Colorful egg : Ctrl+F to be continued...
Day 1 | matplotlib
11.10 Lines, bars and markers
plt.plot(*arg, [fmt], data=None, **kwargs)
plt.setp(obj, *args, **kwargs)
plt.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)
xticks(ticks=None, labels=None, **kwargs)
plt.legend(labels) or plt.legend(handles, labels, loc)

plt.subplot(nrows=1, ncols=1, sharex=False, sharey=False, squeeze=True, subplot_kw=None, gridspec_kw=None, **fig_kw)
# return fig, ax, ax is an Axes contains most of the figure elements
▲ax.text()
lower() # normalize the case of the parameter to lower case

numpy.random.seed(seed=None), called when RandomState is initialized
# 确定生成随机数的起始位置以及随后生成的整个随机数组
ax.broken_barh(xranges, yranges, *, data=None, **kwargs)
# xranges, yranges: sequence of tuples(xmin, xwidth) & (ymin, ywidth)
ax.set_ylim() ax.set_yticks() ax.set_ytickabels() ax.grid() ax.annotate()
To be continued :
# ax.text()/'{}'.format(height)/ha
# fig, ax = plt.subplot()
# ax.annotate()
----done
Day 2 | matplotlib
11.13
Day 3 | matplotlib
11.15 Eventcollection, fill area
Day 4 | matplotlib
11.16 Histograms, Gradient Bar, Interp Demo, Join styles, Dashed line
调用混合参数类型函数时需注意调用函数的次序:1) 必须的函数 2) 可选的函数 3) 过量的位置参数:*args 4)过量的关键字参数:**kwargs
>> def add(a, b, c)
return a+b+c
>>args = (2, 3)
>>kwargs = {'b': 2, 'c': 3}
>>add(1, 2, a=7) & add(a=7, *args)是会报错的,因为放在后面的位置参数会和python根据次序规则扩展的过量参数冲突。
zip(*iterables)
# 从参数中的多个迭代器选取元素组合成新的迭代器,返回内部元素为元组或列表的zip对象
# *zip()是zip()的逆过程,将zip对象变成组合前的数据
>> m = [m1, m2, m3]
>> p = [p1, p2]
>> list(zip(m, p))
>> [(m1, p1), (m2, p2)]
# np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
# np.linspace is similar to np.arange, but uses a number of samples(instead of a step size)
# np.interp(x, xp, fp, left=None, right=None, period=None)
# x-array_like:x-coordinates at which to evaluate the interpolated values
# xp-1D sequence:x-coordinates of data points, increasing of period with xp=xp%period
# fp-1D sequence of float or complex:y-coordinates of data points, same length as xp
# return y-float or complex or ndarry:interpolated values, same shape as x
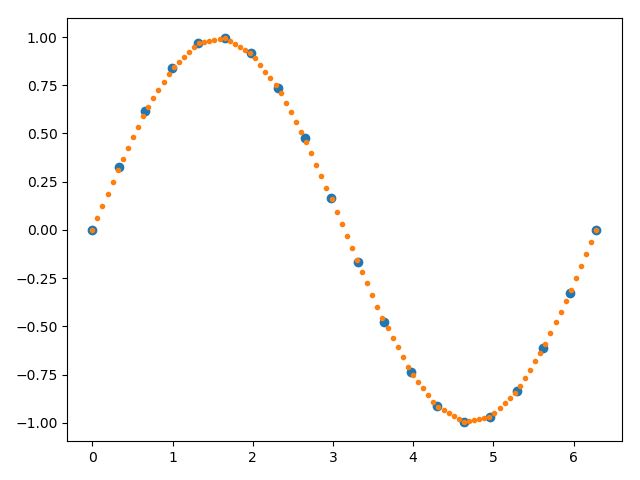
# np.radians(x, out=None, *, where=True)
# Convert angles from degrees to radians
# enumerate(sequence, start=0)
# >> seasons = ['A', 'B', 'C']
# >> list(enumerate(seasons))
# [(0, 'A'), (1, 'B'), (2, 'C')]
# >> for i, season in enumerate(seasons):
# >> print(i, season)
To be continued:
