linux系统之arm架构的CPU与Cache
【摘要】
【写作原因】
【问题构造】
【分析一】总体流程
【分析二】get_free_pages与mmap
【分析三】CPU与TLB
【分析四】cpu与L1cache
【分析五】cpu与L2cache
【总结】
注意:请使用谷歌浏览器阅读(IE浏览器排版混乱)
【摘要】
无论是arm还是powerpc、mips、x86等,提高memory的访问速度都是cpu提高自身性能的重要手段,cache由此而来;无论是Linux还是windows操作系统,充分利用cpu特性,提高系统性能都是不错选择,就像进程上下文切换中页表的切换是linux对MMU的完美利用。性能是软件永恒的主题,了解MMU对软件开发者来说,显得至关重要。那么memory与cache是如何工作的?什么是cpu的一级缓存、二级缓存?全相连cache,组相连cache有什么优缺点,如何加以利用?本文将以一个常见的cache问题,剖析一下linux系统对arm架构MMU机制的支持。
【问题构造】
首先,我们构造一个常见的cache问题:
第一步:内核态申请一段内存:
virt_svc=__get_free_pages(GFP_KERNEL | GFP_DMA,order);
说明:
1)也可以使用kmalloc/alloc_pages等接口申请;
2)此时申请到的virt_svc是内核态的线性地址。
第二步: 内核态将第一步中申请到的virt_svc转换为物理地址:phy_addr=virt_to_phys(virt_svc);
第三步:用户态进程通过mmap,将第二步申请到的物理地址,映射到进程用户态地址空间中。
fd= open("/dev/mem", O_RDWR|O_DSYNC,0);
virt_user = mmap(NULL,len,PROT_READ|PROT_WRITE,MAP_SHARED,fd,phy_addr);
mmap将第二步申请到的物理内存phy_addr映射到了用户态进程地址空间virt_user,映射区间长度为len
注意:
1) virt_user地址是uncached.
原因: open("/dev/mem", O_RDWR|O_DSYNC,0)时,指定了O_DSYNC标记,进而字符驱动mem在为virt_user创建页表时会将页表项的C位置0.此处可以参考内核代码:drivers/char/mem.c,在此不再赘述。
第四步:将第一步申请到的virt_svc赋值0x12121212;再将第三步的user_virt赋值为
0x34343434;跟踪user_virt这段内存,很可能被修改。
以上构造了一个非常典型的cache问题,问题原因也简单,在此不过是想通过该问题引出本文的主题,接下来我们同样以分析问题的形式逐步介绍下arm架构中的CPU与缓存。
【分析一】总体流程
要想知道内存上的数据是如何改变的,首先要知道cpu是如何访问内存上数据的。本文讨论armv6架构,下图很好诠释了cpu访问memory的过程,所做的实验也都是基于该图:

说明:
1.cpu发出virtual address请求时,首先进行的是addresstranslation这一步实际上就是我们常说的TLB(translation lookaside buffer)。TLB其实也是一块缓存,但它不同于l1、l2cache,它是MMU用于缓存页表项的一块区域。此处默认读者对分页机制有所了解,在此不做赘述。关于分页机制可以参考博文:linux内核是如何实现分页机制的 。
其实,如果不了解这一过程也不妨碍本文的理解。可以简单认为,cpu通过这一过程获取了页表项,知道了VA对应的物理内存基地址和C/B位,后文也会有介绍。C/B bit很重要直接关系到了l1、l2cache的访问方式。
2.cpu是否访问l1、l2 cache由上文提到的C/B bit决定。这很关键,后续分析中也会有所涉及。先假设cpu需要访问cache,是如何访问的,后文会有详细解读。总之,cpu从cache中获取了数据。
3.如果C/B位中配置页表项为非cache的,或者cache访问时没有命中,则cpu直接发出物理内存访问请求。
一.首先要说清楚软件中使用的内存从何而来,这对分析问题至关重要。_get_free_pages是linux系统中常见的申请内存的方式。大家是否清楚它申请的内存从何而来,又具备怎样的特征?
