自定义RecordReader
自定义RecordReader
Hadoop默认的InputFormat为TextInputFormat,对应的数据解析器默认为LineRecordReader。
我们可以根据需要自定义InputFormat和RecordReader来个性化对输入的处理。
下面这个例子是我学习过程中参考视频教程做的一个练习,查了很多资料,大概弄懂,满心欢喜,兴致勃勃,欲记之,研墨毕,惊觉早有此例之详述,吾至而立之年以来,渐得一习:凡所经苦思冥想之事,必记之,以为缅。遂得此文,不究雷同与否。
实验环境:
操作系统: Ubuntu 16.04 LTS
Hadoop版本: Apache Hadoop2.6.5
JDK版本: JDK1.7
集群配置: 伪分布式模式
问题描述
需求:对如下文件,分别统计奇数行和偶数行总和
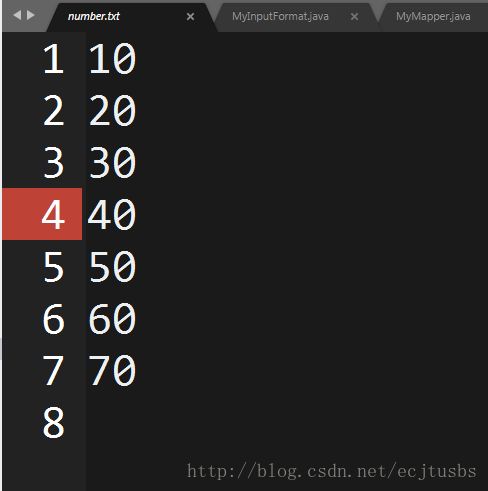
问题分析
问题的难点在于:
我们如何区分读入的数据是奇数行还是偶数行
Hadoop默认的InputFormat处理类为TextInputFormat,将数据分片对应的数据读入,划分为 InputFormat子类来实现对原始数据进行自定义的处理规则。
这里采用的方法是,通过自定义的InputFormat,读取记录时记录当前行号line_number,将number.txt中的数据转化成line_number 确定奇偶行,对map的输出进行partitioner操作,对应到处理奇数行之和与偶数行之和的reducer中。
注:在这个例子中,不对数据文件进行分片
编码
MyInputFormat.java
自定义的InputFormat,用自定义的RecordReader对象读入分片对应的数据 , 不允许文件分片
package mr;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
//这里从文件读取分片,继承FileInputFormat类
public class MyInputFormat extends FileInputFormat<LongWritable, Text> {
// 自定义的RecordReader,负责解析分片对应的数据
private MyRecordReader myRecordReader=null;
//RecordReader负责处理分片对应的数据
@Override
public RecordReader createRecordReader(InputSplit inputSplit, TaskAttemptContext context)
throws IOException, InterruptedException {
myRecordReader=nwe MyRecordReader(inputSplit,context);
//初始化自定义的RecordReader对象
myRecordReader.initialize();
return myRecordReader;
}
//是否可分割文件,在这个例子中,不需要对输入进行分片,直接返回false
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
}
MyRecordReader.java
自定义的RecordReader,借助LineReader读入分片数据,转化为
package mr;
import java.io.IOException;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
public class MyRecordReader extends RecordReader<LongWritable, Text> {
//实际负责数据读入的RecordReader,注意这里的包路径为:org.apache.hadoop.util.LineReader;
LineReader lineReader = null;
// 分片数据在原始文件的起始位置
private long start;
// 分片数据在原始文件的结束位置
private long end;
// 记录行号,据此区分奇数偶数行
private long line_number;
// 解析出的key和value
private LongWritable key = null;
private Text value = null;
// 文件输入流,从hdfs中读取文件
FSDataInputStream fin = null;
@Override
public void close() throws IOException {
// 关闭输入流
fin.close();
}
@Override
public LongWritable getCurrentKey() throws IOException, InterruptedException {
return key;
}
@Override
public Text getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
// 重要,完成初始化
@Override
public void initialize(InputSplit inputSplit, TaskAttemptContext context) throws IOException, InterruptedException {
// 获取文件分片
FileSplit fileSplit = (FileSplit) inputSplit;
// 得到分片数据在原始文件中的起终点位置
start = fileSplit.getStart();
end = start + fileSplit.getLength();
// 分片对应的数据文件的路径
Path filePath = fileSplit.getPath();
// 获取相对应的文件系统对象
FileSystem fileSystem = filePath.getFileSystem(context.getConfiguration());
// 打开文件
fin = fileSystem.open(filePath);
// 调整读入的开始位置
fin.seek(start);
