以oracle 11G版本为准进行解析
Data Guard Architecture Overview (Data Guard架构概述)
Data Guard provides the management, monitoring, and automation software to create and maintain one or more synchronized copies of a production database to protect Oracle data from failures, disasters, human error, and data corruptions while providing high availability for mission critical applications. Data Guard is included with Oracle Database Enterprise Edition.
Data Guard提供管理,监视和自动化软件,用于创建和维护生产数据库的一个或多个同步副本,以保护Oracle数据免受故障,灾难,人为错误和数据损坏,同时为关键任务应用程序提供高可用性。 Data Guard包含在Oracle数据库企业版中。
Active Data Guard Functionality Overview (Active Data Guard功能概述)
Active Data Guard is an option license for Oracle Database Enterprise Edition. Active Data Guard enables advanced capabilities that that extend basic Data Guard functionality. These include:
Real-Time Query - offload read-only workloads to an up-to-date standby database
Automatic Block Repair - automatic repair of physical corruption transparent to the user
Far Sync - zero data loss protection across any distance
Standby Block Change Tracking - enable incremental backups on an active standby
Active Data Guard Rolling Upgrade - make it simple to reduce planned downtime
Global Database Services - load balancing and service management across replicated databases. See Global Data Services
Application Continuity - make outages transparent to users. See Application Continuity
Active Data Guard是Oracle数据库企业版的选件许可证。 Active Data Guard支持扩展基本Data Guard功能的高级功能。 这些包括:
实时查询 - 负责将主库最新的数据刷新到物理备库
自动块修复 - 自动修复对坏的数据块进行修复
远程同步 - 任何情况下的主备同步,实现零数据丢失保护。
备库开启块跟踪 - 在备库开启块跟踪,实现备用数据库上启用增量备份。
Active Data Guard滚动升级 - 简化计划停机时间
全局数据库服务 - 跨复制数据库的负载平衡和服务管理。 请参阅 全球数据服务
应用程序连续性 - 使中断对用户透明。 请参阅 应用程序连续性 (应用程序连续性(AC)是Oracle Real Application Clusters(RAC),Oracle RAC One Node和Oracle Active Data Guard选项的一项功能,可通过在可恢复的中断后恢复正在进行的数据库会话来屏蔽最终用户和应用程序的中断。 应用程序连续性通过在中断后恢复受影响的数据库会话的正在进行的工作来屏蔽最终用户和应用程序的中断。 应用程序连续性在应用程序下执行此恢复,以便中断在应用程序中显示为略微延迟的执行。
应用程序连续性用于在处理意外中断和计划维护时改善用户体验。 应用程序连续性增强了使用Oracle数据库的系统和应用程序的容错能力。)
Oracle GoldenGate(OGG):