ax.imshow(X, interpolation='bicubic', cmap=plt.cm, extent=(left, right, bottom, top), alpha=1)
ax.set_aspect('auto')
distinguish: x[1:], x[1::-1], x[1:2]
Day 5 | Python Crash Course
Python List 和 numpy array有些区别。List 元素本质是对象,需要指针,比较浪费内存。而numpy提供的ndarray对象是存储单一数据类型的多维数组。
type(d) 返回d的数据类型,而d.dtype() 返回数组内容的数据类型。
numpy的arange() 可以生成浮点数,python的range() 只能生成整型。
Little Trick:
reshape(-1, 1) 生成列向量(矩阵)
数组切片按照 [开始:结尾:步长]的格式进行--a[::-1]
数组相加不需要行列相等
>> a = np.array([1, 2, 3])
>> b = a.reshape(-1, 1)
a+b返回一个3*3的矩阵
To be continued:
for and sum()
Day 6 | Python Crash Course
Day 7 | Python Crash Course
Day 10 | Matlab Crash Course
C1 Matlab 环境
1、常用标点符号的功能
, -- 要显示计算结果的命令、输入变量、数组行元素之间的分隔
; -- 不显示计算结果的命令行的结尾;不显示结果命令、数组元素行之间的分隔
: -- 表示一维数组的全部元素
() -- 引用数组元素,函数输入变量列表
[] -- 构成向量和矩阵,函数输出列表
{} -- 构成元胞数组
... -- 续行号
@ -- 放在函数名前形成函数句柄;放在目录前行程用户对象类目录
Day 11 | R Crash Course - 3.7
C1 R的使用
R语句由函数和赋值构成,输入区分大小写。
R使用 <—作为赋值符号。不推荐用=赋值,因函数条件中用=时能取值运算,但却没有赋值,# 是注释符号;
# 基础操作
设置默认的镜像:options(repos=structure(c(CRAN="YOUR FAVORITE MIRROR")))
查看版本:version
安装Bioc下载工具:> source("https://bioconductor.org/biocLite.R") > biocLite() 安装包
# Base function
c() 以向量形式赋值;
mean(), sd(), cor() 求数据的均值、标准差和相关度;
plot() 作图;
# Help function
help(foo) or ?foo 查看foo函数的帮助;
apropos("foo",mode="function")列出名称含有foo的所有函数;
vignette(“foo”)为主题foo显示指定的vignette文档;
# Workspace function
Workspace是当前工作环境,存储用户定义的所有对象(向量,矩阵,函数,数据框,列表)
getwd(), setwd() 显示和修改当前工作目录;
ls() 列出当前对象; rm(objectlist) 删除对象;
options() 显示或设置当前选项;
save.image("myfile") 保存工作空间到文件myfile(默认.RData);
save(objectlist,file="myfile") 保存指定对象到文件夹中;
load("myfile")读取工作空间到当前会话中;
# 输入和输出
脚本执行:source("filename") 执行路径中的脚本文件,路径默认当前目录;
文本输出:sink("filename") 将输出重定向到filename中,默认覆盖原内容;参数append=True可将文本追加到文件后;参数split=True可将输出同时发送至屏幕和输出文件。无参数sink() 仅项屏幕返回结果;
图形输出:bmp("filename")、jpeg("filename")、pdf("filename")、png("filename")、postscript("filename")、svg("filename")、wim.metafile("filename")
最后可使用dev.off() 将图形输出返回到终端;
# 包(Package)
(.packages())、search() 已加载的包 remove.packages("packages_name", lib="lib_path") 删除包 help(package="package_name") 查看包的函数
packageVersion("package_name") 查看版本
.libPaths() 显示库所在位置 library() 显示库中的包
install.packages()、BiocManager::install("pkg_name") 下载安转包 update.packages() 更新包 installed.packages() 列出已安装包的信息
library() 加载包
函数名重叠时,R将优先调用最后载入的程序包。若想执行被屏蔽的函数,键入 包名::函数名(mt) ,如:Hmisc::describe(mt)
# 程序常见错误 ▲
1、没有注意大小写 2、没有注意引号 3、函数调用是没加括号 4、路径使用"\\"或“/”,而不是"\" 5、使用已安装但尚未载入的包
# 批处理
批处理模式能重复、无人值守地执行程序
对于RLinux或Mac系统,可在终端输入:R CMD BATCH options infile outfile
对于windows,需使用:>“chelp.s:\Program Files\R\R-3.1.0\bin\R.exe” CMD BATCH > --vanilla --slave "c:\my project\myscript.R"
C2 数据结构
2.1 数据结构
R的数据类型有标量、向量、矩阵、数组、数据框和列表。
R能处理的数据类型有数值、字符、逻辑、复数和字节。名义型和有序型变量在R中被称为因子。
# 向量
向量只能存储数值、字符或者逻辑型数据,且单个向量中的数据要有相同的类型。组合功能函数c()用于创建向量。
而向量元素的位置用 ‘[ ]’来定位。e.g.a[3], a[c(1,3)], a[2:6]都可行
# 矩阵
矩阵是一个二维数组,每个元素都有相同的类型(数值、字符或逻辑)。创建矩阵的一般格式为:mymatrix <— matrix(vector, nrow, ncol, byrow=FALSE, dimname=list(char_vector_rownames, char_vector_colnames)),一般情况下,默认按列填充。
# 数组
矩阵可通过 myarray <— array(vector, dimensions, dimnames)创建,dimnames是可选的各维度名称标签列表。
# 数据框
数据框中不同的列可以用不同的数据类型,常用 mydata <— data.frame(col1, col2, col3, ..., row.names=case_identifier_name),实例标识符(case_identifier)用于指定各类实例的名称。
选取数据框中的元素可用 '$' 完成,也可用函数 attach()、with() 简化书写。
e.g.1 >plot(mtcars$mpg, mtcars$disp)
e.g.2 >attach(mtcars) >plot(mpg, disp) >detach(mtcars) --attach() 将数据框添加到R的搜索路径中,R遇到变量名时会检查搜索路径中的数据框。适用于分析单一数据框且无同名对象的情况。注意养成调用完用detach() 从路径中移除的习惯。
e.g.3 >with(mtcars, {>stats <- summary(mpg) >stats})
with() 中有多条语句需用 ‘{ }’包起来,而且语句中的赋值只生效于括号内,若要在括号外也生效,则要用特殊赋值符 '<<—' 替代普通赋值符 '<—'。通常来说,with()比attach()更好用。
# 因子
函数factor() 以整数向量存储类别值。对于名义型变量:
e.g. >diabetes <— c("Type1", "Type2") >diabetes <— factor(diabetes)
对于有序变量,函数按默认字母顺序排序,这一般不准确,需要指定 “levels”选项排序:
e.g.> status <— c("Poor", "Improved", "Excellent") > status >— factor(status, order=TRUE, levels=c("Poor", "Improved", "Excellent")
str(object)可提供对象的结构; summary()显示各变量的统计信息。
*# 列表
列表是一些对象的有序组合,可用 list() 创建:
e.g. > mylist <— list(object1, object2, ...) > mylist <— list(name1=object1, name2=object2, ...)
list的调用待理
# R的一些特性 ▲
1、对象名称中的 '.'没有特殊含义,‘$' 却有其他语言中句点的含义,指示数据框或列表中的某些成分; 2、R不提供注释块的功能,要么逐行#,要么用 if(FALSE){...}注释; 3、赋值给不存在元素时,R会自动扩展数据结构; 4、R中没有标量,以单元素向量出现; 5、R的下标从 ‘1’开始; 6、R无法声明变量,只在首次赋值时生成。
2.2 数据输入
可供R导入的数据源:
1、统计软件:SAS SPSS Stata 2、文本文件:ASCII XML Web抓取 3、数据库:SQL MySQL Oracle Access 4、其他:Excel netCFD HDF5
# 小数据导入(键盘输入)
1、创建数据框,然后用文本编辑器输入:
e.g.> mydata <— data.frame(age=numeric(0), gender=character(0)) > mydata <—edit(mydata)
最后一步一定要赋回对象本身,因为编译器只在副本编辑,关闭后不会保存!
2、直接在程序中嵌入数据集:
e.g. > mydatatxt <— ”\n age gender\n 25 m\n30 f\n..." > mydata <— read.table(header=TRUE, text=mydatatxt)
# 数据集标注
R 处理变量标签的能力有限,一种方法是将变量标签作为变量名。e.g. > names(data)[2] <— "label_name"
值标签可用 factor()为类别型变量创建,levels 代表变量实际值,labels 代表值标签。 e.g. > data$variable <— factor(data$variable, levels=c(origin_value), labels=c(label_value))
# 对象的实用函数
length() 对象中元素/变量的数量 dim() 维度 str() 结构 class() 类型 mode() 对象的数据类型 names() 各成分名称 c(object, object,..) 合并向量,会自动统一数据类型 cbind() 按列合并 rbind() head() 显示前六行 tail() 显示后六行 rm() (rm(list=ls())可以删除除 ’.‘开头的所有对象) newobject <— edit(object)、fix(object) 编辑对象
C3 初阶图形
通过在开启图形设备和关闭图形设备语句之间放入绘图语句即可保存相关类型的图形。另,创建多窗口图形需要打开多个图形窗口,命令集如下:
dev.new() 创建新窗口 dev.next()窗口切换 dev.prev() dev.cur() 当前窗口序号 dev.off() 关闭当前窗口 dev.set() 窗口跳转 graphics.off() 关闭所有窗口
# 图形参数
--lty(1-6) 线类型 --pch(1-25) 点类型 --cex 点大小 --lwd 线宽 --type("p", "l", "b", "h", "s", "S")
可用par() 来设定参数再绘图(设置所有绘图), 也可以直接在plot() 里添加属性(设置单一绘图)。用par()之前一般先用 opar <— par(no.readonly=TRUE) 保存默认设置。
# 颜色plot(dose, dt
rainbow() heat.colors() terrain.colors9) topo.colors() cm.colors() RColorBrewer() gray()
# 文本属性
-cex 默认大小倍数 -cex.axis 刻度文字大小 -cex.lab -cex.sub -cex.main -font 字体样式(1-5) -family 字体族 -windowsFont() Windows中的字体映射
# 图形尺寸
--pin() 以英寸表示的图形尺寸(宽和高) --mai() 英寸单位的边界(下、左、上、右) --mar() 英分单位的边界,默认 c(5,4,4,2)+0.1
*# 基础函数
line() 添加图形 title() 添加标题
text(-location 位置,为x,y坐标 -"text" -pos 方位,1下左上右,可加offset偏移量 ) 添加文本
mtext(-"text" -side 放置文本的边 -line 负内正外移动文本) 在边界添加文本
axis(-side(1下2左3上4右) -at 数值向量,刻度线位置 -las 标签0平行或2垂直坐标轴 -tck 刻度线长度,负值图外,正值图内,1绘制网络线,默认 -0.01, -ylim 刻度范围) 添加坐标轴
abline(h=yvalues, v=xvalues) 添加参考线
minor.tick(-nx x刻度划分数 -ny -tick.ratio 刻度线大小比例) 添加次要刻度线(需要导入Hmisc库)
legend(location, title, legendset) 添加图例
*某些高级绘图默认包含标题、标签和坐标,可用 ann=FALSE 移除标题和标签;用 axes=FALSE 移除坐标轴(刻度、坐标、以及框架线),用 yaxt="n" 移除坐标轴的刻度。
# 多图组合
par(-mfrow=c(nrows, ncols) 按行填充 -mfcol 按列填充)
或 layout(mat, widths, heights) 定义多图布局
e.g. layout(matrix(c(1,1,2,3), 2, 2, byrow=TRUE), widths=c(3, 1), heights=c(1, 2)) 划分了按行排列,图一位于一行,图二三位于二行且列宽为3:1,行高为1:2的图组
# 布局微调
可用par(fig=c(x1, x2, y1, y2)) 来具体设定子图的空间位置,绘图区域右左下角(0,0)到右上角(1,1)的区域可用。
同时,-fig 参数默认新建一幅图像,所以添加图前先设定 par(new=TRUE)
C4 数据处理
# 添加新变量
_data_ <— transform(_data_, argu=value) 添加新变量
算术运算符: x^y、x**y 求幂 x%%y 求余 x%/%y 整数除法
逻辑运算符: x==y 严格等于,浮点数比较时慎用 isTRUE(x)
# 变量重编码
within() 与with() 类似,不同的是,within()能修改数据框。
语句 variable[condition] <— expression 能按条件执行赋值
重编码函数有 car包的recode()、doBy包的recodevar()
# 变量的重命名
fix(_data_) 编辑数据 names(_data_) 赋值方法重命名 plyr包的rename() 函数
e.g. _data_ <— rename(_data_, c(oldname="newname", ...))
# 缺失值
缺失值为NA (Not Available) ,与SAS等不同,R数值型和字符型的缺失都为NA,可用 is.na()判别,将返回同等大小逻辑对象。要注意两点:
1、NA不可比较,value == NA 不能识别NA,只能用函数识别。
2、R中无限和不可能出现的数值不会被标记为NA,他们对应的是Inf、-Inf(如5/0)和NAN(not a number, 如sin(Inf))。分别可用is.infinite()和 is.nan()识别。
含缺失值的计算结果也是缺失值。分析前需排除缺失值,一般数值函数都有 na.rm=TRUE 选项删除缺失值,以使用剩余值计算。 另也可以用 na.omit()删除缺失数据的行。
# 日期值
日期值是R 中的一种数据格式。as.Date(date, "input_format") 用于将字符串日期值转化为日期变量,格式有 %d, %a, %A, %m, %b, %B, %y, %Y。日期的默认格式是%Y-%m-%d 。
指定格式的日期可以用 format(_data_, format="output_format")获得。
此外,日期变量的有关函数还有Sys.Date() 当天日期, date() 当前日期时间,difftime() 时间差。
最后,日期变量也能通过 as.character(_data_) 转化为字符型变量。
# 数据排序
order() 对排序变量排序后输出一个排序向量。
e.g. order(-_data_) 按倒序排序。
# 数据集的合并
merge(dataframeA, dataframeB, by="ID") 按照内联结ID 进行列合并 cbind(A, B) 直接合并列
rbind(A, B) 直接合并行,要有相同的变量,否则要1、删除A 的多余变量 或 2、给B 追加缺失值
# 剔除变量
e.g. > _index_ <— names(_data_) %in% c(_rm_list_) > newdata <— _data_[!_index_]
e.g. > newdata <— _data_[c(-c1, -c2,...)] 行列下标为负数意味着剔除
e.g. > _data_$v1 <- NULL NULL是未定义,相当于删除变量
# 选取子集
newdata <— subset(_data_, condition, select=c(v1, v2, ...))
# 采样
mysample <— _data_[sample(1:nrow(_data_), _sampling_num_, replacement=FALSE) 有放回采样
C5 高级数据管理
5.1 数字字符函数
# 数学函数
ceiling(x) 大于x的最小整数 floor(x) 小于x的最大整数 trunc(x) 向0方向截取整数部分 round(x, digits=n) 指定小数位 signif(x, digits=n) 指定有效数位 log(x, base=n) log10(x)
sd(x) 标准差 var(x) 方差 mad(x) 绝对中位差 quantile(x, probs) 求probs之间的分位点 diff(x, lag=n) 滞后n项的差分 scale(x, center=TRUE, scale=TRUE) 按列进行中心化或者标准化
▲# 概率函数
[dpqr]_distribution_abbreviation()
d(density) = 密度函数 p(distribution) = 分布函数 q(quantile) = 分位数函数 r(random) = 生成水技术
distribution_abbreviation:
beta -Beta分布 binom -二项分布 cauchy -柯西分布 chisq -卡方分布 exp -指数分布 f -F分布 gamma -伽马分布 geom -几何分布 hyper -超几何分布 lnorm -对数正态分布 logis -Logistic分布 multinom -多项分布 nbinom -负二项分布 norm 正态分布 pois -泊松分布 signrank -Wilcoxon符号秩分布 t -t分布 unif -均匀分布 weibull -Weibull分布 wilcox -Wilcoxon秩和分布
# 随机种子
每次生成随机数会有一个不同的种子,以产生不同的结果。可以用set.seed() 指定种子,以创建可共享的示例。
# 生成多元正态数据
MASS包的 mvrnorm() 函数,mvrnorm(n, mean, sigma)
*▲# 字符处理函数
nchar(x) substr(x, start, stop)
grep(pattern, x, ignore.case=FALSE, fixed=FALSE) -fixed=FALSE,则 pattern为一正则表达式,否则为一文本字串符;另注意,需要用到反斜杠"\"的正则表达式(如"\s"表示空格符)写法应为"\\s",因为"\"为 R的转义字符
sub(pattern, replacement, x, ignore.case=FALSE, fixed=FALSE) 提取或替换字符向量的字串
strsplit(x, split, fixed=FALSE) 在split 处分割字符串
paste(x1, x2, seq=" ") 连接字符串,分隔符为seq
toupper(x) 大写转换 tolower(x)
# 其他处理函数
length() 求对象中的元素数量 seq(from, to, by) 生成一个等间隔的序列 rep(x, n) 重复 x n次 cut(x, breaks, labels=NULL, orderd_result=F) 若break 为数字,将连续型向量x 等间隔地(左开右闭)分割为 n个水平因子;若break 为向量, 则以该元素为分割点分割 pretty(x, n) 将 x 等分为n个等间距区间 cat(..., file="_filename", append=F) 连接对象(自动以空格间隔)并输出到屏幕或者文件中
table(var1, var2, ...) 使用N个类别型变量创建一个N维列联表
# 矩阵函数
apply(x, MARGIN, FUN) 按区域运行函数
5.2 语法结构
循环
for (var in seq) statement while (cond) statement
条件
if (cond) statement1 else statement2
ifelse(cond, state,ent1, statement2)
switch(expr, ...)
e.g. >feelings <— c("sad", "afraid") > for (i in feelings) print(switch(i , happy="I am glad",...))
函数
function_name <— function(arg1, arg2, ...) { statement; return(obj) }
▲调用自编写函数时,用 source("function_name") 载入
# 整合与重构(reshape2包)
t() 倒置
*aggregate(data, by=list(name1=var1, name2=var2,...,), FUN) 整合数据,但其函数只能调用单返回值的函数 by(data, group, FUN) 则可以调用任何函数 doBy包的summaryBy(formula, data=dataframe, FUN)也能分组计算概述统计量
melt() 数据分解 dcast() 重构
C6 基本图形
# 条形图
barplot(height, horiz=F, besides=F) plot() 也可以根据因子变量快速创建一个条形图 spine() pie() pie3D() Plotrix包fan.plot() hist() rug() density() sm包 sm.density.compare(x, factor) 叠加核密度图
boxplot(formula, data=dataframe, notch= ,) - formula 项有y~A、y~A*B 两种写法,表示类别变量A对于数值变量y生成的箱型图。盒型范围±1.5IQR以外的值以离群点表示
vioplot(x1, x2, ..., names, col) 小提琴图 dotchart(x, labels, groups) 按标签画散点图,且标签按groups 变量进行分组
C7 基本统计分析
# 描述性统计分析
discribe() 返回数据整体的基本信息(样本、特征数量,缺失值、不同值等等),类似的函数还有pastecs 包的stat.desc() 和psych 包的describe()
# 频数表和列联表
table(var1, var2,...) 根据因子创建列联表,默认忽略缺失值 xtabs(formula, data) 根据公式(-formula: y~A+B,y以AB的交叉分类统计频数)创建N维列联表 prop.table(table, margins) 依边际将列表表示为分数形式 margin.table(table, margins) 依边际计算列表条目和 addmargins(table, margins) 给列表添加边际和 ftable(table) 创建平铺式列联表