观察这两个标记GFP_KERNEL | GFP_DMA。在linux中,通常包括ZONE_DMA/ZONE_NORMAL/ZONE_HIGHMEM 等zone_type:
1)ZONE_DMA:主要用于兼容早期只能在0-16M做DMA映射的device。很多平台上没有使用。
2)ZONE_HIGHMEM一般是32位系统上使用超过896MB内存,内核线性地址区间不足以映射所有地址。S2平台也没有使用
3)ZONE_NORMAL:正常的低端地址,很多平台使用,该函数实际上是从ZONE_NORMAL中申请的页框。ZONE_NORMAL对应linux内核中的低端内存区。
二 Linux系统启动过程中,配置低端内存页表项的方法可以参考博文linux内核是如何实现分页机制的。
总之linux内核在mem_types中定义了初始页表项属性:
prot_pte = L_PTE_PRESENT | L_PTE_YOUNG | L_PTE_DIRTY。
其实在内核启动过程中build_mem_type_table(),还会根据不同arm版本做调整,s2中将低端内存cache配置为写回模式。
#define L_PTE_MT_WRITEALLOC (_AT(pteval_t, 0x07) << 2);
三 由以上两点分析出结论如下:
实验:在内核态下,尝试把__get_free_pages申请到的内存的页表项属性修改为 uncached(在ioremap_page_range中实现):
实验结论:理论上该实验是可以解决问题的,但实验结果仍然失败了,为什么?因为linux kernel不允许对已经建立页表的低端内存进行再次映射。
不过 ,也不是没有其他方法进行该实验,可以参照linux的经典做法,把低端内存,映射到高端内存区即vmalloc区,在此过程中修改页表项属性。具体实现可以参照内核接口: __dma_alloc_remap()–>ioremap_page_range() 因为最后定位了问题,所以该实验没有继续做。
#define ioremap(cookie,size) __arm_ioremap((cookie), (size), MT_DEVICE)
#define ioremap_nocache(cookie,size)__arm_ioremap((cookie), (size), MT_DEVICE)
#define ioremap_cached(cookie,size) __arm_ioremap((cookie), (size), MT_DEVICE_CACHED)
观察上面ioremap函数mtype,都为MT_DEVICE,这是驱动专用的设备物理内存范围,也是cpu地址线的范围,并不对应真正的dram内存,。此处讨论低端内存为mtype=MT_MEMORY.
2 mmap系统调用。
一 用户进程通过mmap把__get_free_pages申请到的内存映射到用户空间进行使用,本文提到的核心问题就是用户映射后,内存上的数据被篡改。对于linux标准的/dev/mem来说,mmap->mmap_mem:
其中,打开设备时,open("/dev/mem", O_RDWR|O_DSYNC,0); O_DSYNC 标记会把vm_page_prot指定为uncached/unbufferd.
尽管我们实现过程中没有使用标准的/dev/mem,而是自己实现了一个驱动。但设计思想没有改变。都是通过remap_pfn_range为物理地址在用户空间创建页表。
二 实验:在mmap前后进行cache无效,cache关闭等实验,目的就是验证remap_pfn_range是否创建出nocachede页表项。具体见下面代码截图。
结论:mmap过程没有问题。
经过上述实验,有两点怀疑
1) 用户的remap过程有问题。
2) 实验方法有问题,即对cache的操作有问题。所以继续探究下cpu与l1-cache、l2-cache的关系。分析之前,简单介绍一下TLB过程。
分析过程:几个cache相关实验后(具体见下文),开始怀疑并非cache问题。是否因为:
1)不同进程虽然各自都为 同一段物理内存做分页映射,但进程的虚拟地址空间是一样的。同一virtual address对应多个页表项,而TLB却没有更新导致TLB查找到的页表项不是当前进程的映射的。
即相同的虚拟地址对应不同的物理地址,造成TLB出错。
linux内核启动之初,就已经为内核态线性地址指定了页全局目录的基地址,即TTB。而且进程上下文切换时使用各自不同的ttb。ttb定义如下:
/*
* swapper_pg_dir is the virtual address of the initial page table.
