Weakly- and Semi-Supervised Learning of a Deep Convolutional Network for Semantic Image Segmentation

abstract
Deep convolutional neural networks (DCNNs) trained on a large number of images with strong pixel-level annotations have recently significantly pushed the state-of-art in semantic image segmentation. We study the more challenging problem of learning DCNNs for semantic image segmentation from either
- weakly annotated training data such as bounding boxes or image-level labels or
- a combination of few strongly labeled and many weakly labeled images, sourced from one or multiple datasets.
We develop Expectation-Maximization (EM) methods for semantic image segmentation model training under these weakly supervised and semi-supervised settings. Extensive experimental evaluation shows that the proposed techniques can learn models delivering competitive results on the challenging PASCAL VOC 2012 image segmentation benchmark, while requiring significantly less annotation effort. We share source code implementing the proposed system at https://bitbucket.org/deeplab/deeplab-public.
Proposed Methods
像素级别的标注(全监督)
目标函数是:
J ( θ ) = log P ( y ∣ x ; θ ) = ∑ m = 1 M log P ( y m ∣ x ; θ ) J(\boldsymbol{\theta})=\log P(\boldsymbol{y} | \boldsymbol{x} ; \boldsymbol{\theta})=\sum_{m=1}^{M} \log P\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}\right) J(θ)=logP(y∣x;θ)=m=1∑MlogP(ym∣x;θ)
式中, θ \theta θ是DNN的参数,每个像素的标签分布可以按照下式计算:
P ( y m ∣ x ; θ ) ∝ exp ( f m ( y m ∣ x ; θ ) ) P\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}\right) \propto \exp \left(f_{m}\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}\right)\right) P(ym∣x;θ)∝exp(fm(ym∣x;θ))
式中, f m ( y m ∣ x ; θ ) f_{m}\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}\right) fm(ym∣x;θ)是DCNN在第 m m m个像素的输出,使SGD即可优化 J ( θ ) J(\boldsymbol{\theta}) J(θ)
图象级别的标注
当只有图像级注释可用时,我们可以观察到图像像素值 x \boldsymbol{x} x和图像级标签 z \boldsymbol{z} z,但像素级分割结果 y \boldsymbol{y} y是潜在变量。建立如下概率图模型:
P ( x , y , z ; θ ) = P ( x ) P ( y ∣ x ; θ ) P ( z ∣ y ) = P ( x ) ( ∏ m = 1 M P ( y m ∣ x ; θ ) ) P ( z ∣ y ) P(\boldsymbol{x}, \boldsymbol{y}, \boldsymbol{z} ; \boldsymbol{\theta})=P(x)P(y|x;\theta)P(z|y)=P(\boldsymbol{x})\left(\prod_{m=1}^{M} P\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}\right)\right) P(\boldsymbol{z} | \boldsymbol{y}) P(x,y,z;θ)=P(x)P(y∣x;θ)P(z∣y)=P(x)(m=1∏MP(ym∣x;θ))P(z∣y)
为了从训练数据中学习模型参数 θ \theta θ,我们采用EM方法.如果忽略不依赖 θ \theta θ的项,若给定上次的估计 θ ′ \theta' θ′,则完全数据的期望对数似然函数(Q函数):
Q ( θ ; θ ′ ) = ∑ y P ( y ∣ x , z ; θ ′ ) log P ( y ∣ x ; θ ) ≈ log P ( y ^ ∣ x ; θ ) Q\left(\boldsymbol{\theta} ; \boldsymbol{\theta}^{\prime}\right)=\sum_{\boldsymbol{y}} P\left(\boldsymbol{y} | \boldsymbol{x}, \boldsymbol{z} ; \boldsymbol{\theta}^{\prime}\right) \log P(\boldsymbol{y} | \boldsymbol{x} ; \boldsymbol{\theta}) \approx \log P(\hat{\boldsymbol{y}} | \boldsymbol{x} ; \boldsymbol{\theta}) Q(θ;θ′)=y∑P(y∣x,z;θ′)logP(y∣x;θ)≈logP(y^∣x;θ)
式中, x \boldsymbol{x} x和 z \boldsymbol{z} z是直接观测到的, y \boldsymbol{y} y是未观测数据。
之后,采用hard-EM approximation来评估E步算法中的潜在分割:
