orm的F功能
假设数据库有一个员工表,表中的年龄都自加“1”,这里就需要到orm的F功能,如下面的代码:
from django.db.models import F#首先要导入这个F模块
models.Uinfo.objects.all().update(age=F("age")+1)#这里的F功能后面的age,它就会让数据表表中的age这列+1F 就是用来更新获取原来值的功能
orm的Q功能
数据库的查询条件我们可以使用filter,在filter里面的可以是两个条件他们之间是and的关系,也可以是一个字典,例如下面的代码
models.Uinfo.objects.all().filter(id=1,name='李伟')
conditon={
'id':'1',
'name':'李伟'
}
models.Uinfo.objects.all().filter(**conditon)除了上面的方法,我们还可以加Q的对象,例如:
from django.db.models import Q
models.Uinfo.objects.all().filter(Q(id=1))#条件是id为1的时候
models.Uinfo.objects.all().filter(Q(id=1)|Q(id__gt=3))#条件是或的关系,|
models.Uinfo.objects.all().filter(Q(id=1) & Q(id=4))# 条件是and的关系Q的另外一种用法
#q1 里面的条件都是or的关系
q1=Q()
q1.connector = 'OR'
q1.children.append(('id',1))
q1.children.append(('id',3))
q1.children.append(('id',6))
#q2里面的条件都是or的关系
q2=Q()
q2.connector = 'OR'
q2.children.append(('c',2))
q2.children.append(('c',4))
q2.children.append(('c',6))
#con 通过and的条件把q1和q2 联系到一块
con=Q()
con.add(q1,'AND')
con.add(q2,'AND')Q能把查询相互嵌套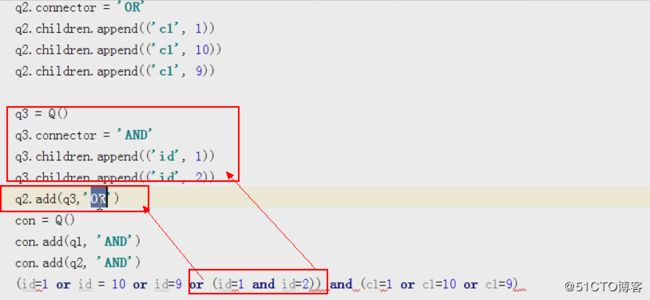
实例应用
组合搜索的时候就可以用到这个Q。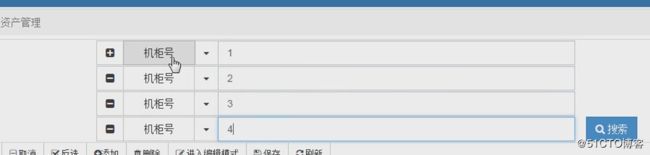
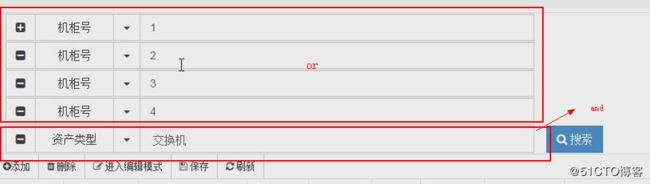
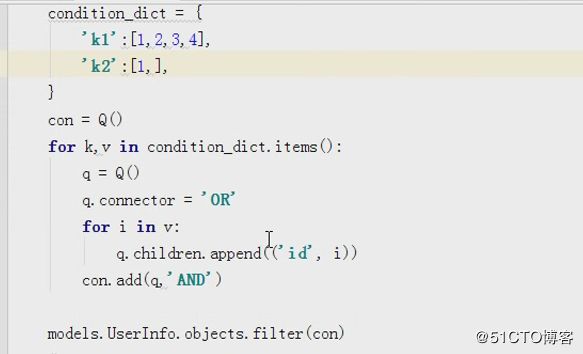
Q用于构造复杂的查询条件的,使用方法有对象方法和直接创建创建对象方法
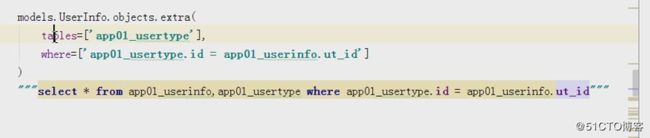
extra
我们的sql语句有下面这样的查询方式,如果用orm应该如何查询那?
"""
select
id,
name,
(select count(1) from tb) as n
from xb
"""orm使用extra的方法来解决上面的问题
models.Uinfo.objects.all().extra(select={
'n':"select count(1) from app01_utype WHERE id=%s or id=%s",
'm':"select count(1) from app01_uinfo WHERE id=%s or id=%s",
},
select_params=[1,2,3,4])这里除了取到了Uinfo里面的所有字段(all方法),还取到了Utype里面的总数。这里也列举了extra里面是可以使用条件查询的,后面的select_params就是传递的值,但是这个值再取的时候是按照顺序开始,第一个%s取值为1,依次类推。
取值的话,就可以加入for循环来查看
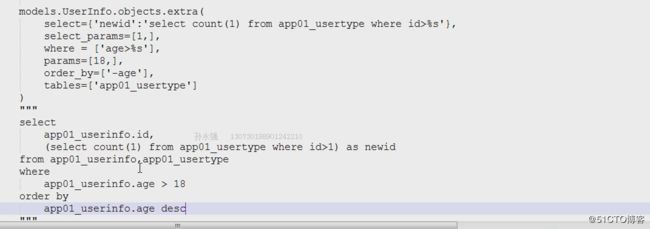
v = models.Uinfo.objects.all().extra(select={
'n':"select count(1) from app01_utype WHERE id=%s or id=%s",
'm':"select count(1) from app01_uinfo WHERE id=%s or id=%s",
},
select_params=[1,2,3,4])
for i in v:
print(i.n,i.m,i.id) # extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
# Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
# Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
# Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])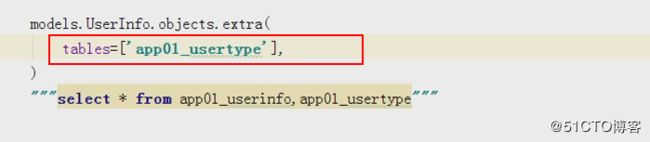
# 执行原生SQL
#
# from django.db import connection, connections
# cursor = connection.cursor() # cursor = connections['default'].cursor()default 是django里面的数据库配置的default,也可以取别的值
# cursor.execute("""SELECT * from auth_user where id = %s""", [1])
# row = cursor.fetchone()其他用法
http://www.cnblogs.com/wupeiqi/articles/6216618.html
##################################################################
# PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET #
##################################################################
def all(self)
# 获取所有的数据对象
def filter(self, *args, **kwargs)
# 条件查询
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询,但是hi排除的,例如id=1,是除了id=1的其他的都要
# 条件可以是:参数,字典,Q
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
model.tb.objects.all().select_related()
model.tb.objects.all().select_related('外键字段')
model.tb.objects.all().select_related('外键字段__外键字段')
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related('外键字段')
from django.db.models import Count, Case, When, IntegerField
Article.objects.annotate(
numviews=Count(Case(
When(readership__what_time__lt=treshold, then=1),
output_field=CharField(),
))
)
students = Student.objects.all().annotate(num_excused_absences=models.Sum(
models.Case(
models.When(absence__type='Excused', then=1),
default=0,
output_field=models.IntegerField()
)))
def annotate(self, *args, **kwargs)
# 用于实现聚合group by查询
from django.db.models import Count, Avg, Max, Min, Sum
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id'))
# SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id')).filter(uid__gt=1)
# SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
v = models.UserInfo.objects.values('u_id').annotate(uid=Count('u_id',distinct=True)).filter(uid__gt=1)
# SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1
def distinct(self, *field_names)
# 用于distinct去重
models.UserInfo.objects.values('nid').distinct()
# select distinct nid from userinfo
注:只有在PostgreSQL中才能使用distinct进行去重
def order_by(self, *field_names)
# 用于排序
models.UserInfo.objects.all().order_by('-id','age')
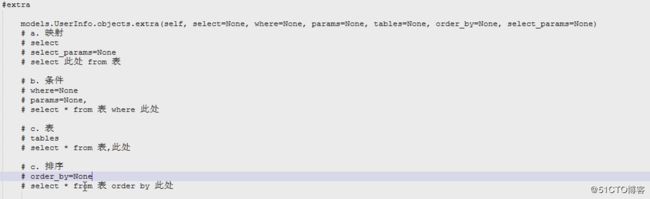
def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"}, select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, select_params=(1,), order_by=['-nid'])
def reverse(self):
# 倒序
models.UserInfo.objects.all().order_by('-nid').reverse()
# 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
def using(self, alias):
指定使用的数据库,参数为别名(setting中的设置)
##################################################
# PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS #
##################################################
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid from 其他表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
################### 原生SQL ###################
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
def dates(self, field_name, kind, order='ASC'):
# 根据时间进行某一部分进行去重查找并截取指定内容
# kind只能是:"year"(年), "month"(年-月), "day"(年-月-日)
# order只能是:"ASC" "DESC"
# 并获取转换后的时间
- year : 年-01-01
- month: 年-月-01
- day : 年-月-日
models.DatePlus.objects.dates('ctime','day','DESC')
def datetimes(self, field_name, kind, order='ASC', tzinfo=None):
# 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间
# kind只能是 "year", "month", "day", "hour", "minute", "second"
# order只能是:"ASC" "DESC"
# tzinfo时区对象
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.UTC)
models.DDD.objects.datetimes('ctime','hour',tzinfo=pytz.timezone('Asia/Shanghai'))
"""
pip3 install pytz
import pytz
pytz.all_timezones
pytz.timezone(‘Asia/Shanghai’)
"""
def none(self):
# 空QuerySet对象
####################################
# METHODS THAT DO DATABASE QUERIES #
####################################
def aggregate(self, *args, **kwargs):
# 聚合函数,获取字典类型聚合结果
from django.db.models import Count, Avg, Max, Min, Sum
result = models.UserInfo.objects.aggregate(k=Count('u_id', distinct=True), n=Count('nid'))
===> {'k': 3, 'n': 4}
def count(self):
# 获取个数
def get(self, *args, **kwargs):
# 获取单个对象
def create(self, **kwargs):
# 创建对象
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
def get_or_create(self, defaults=None, **kwargs):
# 如果存在,则获取,否则,创建
# defaults 指定创建时,其他字段的值
obj, created = models.UserInfo.objects.get_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 2})
def update_or_create(self, defaults=None, **kwargs):
# 如果存在,则更新,否则,创建
# defaults 指定创建时或更新时的其他字段
obj, created = models.UserInfo.objects.update_or_create(username='root1', defaults={'email': '1111111','u_id': 2, 't_id': 1})
def first(self):
# 获取第一个
def last(self):
# 获取最后一个
def in_bulk(self, id_list=None):
# 根据主键ID进行查找
id_list = [11,21,31]
models.DDD.objects.in_bulk(id_list)
def delete(self):
# 删除
def update(self, **kwargs):
# 更新
def exists(self):
# 是否有结果
其他操作