* We place the page tables 16K below KERNEL_RAM_VADDR. Therefore, we must
* make sure that KERNEL_RAM_VADDR is correctly set. Currently, we expect
* the least significant 16 bits to be 0x8000, but we could probably
* relax this restriction to KERNEL_RAM_VADDR >= PAGE_OFFSET + 0x4000.
*/
/* 形如0x80008000或0xc0008000 */
#define KERNEL_RAM_VADDR (PAGE_OFFSET + TEXT_OFFSET)
#define PG_DIR_SIZE 0x4000
#define PMD_ORDER 2
/*
1)内核中页全局目录的基地址swapper_pg_dir为形如0x80004000或0xc0004000
2)每个进程的页全局目录地址(task_struct->pgd)上的内容,内核态的部分都是从swapper_pg_dir地址上拷贝的。
*/
.globl swapper_pg_dir
.equ swapper_pg_dir, KERNEL_RAM_VADDR - PG_DIR_SIZEint remap_pfn_range(struct vm_area_struct *vma, unsigned long addr,
unsigned long pfn, unsigned long size, pgprot_t prot)
{
pgd_t *pgd;
unsigned long next;
unsigned long end = addr + PAGE_ALIGN(size);
struct mm_struct *mm = vma->vm_mm;
int err;
do {
next = pgd_addr_end(addr, end);
err = remap_pud_range(mm, pgd, addr, next,
pfn + (addr >> PAGE_SHIFT), prot);
if (err)
break;
} while (pgd++, addr = next, addr != end);
/*在此添加flush tlb操作*/
flush_tlb_all();
return err;
}2 MMU的TLB过程简介:

2 页一级目录描述符地址上保存了页二级目录描述符基地址,再根据虚拟地址的索引页找到指定地址的页二级目录描述符的物理地址;以此类推,最后找到指定虚拟地址对应的物理地址。
在此只是简单介绍下,有兴趣可以参考arm手册。
为了更好的理解,重新明确一下cache的几个概念:
写通cache(write-through):
cpu发出写信号时,也写入主存,保证主存能同步更新。优点是操作简单,但由于访问主存速度慢,降低了系统系能。
回写式(write-back):
Cpu发出写信号时,数据一般写到cache上,当 cache中dirty标志位设置时,才回写到内存。
轮转策略与随机策略:
当一个cache访问失效时,cache控制器会从当前有效行中取出一个cache行存储从主存获取的信息,被选中替换的cache行,如果drity位为1,则回写到主存,而替换策略决定了哪个cache line会被替换。轮转策略就是取当前cache 行的下一行替换;随机策略是控制器随机选择。
Cache类型:
1 PIPT 一般用于D cache即数据cache与指令cache相对。
这种类型避免上下文切换时要flush cache,但是由于皆采用物理地址,每次判断命中都必须进行地址转换,速度较慢。
2 VIVT 老式缓存
避免cache命中后地址转换,但上下文切换后地址映射改变,必须flush cache,效率不高。
3 VIPT 新式cache
Cache通过index查询到正确set时,TLB可以完成虚拟地址到物理地址转换,在cache比较tag时,物理地址已经准备就绪,也就是说physical tag 可以和cache并行工作,虽然延迟不然VIVT但是不需要上下文切换时flush cache.
