一、背景
本周bobo项目例会,我们有涉及根据查询以往日志获取绑定状态的需求。项目组讨论说可以研究一下splunk,看是否可以利用到项目中。我原来也没有接触过,表示可以研究下。
用时:大概1天
二、整体流程
- 建一个服务端,用来接收各个机器的日志。服务端有web页面,可以检索。服务端也可以对外提供api接口,供第三方应用去获取信息。
- 每个日志服务器上建一个客户端(通用转发器),用来收集日志给服务端。
三、安装
下载地址:官网 https://www.splunk.com/
- 服务端
splunk-7.1.2-a0c72a66db66-linux-2.6-x86_64.rpm
rpm -ivh --prefix=/data/test/ splunk-7.1.2-a0c72a66db66-linux-2.6-x86_64.rpm
cd /data/test/splunk/bin
./splunk start --accept-license
输入想设置的密码再次确认即可
查看和修改端口的命令分别如下:
./splunk show splunkd-port
./splunk set splunkd-port 80**
web访问:http://127.0.0.1:8000 admin/设置的密码
- 客户端(通用转发器)
splunkforwarder-7.1.2-a0c72a66db66-linux-2.6-x86_64.rpm
rpm -ivh splunk-7.1.2-a0c72a66db66-linux-2.6-x86_64.rpm
cd /opt/splunkforwarder/bin
./splunk start --accept-license
输入想设置的密码再次确认即可
注意:如果splunk 服务和通用转发器安装在同一台服务器,通用转发器的管理端口也是8090,会有冲突,有冲突的时候会提示,选择yes,修改端口即可。
四、配置
服务端配置 转发和接收
登录web页面-设置-转发和接收-配置接收,点击 +新增,可以就用建议的 9997 作为接收数据的端口。客户端配置服务和监听文件
设置客户端的输出(发送的服务器和端口):./splunk add forward-server server_ip:9997
查看你的输出设置:./splunk list forward-server
注册客户端到服务器:./splunk set deploy-poll server_ip:8089
监控日志的目录或者文件:
./splunk add monitor /opt/product/data/bblive/logs/schedule.log
以上客户端的输入和输出配置也可以通过修改他的配置文件来生效。
监控哪些目录可以修改:$SPLUNK_HOME/etc/system/local/input.conf
格式如下:
host = 本机的hostname
[monitor://日志地址(这里可以使用正则来过滤数据)]
index=indexName
sourcetype=sourceName
[monitor://另一个]
index=indexName
sourcetype=sourceName
[monitor:///xxx/xxx/log/xxx/xxx.log]
index=xxxxxxxx
sourcetype=xxxxxx
转发数据到哪可以修改:$SPLUNK_HOME/etc/system/local/output.conf
[root@local]# cat outputs.conf
[tcpout]
defaultGroup = default-autolb-group
[tcpout:default-autolb-group]
server = 192.168.***.**:9997
[tcpout-server://192.168.***.***:9997]
配置修改需要重启客户端。配置好后web的搜索界面看到索引的目录里面的日志文件了。
五、web页面搜索
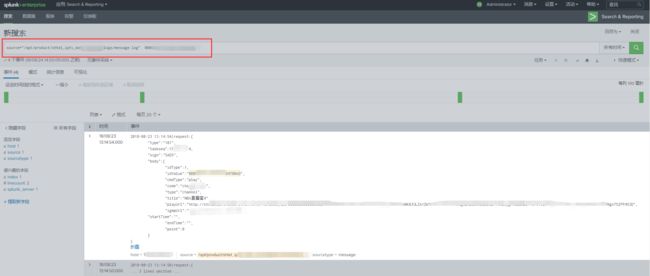
到目前为止,如果作为运维人员平时搜索日志,其实已经满足了。到这一步已经和 FileBeat +Logstash +Elasticsearch+Kibana 功能一样了,但是我感觉 spunk更便捷。其实,splunk的检索应该是很强大的,也可以自己定义规则对日志做统计,生成报表和仪表盘,我研究的还不深入,后面可以继续探索。
六、对外提供API接口
研发的需求是希望splunk可以对外提供接口,供我们的内部应用调用访问。研究下来,目前可以搜索接口:

主要思路:利用SN号查询到request 的 taskseq 号,再利用taskseq 查到 response里面的 在线状态 online。
Splunk的搜索接口(测试地址):
https://192.168.***.****:8089/services/search/jobs
以下是命令行方式调用接口:
curl -k -u admin:passwd https://192.168.220.***:8089/services/search/jobs -d search="search source=\"/opt/product/shtel_iptv_bobo_touping/logs/message.log\" 000600191******4780AD queryStatus | head 5"
以上命令获取到 message.log 日志中,SN号是 000600191******4780AD 且查询类型是 queryStatus 的前5条数据。
返回:
1535002930.69
拿到返回的 sid号,再执行:
curl -k -u admin:passwd https://192.168.***.***:8089/services/search/jobs/1535002930.69/results/ --get -d output_mode=csv
或者放到 json里面:
curl -k -u admin:passwd https://192.168.***.***:8089/services/search/jobs/1535002930.69/results/ --get -d output_mode=json 2>/dev/null >out.json
得到 taskseq 为 1844674407<再次拿着得到 1844674407 去查
curl -k -u admin:passwd https://192.168.***.***:8089/services/search/jobs -d search="search source=\"/opt/product/shtel_iptv_bobo_touping/logs/message.log\" 1844674407 | head 5"
得到
再执行:
curl -k -u admin:passwd https://192.168.***.***:8089/services/search/jobs/1535003009.70/results/ --get -d output_mode=csv
就可以得到 在线状态了 online=true。
现在对api的调用只是基于最基本的搜索功能,没有利用到splunk的统计功能,应该可以自己定义规则、字段、让splunk对日志信息做统计再输出给外部应用。目前的api搜索功能满足项目需求,已整理文档发给项目内部,研发表示可以使用。
<完!>