// lineReader负责从输入流读取数据
lineReader = new LineReader(fin);
// 设置起始行号
line_number = 1;
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
// 第一次开始读时,先初始化key和value
if (key == null) {
key = new LongWritable();
}
if (value == null) {
value = new Text();
}
// 设置行号
key.set(line_number);
// 从文件中读取一行数据作为value,如果0==lineReader.readLine(value),说明到达文件尾部,范围false
if (0 == lineReader.readLine(value))
return false;
// 调整行号
line_number++;
// 未到文件尾
return true;
}
}
MyPartitioner.java
根据line_number划分分区
package mr;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class MyPartitioner extends Partitioner<LongWritable, Text> {
@Override
public int getPartition(LongWritable key, Text value, int numPartitions) {
/*
这里的处理逻辑为:
如果为偶数行,则调整其key值为0,设置其分区编号为0
如果为奇数行,则调整其key值为1,设置其分区编号为1
对性质相同的列,调整其key值相同,以便进行combine等操作
*/
if (key.get() % 2 == 0) {
//调整key值
key.set(0);
return 0;
}
key.set(1);
return 1;
}
}
MyMapper.java
这里对读入的元组,不做处理,直接输出
当然也可以通过在这里判断奇偶行来改变代表奇偶标志的key值
package mr;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<LongWritable, Text, LongWritable, Text> {
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
context.write(key,value);
}
}
MyReducer.java
统计和,key为0代表偶数
package mr;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<LongWritable, Text, Text, LongWritable> {
@Override
protected void reduce(LongWritable key, Iterable value,
Context content) throws IOException, InterruptedException {
long sum=0;
Text tag=null;
for (Text val:value){
sum+=Long.parseLong(val.toString());
}
if(key.toString().equals("0")){
tag=new Text("even: total:");
}else if(key.toString().equals("1")){
tag=new Text("odd: total:");
}
content.write(tag, new LongWritable(sum));
}
}
Driver.java
主类,设置作业相关参数
package mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Driver {
public static void main(String[] args) throws Exception {
Configuration configuration=new Configuration();
Job job=Job.getInstance(configuration, "sum");
//设定输入类,负责读入分片对应的数据,解析成key-value形式
job.setInputFormatClass(MyInputFormat.class);
//指定作业jar包
job.setJarByClass(Driver.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
//reducer个数为2,分别统计奇数行和偶数行之和
job.setNumReduceTasks(2);
//自定义划分分区类
job.setPartitionerClass(MyPartitioner.class);
//输入输出路径
FileInputFormat.setInputPaths(job, new Path("/input/"));
FileOutputFormat.setOutputPath(job, new Path("/output"));
if(!job.waitForCompletion(true))
return;
}
}
实验结果

可以看到,计算结果正确。
总结
这个例子主要是练习自定义RecordReader对数据进行自定义输入处理,以此达到我们的某些特殊要求,涉及到Hadoop的输入处理系统,例子中很多具体的细节可以参看源码进行对照。还是那句话:多看源码。
参考资料
这里列出我参考过的与InputFormat相关的一些资料,当然,最好的资料还是源码:
Hadoop二次开发必懂(下)-数据库-火龙果软件工程
Hadoop_FileInputFormat分片 - 神话小小哥 - 博客园
简单之美 | Hadoop MapReduce处理海量小文件:自定义InputFormat和RecordReader
Hadoop权威指南: InputFormat,RecordReader,OutputFormat和RecordWriter - bovenson - 博客园