为了验证问题,尝试mmap后把cache disable掉,注意不是invalid cache即无效cache,因为invalid只是清除当前cache line的有效位,并未真正的关掉cache。
二:关闭l1cache
1)参考代码如下,主要实现关闭l1cache
void disabel_l1_cache()
{
u32 value=0;
flush_cache_all();
asm("mrc p15,0,%0,c0,c0,1 @get CR":"=r"(value)::"cc");
/*
获取cache type (0x83338003)
*/
__asm__ __volatile__(
"mrc p15,0,%0,c1,c0,0":"=r"(value):);
/*
实验:关闭 l1cache的icache和dcache;
bit12:icache enable/disable = 1/0;
bit2dcache enable/disable=1/0
*/
value &=(~0x1004);
__asm__ __volatile__(
"mcr p15,0,%0,c1,c0,0":"=r"(value):);
flush_cache_all();
isb();
/* 判断上面mcr是否成功 */
__asm__ __volatile__(
"mrc p15,0,%0,c1,c0,0":"=r"(value):);
}结论:cache不能完全关闭,Dcache一旦关闭,系统会卡死。
2)cp15 register1描述,笔者是通过这个寄存器关闭的l1cache.

参考disable_l1_cache,实际上是控制bit2和bit13 实现的l1 cache关闭。
3)Cp15-register0: cache type描述。
本节主要介绍cache type寄存器的格式,可以通过该寄存器获取cache类型,大小,cache line长度等信息。本部分非常简单,都是直接从arm手册中找到的信息,贴到此处供大家参考。
一 disable_l1_cache中读出的关键字段定义(0x83338003):

二 cache type寄存器格式:
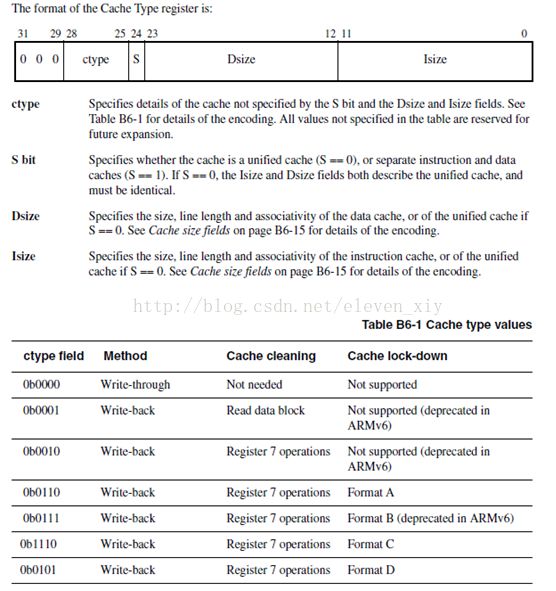



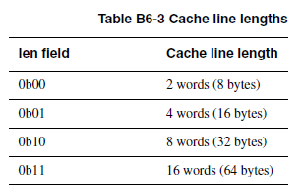
1)L2-cache又称外部cache,通过AXI bus进行控制。下例中介绍下cache访问过程。
/* 获取l2-cache信息 */
void l2x0_init(void __iomem *base, u32 aux_val, u32 aux_mask)
/* l2-cache register访问 */
readl_relaxed(l2x0_base + L2X0_AUX_CTRL);
/* l2-cache信息 */
以Auxiliary control register 为例:
* L310 cache controller enabled
* l2x0: 16 ways, CACHE_ID 0x410000c8, AUX_CTRL 0x02050000,
* Cache size: 512k ;
2)AUX_CTRL=0x02050000,二进制如下:

全相联cache:的特点是任何一个VA都可以缓存到任何一条cacheline 。查找cache,要检查所有cache line。
直接映射cache:的特点是VA只允许缓存到某一条cacheline,查找过程块,检查一下应该缓存的VA对应的TAG是否与cacheline中的TAG一致,如果一致就cache hit否则cache miss。
组相联cache:全相联cache和直接映射cache各有优缺点,全相联cache查找慢,但没有抖动问题,直接映射cache,正好相反。实际cpu的cache设计取两者的折衷,把所有cache line分成若干组,每一组n条cache line,称为 n路组相联cache。

31 14 11 5 4 0
| TAG | index | |cacheline|
其中:
1)way=16,每个way中有512k/16/32=1024个cache line,每个way都是直接映射的。
2)way=16表示16路组相连,每个组中有16个cache line,且每个组都是全相联的,每个组称为一个cache set。
3)以VA=0x76bb9610为例:index=0xb0 找到对应的 cache set;
同时MMU根据该VA 通过TLB找到PA,并计算出TAG,再与cache set中的16个cacheline进行逐一对比。
每个用户态进程,在创建过程中都从内核态下的init_mm拷贝页全局目录到各自的pgd里。也就是每个进程都保存了一份页内核态的全局目录。以amba为例,用户态进程的pgd里保存了线性地址0x80008000 之上的页表。
所以每个用户态进程,切换到内核态下都能正常访问内存。但作为用户态进程,在用户态运行时,需要为用户态地址空间创建页表,例子:0-0x80000000的地址空间创建页表。如malloc或者mmap的过程都是为用户态虚拟地址创建页表的过程。
大体过程如下:1)首先每个进程管理一个虚拟内存区 的结构体vm_area_struct,他实际保存的是,虚拟地址的使用范围,用户申请内存时会根据vma找到一个未使用的虚拟地址空间(这个空间时用户态地址空间0x80000000以下),然后再把要使用的物理地址映射到该空间上,即创建页表。
如果不知道物理地址,如malloc.则一般不马上申请物理地址,而只是返回给用户一个地址范围,当用户真正访问时,内核态通过缺页异常申请地址页,再转换为物理地址,并映射到返回给用户的那个地址范围上。
此时MMU中tlb查到了对应用户态虚拟地址的页表项(mmap时创建remap_pfn_page),同时cache根据该虚拟地址计算出index,并根据该index查询到组相连cache中的一组,一般来讲,armv7的cache是组相连的,组与组之间是直接映射的(不同index代表不同组),而组内的cacheline是全映射的,组内地址可以映射到任意cacheline里面,然后再根据tag进行cache查询。
如上,不同用户态进程都有各自不同的页表,但内核态只有一组页表,因此在访问内核态线性地址空间时,cache都是根据内核创建的页表项进行访问的,我们使用VIPT的cache,
对应512K-16way-32byte 的cache来说,virtual index 是5到14位,每隔32K的virtual index在cache的一组里面(一组有16个cacheline),因此同一个物理地址,有可能内核态和用户态,对应的cacheline不一样。
1)虽然用户使用mmap映射物理内存时,页表属性是关闭cache的。
2)但是这段物理内存映射在内核态的线性地址空间时,页表项属性中开了cache(低端内存都是打开cache的)
.mm_rb = RB_ROOT,
.pgd = swapper_pg_dir,//每个进程都从这里拷贝页全局目录到各自的pgd里
.mm_users = ATOMIC_INIT(2),
.mm_count = ATOMIC_INIT(1),
.mmap_sem = __RWSEM_INITIALIZER(init_mm.mmap_sem),
.page_table_lock = __SPIN_LOCK_UNLOCKED(init_mm.page_table_lock),
.mmlist = LIST_HEAD_INIT(init_mm.mmlist),
INIT_MM_CONTEXT(init_mm)
};
可见不同进程,都保存了内核态虚拟地址的所有页表项。
用户空间再申请地址时(amba:用户态虚拟地址空间0-0x80000000)
需要再次映射,此时产生新的页表,这与内核态页表是不同的。
同时,即使同一物理内存对应的用户态和内核态虚拟地址也可能不在同一个cacheline。
#define cpu_switch_mm(pgd,mm) cpu_do_switch_mm(virt_to_phys(pgd),mm)
ENTRY(cpu_v7_switch_mm)
#ifdef CONFIG_MMU
mmid r1, r1 @ get mm->context.id
asid r3, r1
mov r3, r3, lsl #(48 - 32) @ ASID
mcrr p15, 0, r0, r3, c2 @ set TTB 0
isb
#endif
mov pc, lr
ENDPROC(cpu_v7_switch_mm)