Flume OG
OG:“Original Generation”
0.9.x或cdh3以及更早版本
由agent、collector、master等组件构成
Flume NG
NG:“Next/New Generation”
1.x或cdh4以及之后的版本
由Agent、Client等组件构成
为什么要推出NG版本
精简代码
架构简化
Flume OG基本架构


Agent
用于采集数据
数据流产生的地方
通常由source和sink两部分组成
Source用于获取数据,可从文本文件,syslog,HTTP等获取数据;
Sink将Source获得的数据进一步传输给后面的Collector。
Flume自带了很多source和sink实现
syslogTcp(5440) | agentSink("localhost",35856)
tail("/etc/service_files") | agentSink("localhost",35856)
Collector
汇总多个Agent结果
将汇总结果导入后端存储系统,比如HDFS,HBase
Flume自带了很多collector实现
collectorSource(35856) | console
CollectorSource(35856) | collectorSink("file:///tmp/flume/collected", "syslog");
collectorSource(35856) | collectorSink("hdfs://namenode/user/flume/ ","syslog");
Agent与Collector对应关系

Agent与Collector对应关系
可手动指定,也可自动匹配
自动匹配的情况下,master会平衡collector之间的负载。

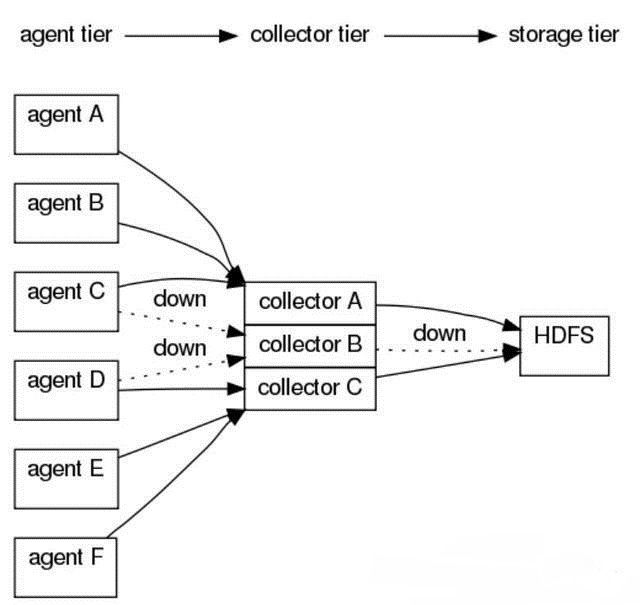
问题:为什么引入Collector?
对Agent数据进行汇总,避免产生过多小文件;
避免多个agent连接对Hadoop造成过大压力 ;
中间件,屏蔽agent和hadoop间的异构性。
Master
管理协调 agent 和collector的配置信息;
Flume集群的控制器;
跟踪数据流的最后确认信息,并通知agent;
通常需配置多个master以防止单点故障;
借助zookeeper管理管理多Master。
容错机制
三种可靠性级别
agentE2ESink[("machine"[,port])]
gent收到确认消息才认为数据发送成功,否则重试.
agentDFOSink[("machine"[,port])]
当agent发现在collector操作失败的时候,agent写入到本地硬盘上,当collctor恢复后,再重新发送数据。
agentBESink[("machine"[,port])]
效率最好,agent不写入到本地任何数据,如果在collector 发现处理失败,直接删除消息。
构建基于Flume的数据收集系统
1. Agent和Collector均可以动态配置
2. 可通过命令行或Web界面配置
3. 命令行配置
在已经启动的master节点上,依次输入”flume shell”è”connect localhost ”
如执行 exec config a1 ‘tailDir(“/data/logfile”)’ ‘agentSink’
4. Web界面
选中节点,填写source、sink等信息
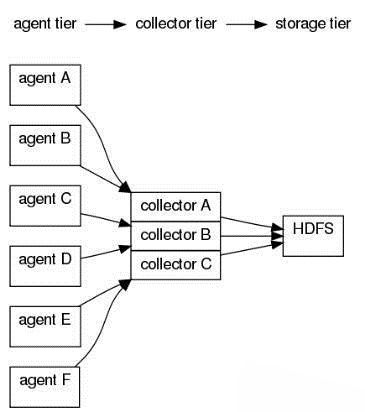
常用架构举例—拓扑1
agentA : tail(“/ngnix/logs”) | agentSink("collector",35856);
agentB : tail(“/ngnix/logs”) | agentSink("collector",35856);
agentC : tail(“/ngnix/logs”) | agentSink("collector",35856);
agentD : tail(“/ngnix/logs”) | agentSink("collector",35856);
agentE : tail(“/ngnix/logs”) | agentSink("collector",35856);
agentF : tail(“/ngnix/logs”) | agentSink("collector",35856);
collector : collectorSource(35856) | collectorSink("hdfs://namenode/flume/","srcdata");

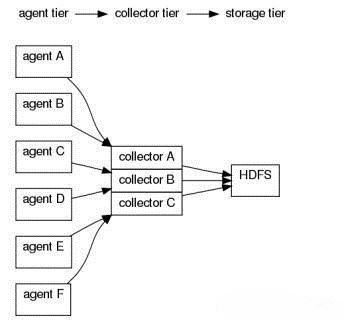
常用架构举例—拓扑2
agentA : src | agentE2ESink("collectorA",35856);
agentB : src | agentE2ESink("collectorA",35856);
agentC : src | agentE2ESink("collectorB",35856);
agentD : src | agentE2ESink("collectorB",35856);
agentE : src | agentE2ESink("collectorC",35856);
agentF : src | agentE2ESink("collectorC",35856);
collectorA : collectorSource(35856) | collectorSink("hdfs://...","src");
collectorB : collectorSource(35856) | collectorSink("hdfs://...","src");
collectorC : collectorSource(35856) | collectorSink("hdfs://...","src");
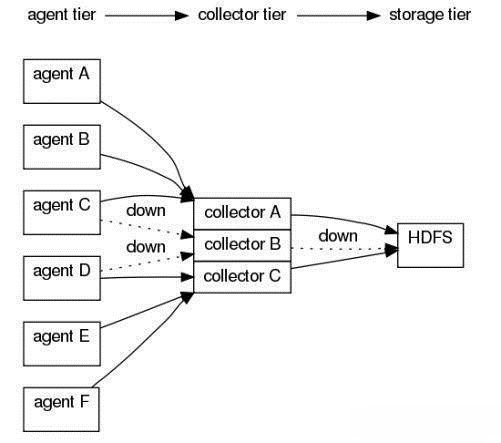
常用架构举例—拓扑3
agentA : src | agentE2EChain("collectorA:35856","collectorB:35856");
agentB : src | agentE2EChain("collectorA:35856","collectorC:35856");
agentC : src | agentE2EChain("collectorB:35856","collectorA:35853");
agentD : src | agentE2EChain("collectorB:35853","collectorC:35853");
agentE : src | agentE2EChain("collectorC:35853","collectorA:35853");
agentF : src | agentE2EChain("collectorC:35853","collectorB:35853");
collectorA : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorB : collectorSource(35853) | collectorSink("hdfs://...","src");
collectorC : collectorSource(35853) | collectorSink("hdfs://...","src");