y ^ = argmax y P ( y ∣ x ; θ ′ ) P ( z ∣ y ) = argmax y log P ( y ∣ x ; θ ′ ) + log P ( z ∣ y ) = argmax y ( ∑ m = 1 M f m ( y m ∣ x ; θ ′ ) + log P ( z ∣ y ) ) \begin{aligned} \hat{\boldsymbol{y}} &=\underset{\boldsymbol{y}}{\operatorname{argmax}} P\left(\boldsymbol{y} | \boldsymbol{x} ; \boldsymbol{\theta}^{\prime}\right) P(\boldsymbol{z} | \boldsymbol{y}) \\ &=\underset{\boldsymbol{y}}{\operatorname{argmax}} \log P\left(\boldsymbol{y} | \boldsymbol{x} ; \boldsymbol{\theta}^{\prime}\right)+\log P(\boldsymbol{z} | \boldsymbol{y}) \\ &=\underset{\boldsymbol{y}}{\operatorname{argmax}}\left(\sum_{m=1}^{M} f_{m}\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}^{\prime}\right)+\log P(\boldsymbol{z} | \boldsymbol{y})\right) \end{aligned} y^=yargmaxP(y∣x;θ′)P(z∣y)=yargmaxlogP(y∣x;θ′)+logP(z∣y)=yargmax(m=1∑Mfm(ym∣x;θ′)+logP(z∣y))
在算法的M步,使用SGD优化 Q ( θ ; θ ′ ) ≈ log P ( y ^ ∣ x ; θ ) Q\left(\boldsymbol{\theta} ; \boldsymbol{\theta}^{\prime}\right) \approx \log P(\hat{\boldsymbol{y}} | \boldsymbol{x} ; \boldsymbol{\theta}) Q(θ;θ′)≈logP(y^∣x;θ)以得到下次迭代的 θ \theta θ值。
为了完全识别E步,也就是为了计算得到E步的潜在分割结果 y ^ \hat{\boldsymbol{y}} y^,需要指定观察模型 P ( z ∣ y ) P(z|y) P(z∣y)我们试验了两种变体:EM-Fixed和EM-Adapt
EM-Fixed
将上式中的 l o g P ( z ∣ y ) logP(z|y) logP(z∣y)写成逐个像素的形式:
log P ( z ∣ y ) = ∑ m = 1 M ϕ ( y m , z ) + ( c o n s t ) \log P(\boldsymbol{z} | \boldsymbol{y})=\sum_{m=1}^{M} \phi\left(y_{m}, \boldsymbol{z}\right)+(\mathrm{const}) logP(z∣y)=m=1∑Mϕ(ym,z)+(const)
因此每个像素的估计值 y ^ m \hat{y}_m y^m可以表示为:
y ^ m = argmax y m f ^ m ( y m ) ≐ f m ( y m ∣ x ; θ ′ ) + ϕ ( y m , z ) \hat{y}_{m}=\underset{y_{m}}{\operatorname{argmax}} \hat{f}_{m}\left(y_{m}\right) \doteq f_{m}\left(y_{m} | \boldsymbol{x} ; \boldsymbol{\theta}^{\prime}\right)+\phi\left(y_{m}, \boldsymbol{z}\right) y^m=ymargmaxf^m(ym)≐fm(ym∣x;θ′)+ϕ(ym,z)
我们假设:
ϕ ( y m = l , z ) = { b l if z l = 1 0 if z l = 0 \phi\left(y_{m}=l, z\right)=\left\{\begin{array}{ll}{b_{l}} & {\text { if } z_{l}=1} \\ {0} & {\text { if } z_{l}=0}\end{array}\right. ϕ(ym=l,z)={bl0 if zl=1 if zl=0
其中 b l b_l bl是类依赖的偏置
我们设置参数 b l = b f g b_l=b_{fg} bl=bfg,如果l>0,b0=bbg,则 b f g > b b g > 0 b_{fg}>b_{bg}>0 bfg>bbg>0。直观地说,这种潜力鼓励将一个像素分配给图像级标签 z z z中的一个.我们选择 b f g > b b g b_{fg}>b_{bg} bfg>bbg,对当前的前景类进行比背景更多的提升,以鼓励充分的目标覆盖,避免将所有像素分配给背景的退化解决方案。该过程在算法1中总结,如图2所示。

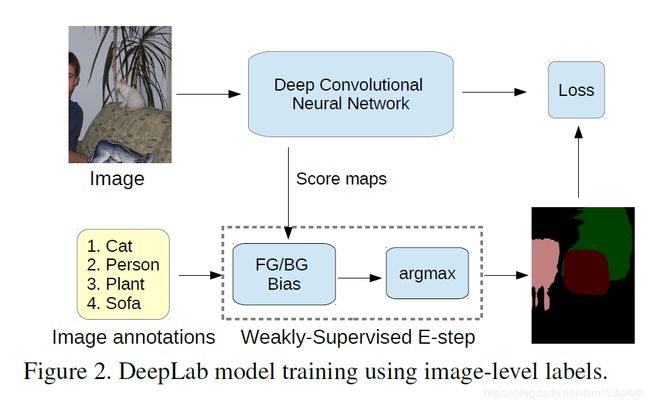
EM-Adapt
在这种方法中,我们假定 l o g P ( Z ∣ y ) = ϕ ( y , z ) + ( C o n s t ) log P(Z|y)=\phi(y,z)+(Const) logP(Z∣y)=ϕ(y,z)+(Const),其中(y;z)为基数势[23,33,36]。特别是,我们鼓励至少将图像区域的l部分分配给类l,如果zl=1,并且强制不将像素分配给类l,如果zl=0。设参数l=FG,如果l>0,0=BG。类似的限制出现在[10,20]中。
在实际应用中,我们采用了算法1的一个变体。我们自适应地设置与图像和类相关的偏差bl,以便将图像区域的指定比例分配给背景或前景对象类。这是一个强大的约束,显着地阻止了背景分数在整个图像中的流行,也促进了更高的前景目标覆盖率。详细的算法在补充材料中进行了描述。
bounding box标注
我们探索了三种不同的方法用bounding box来训练我们的分割模型。
第一个Bbox-rect方法相当于简单地将边界框中的每个像素作为各自对象类的正示例。通过将属于多个边界框的像素分配给具有最小区域的像素来解决模糊问题。包围框完全包围对象,但也包含背景像素,这些像素会用针对各个对象类的假阳性示例来污染培训集。
为了滤除这些背景像素,我们还探索了第二种Bbox-Seg方法,在这种方法中,我们执行自动前景/背景分割。为了执行此分段,我们使用与DeepLab中相同的CRF。更具体地说,我们将边框的中心区域(框内像素的百分比)限制为前景,而将边框外的像素限制为背景。我们通过适当设置CRF的一元项来实现这一点,然后推断出像素之间的标签。我们交叉验证CRF参数,以最大限度地提高分割精度在一组小的完全标注的图像。这种方法类似于[34]的抓取法。用这两种方法估计分段的例子如图4所示。
