督的方式进行预训练,再使用试用有标签的数据进行fine-tuning。这篇文章贡献的第二个原则是表明在一个大的数据集上(ILSVRC)进行有监督的预训练,然后再在一个小的数据集(PASCAL)上进行特定场合的 fine-tunring是在数据比较小的时候训练high-capacity CNNs的有效方法。在作者的实验中,使用fine-tuning可以将准确率提高8个百分点。在提取完特征后使用SVM分类器对每个regin属于某一类的可能性进行打分,
2. 使用RCNN进行目标检测
整个系统分为三个部分:1.产生不依赖与特定类别的region proposals,这些region proposals定义了一个整个检测器可以获得的候选目标2.一个大的卷积神经网络,对每个region产生一个固定长度的特征向量3.一系列特定类别的线性SVM分类器。
测试阶段,使用selective search的方法在测试图片上提取2000个region propasals ,将每个region proposals归一化到227x227,然后再CNN中正向传播,将最后一层得到的特征提取出来。然后对于每一个类别,使用为这一类训练的SVM分类器对提取的特征向量进行打分,得到测试图片中对于所有region proposals的对于这一类的分数,再使用贪心的非极大值抑制去除相交的多余的框。非极大值抑制(NMS)先计算出每一个bounding box的面积,然后根据score进行排序,把score最大的bounding box作为选定的框,计算其余bounding box与当前最大score与box的IoU,去除IoU大于设定的阈值的bounding box。然后重复上面的过程,直至候选bounding box为空,然后再将score小于一定阈值的选定框删除得到一类的结果。作者提到花费在region propasals和提取特征的时间是13s/张-GPU和53s/张-CPU,可以看出时间还是很长的,不能够达到及时性。
为了进一步提高定位的准确度,作者在对各个region proposal打分后,利用回归的方法重新预测了一个新的矩形框。如上图所示,通过selective search得到的region proposal可能与ground truth相差较大,尽管这个region proposal可能有很高的分类评分,但对于检测来说,它依然是不合格的
注意:只有当Proposal和Ground Truth比较接近时(线性问题),我们才能将其作为训练样本训练我们的线性回归模型,否则会导致训练的回归模型不work(当Proposal跟GT离得较远,就是复杂的非线性问题了,此时用线性回归建模显然不合理)。这个也是G-CNN: an Iterative Grid Based Object Detector多次迭代实现目标准确定位的关键。
那个预测模型的输入为一张图片上不同region proposal的pool5feature,t为这个region proposal的位置参数,因此训练出通过卷积特征预测图像位置的模型,在预测阶段,通过输入得分最高的region proposal的卷积特征即可得到图片的位置变换。
引用: