什么值得买:大型比价 / 推送网站
现状
- 网站内信息杂乱,很多商家自荐信息 并无用
- 水军
目标:
爬取数据
存入mongoDB
数据分析
数据挖掘
可视化
构思一个精准定位特价产品的程序
不废话 直接开扒,跳过安装 ,网上很多 教程,这里使用的 windows 安装 scrapy, pycharm IDE
页面:
- 首页: url 管理器 (存放url 遍历用)
- 商品详情页:商品结构化信息,如 (发布时间,产品标签、评论等)
- 爆料者信息页面:爆料者等级 ,是否商家自荐,粉丝数量等 来确定此发布是否有价值
分页规则:http://www.smzdm.com/p + pageNum(页码数)
一、首页

Paste_Image.png
二、详情页面

Paste_Image.png

Paste_Image.png
三、爆料人页面
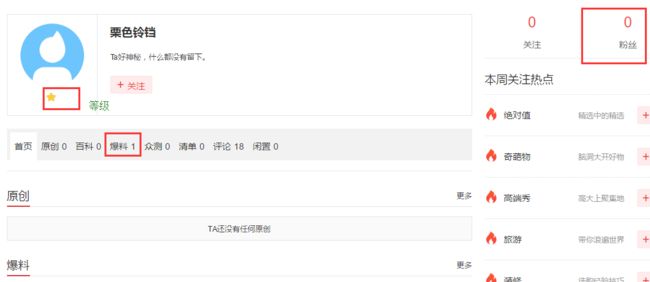
Paste_Image.png
代码
1.新建一个spider (爬虫引擎)
import scrapy
from scrapy.selector import Selector
from first_project.items import smzdmItem
class mySpider(scrapy.Spider): # 继承 spider
name = "smzdm" #名称
初始化方法
def __init__(self,pageNumFrom=1,pageNumTo=None,*args,**kwargs):
start_urls = []
for i in range(int(pageNumFrom),int(pageNumTo)):
start_urls.append('http://www.smzdm.com/p'+ str(i))
self.start_urls = start_urls ## 参数 控制页码
自动调用parse() 接收每个初始url完成下载后生成的 response
def parse(self, response):
selector = Selector(response)
goods = selector.xpath('//ul[@id="feed-main-list"]/li[@class="feed-row-wide "]/h5/a/@href').extract()
num = 0
item_list = []
for href in goods:
num += 1
item = smzdmItem()
#页面规则 li[序列数] 广告位要剔除!!! (元素[@属性名称 = ""][索引值] 并列条件 剔除广告位)
#发布时间
pub_time = selector.xpath('//*[@id="feed-main-list"]/li[@class="feed-row-wide "]['+str(num)+']/div/div[2]/div[3]/div[2]/span/text()').extract_first()
#来源网站
from_web = selector.xpath('//*[@id="feed-main-list"]/li[@class="feed-row-wide "]['+str(num)+']/div/div[2]/div[3]/div[2]/span/a/text()').extract_first()
#购买网址
purchase_url = selector.xpath('//*[@id="feed-main-list"]/li[@class="feed-row-wide "]['+str(num)+']/div/div[2]/div[3]/div[2]/span/a/@href').extract_first()
if self.crawl_today:
if "-" in pub_time:
self.start_urls = []
break
dt = time.strftime('%m-%d', time.localtime(time.time()))
item['pub_time'] = str(dt) + str(pub_time)
item['from_web'] = from_web
item['purchase_url'] = purchase_url
item = scrapy.Request(href, meta={'item': item}, callback=self.parse_dir_cotents) # 递归查询
item_list.append(item)
for a in item_list:
yield a
递归爬取 产品详细页面
def parse_dir_cotents(self,response):
item = response.meta['item']
#标题组成
title = response.xpath('//div[1]/article/div[1]/div[2]/h1/em[1]/text()').extract_first()
price = response.xpath('//div[1]/article/div[1]/div[2]/h1/em[2]/em/text()').extract_first()
title_detail = response.xpath('//div[1]/article/div[1]/div[2]/h1/em[2]/span/text()').extract()
recommender = response.xpath('//div[1]/article/div[1]/div[2]/div/div[1]/span[1]/a/text()').extract()
update_time = response.xpath('//div[1]/div[2]/div/div[1]/span[2]/text()').extract_first()
if update_time is not None:
update_time = update_time.replace("更新时间:","")
# 产品描述 detail_info_
detail_info = response.xpath('//*/p[@itemprop="description"]')
detail_info_text = detail_info.xpath('string(.)').extract()[0] # 获取元素下所有文本
# 商品标签
label = response.xpath('//*/div[@class="meta-tags"]/a/text()').extract()
# 购买链接
purchase_url = response.xpath('//div[1]/article/div[1]/div[2]/div/div[3]/div/a/@href').extract_first()
#评论数量
comment_num = response.xpath('//*[@id="panelTitle"]/span/em/text()').extract_first()
#最新评论 // id = commentTabBlockHot 最热评论
comment_info = response.xpath('//div[@id="commentTabBlockNew"]//span[@itemprop="description"]/text()').extract()
#值不值
worth = response.xpath('// *[ @ id = "rating_worthy_num"]/text()').extract_first()
unworth = response.xpath('//*[@id="rating_unworthy_num"]/text()').extract_first()
#位置导航
position = response.xpath('//div[@class="crumbsCate"]/a/span/text()').extract();
if len(position) > 0:
del position[0]
item['title'] = str(title).strip()
item['price'] = str(price)
item['title_detail'] = str(title_detail[0]).strip()
item['update_time'] = str(update_time)
item['detail_info'] = str(detail_info_text)
item['label'] = str(label)
item['purchase_url'] = str(purchase_url)
item['comment_num'] = comment_num
item['comment_info'] = str(comment_info)
item['worth'] = str(worth).strip()
item['unworth'] = str(unworth).strip()
item['position'] = str(position)
recommender_url = ''
if len(recommender) == 0:
recommender = '商家自荐'
item['recommender'] = recommender
else:
# 通过爆料人 递归到爆料人页面 获取信息
item['recommender'] = recommender[0]
recommender_url = response.xpath('//div[1]/article/div[1]/div[2]/div/div[1]/span[1]/a/@href').extract()
item = scrapy.Request(recommender_url[0], meta={'item': item}, callback=self.recommender_info)
return item
递归爬取 爆料者页面
def recommender_info(self,response):
item = response.meta['item']
level = response.xpath('/html/body/div[1]/div[1]/div[1]/div[1]/div[2]/@title').extract_first()
stars_num = response.xpath('//div[1]/div[2]/div[1]/a[2]/span/text()').extract_first()
#爆料者等级
item['level'] = level
#粉丝数量
item['stars_num'] = stars_num
return item # ps:yield 修改为了 return``
ps
- xpath
"/" 表示绝对路径 如何获取xpath路径 (chrome / 360 同理 、其他没试过)
"//" 表示相对路径 (直接定位到元素级别) - 递归爬取
yield scrapy.Request(recommender_url[0], meta={'item': item}, callback=self.recommender_info)
parm1 = 递归地址 (如详情页面/爆料人页面)
param2 = 对象 (item 对象 页面间的传递)
(item = response.meta['item'] 接收)
param3 = 调用方法
此处是 两级递归
主页面>>详细页面>>爆料者页面
item 类 (对象概念)
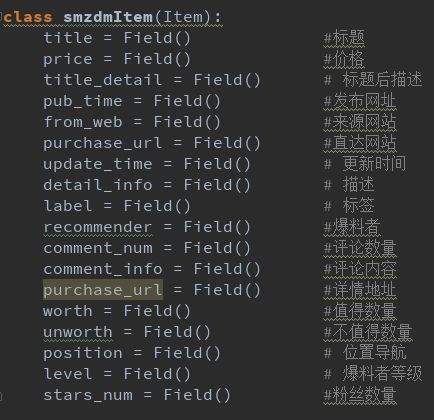
Paste_Image.png
pipelines 管道 (数据出口处理\流出)
def __init__(self):
# 链接数据库
self.client = pymongo.MongoClient(host=settings['MONGO_HOST'], port=settings['MONGO_PORT'])
# 数据库登录需要帐号密码的话
# self.client.admin.authenticate(settings['MINGO_USER'], settings['MONGO_PSW'])
self.db = self.client[settings['MONGO_DB']] # 获得数据库的句柄
self.coll = self.db[settings['MONGO_COLL']] # 获得collection的句柄
print(self.coll)
def process_item(self, item, smzdm):
postItem = dict(item) # 把item转化成字典形式
self.coll.insert(postItem) # 向数据库插入一条记录
return item # 会在控制台输出原item数据,可以选择不写
settings (全局配置)
配置 headers (request 404)
配置 管道 等
BOT_NAME = 'first_project'
SPIDER_MODULES = ['first_project.spiders']
NEWSPIDER_MODULE = 'first_project.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_3) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.54 Safari/536.5'
#mongoDB settings
ITEM_PIPELINES = {
'first_project.pipelines.smzdmPipeline': 300,
}
MONGO_HOST = "127.0.0.1" # 主机IP
MONGO_PORT = 27017 # 端口号
MONGO_DB = "lyx" # 库名
MONGO_COLL = "smzdm" # collection名
# MONGO_USER = "zhangsan"
# MONGO_PSW = "123456"
控制台 执行
scrapy crawl smzdm -o smzdm.json -a pageNumFrom = 1 - a pageNumTo = 100 -s FEED_EXPORT_ENCODING=utf-8'''
-o 存储本地 json文件
-a 参数传递 从第一页 到 一百页
-s 指定编码
--nolog 不显示日志
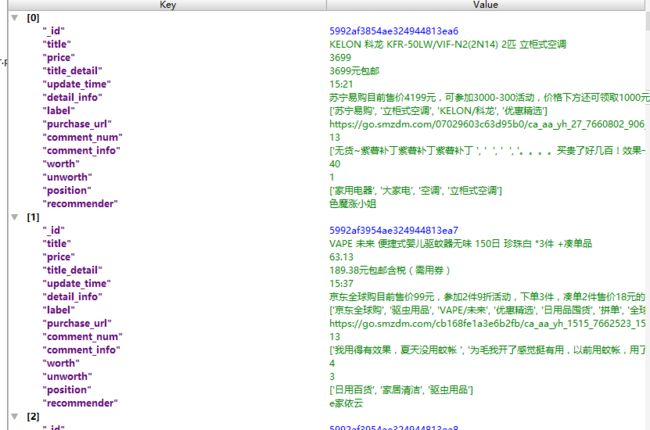
Paste_Image.png
spider 代码处做了修改 ps 已标注(python yield 一定要系统的学习,由于不懂就去使用 导致 递归到第二层 信息存不到item ,改为return修复好)
下一篇 对数据进行处理 并做定时爬取任务