是一个实现异构IT环境间数据实时数据集成和复制的综合软件包。该产品集支持高可用性解决方案,实时数据集成,事务更改数据捕获,运营和分析企业系统之间的数据复制,转换和验证.Oracle GoldenGate 12 c通过简化配置和管理,加强与Oracle数据库的集成,支持云环境,扩展异构性以及增强安全性,实现了高性能。
除了用于实时数据移动的Oracle GoldenGate核心平台,Oracle还提供了适用于Oracle GoldenGate的管理包(用于Oracle GoldenGate部署的可视化的管理和监视解决方案)和Oracle GoldenGate Veridata(允许在两个正在使用的数据库之间进行高速,海量的比较)。
表格对比总结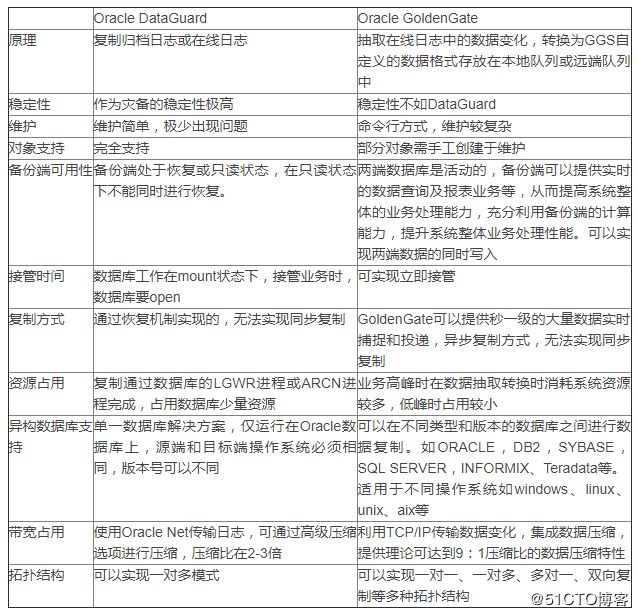
ADG最大的特点还是能做到同步复制,而OGG的数据复制在亚秒级,还是只能算作异步复制。
二、应用场景分析
DG可以用在容灾测试上,在金融、电力、能源行业,生产上常见的容灾架构为ADG,尤其是异地灾备。也有部分较高要求的采用 RAC + ADG,这里的RAC有的是基于存储集群虚拟出来的分布式卷之上做的RAC,有的是通过ASM冗余设计本身实现的。OGG在重大变更需要异构数据库同步数据的场合下或者是数据集中平台上采用。
ADG,最常用的同城,异地灾备解决方案,物理级备份,备机不可写,传输数据为所有redo日志的更改,数据量稍大,不过从以往的使用经验来看,也不太会影响网络,除非应用对网络有很苛刻的要求,即使有,也可以通过vlan或者路由或者多网卡的方法特别建立网络通道,主备库完全一致,缺点是必须全库备份。OGG,DSG这两个是一个类型的,逻辑备份,主要采用特有的技术从联机日志中抽取更改项应用到备库,主备库为两个库,可以全库同步也可以同步单张表或数张表,同步速度较快,传输数据量很少,DML操作和DDL操作均支持。
ADG 同构平台数据同步,OGG可以异构平台数据同步。
ADG 可以通过快照方式保留当前时刻点数据,OGG不能做到。
ADG 直接通过日志重做实现数据复制,OGG是通过对日志加工之后的模式进行数据分析实现复制。
三、 RAC + ADG双活解决方案的难点和关键点是什么?如何解决?
1)针对分布式存储卷架构的仲裁一致性问题
在这个问题上,风险发生的引发点有两个:数据库和集群的仲裁触发以及仲裁过程的时间顺序发生紊乱;资源被1:1割裂之后的默认仲裁策略不一致。也就是说,只要控制这两个引发点,那么这个问题从理论上也就避免了。对于第一个引发点来讲,实际上存储集群的默认仲裁触发时间会是15秒左右,而数据库仲裁触发的控制参数由misscount(默认30秒)这个参数来决定,所以只要我们将misscount这个参数调整到45秒之后,也就是说理论上绝对保障存储集群仲裁在前,而数据库仲裁在后,那么第一个引发点就没有了。对于第二个引发点来讲,假设两站点节点资源对等,仲裁选票同样对等的情况下,存储集群会有一个默认的Winner策略,同样在这种情况下数据库集群也有一个默认仲裁策略:选择实例号小的集群存活。只要我们保证这两个策略结果的一致性,那么第二个引发点也就不存在了。
2)链路稳定状况不可控
这个问题是两种架构都面临的问题。主要表现为两个方面:链路稳定状况不可控;延时指标不可控。因为双中心之间的链路是通过租用运营商的裸光纤链路实现的,那么这其中会经历很多的中继设备及节点。无论从管理上还是从技术把控上都是金融企业自身不可控制的因素。假设双中心间链路延时指标不稳定,也就是说数据库节点之间私网传输的延时会经常出现长延时情况,这势必导致这种延时会加倍放大到数据库节点之间的读写热点竞争上。由于数据库集群之间的数据传输量非常大(缓存、锁、心跳等),在读写热点相对突出的业务上,轻则导致数据库读写性能灾难,重则导致数据库节点直接处于僵死状态。另外,链路的不稳定会导致存储链路频繁切换,甚至会导致集群仲裁频繁发生,这对于业务连续性更是一个灾难。
对于这个问题来讲,就目前金融、电力、能源行业的传统数据架构来讲,并没有一个十足的解决方案。我们只能通过以下措施来减少这种问题带给我们的风险。
i、业务层面需要进行拆分重组:按照IO特点进行合理拆分,将读写业务尽量分布于不同节点上,减少节点间的锁竞争。按照业务将数据库表进行分区,避免在数据库写上的数据热点块儿。例如,对于银行核心系统来讲,尤其是要将批量业务和联机业务区分对待,批量业务的热点以及数据量非常之巨大,所以一定要将批量业务的数据库读写放在单边实现。对于联机业务来讲可以根据热点状况以及链路质量评测结果可以尝试实现双中心同时读写,但是本文建议对于这种重量级的业务还是要从业务层尽量实现应用上的读写分离,或者在应用层双中心部署而在数据库层将数据引到单边来做。
ii、双中心间通讯的整体控制,具体包括对通讯带宽的优先级管理、对通讯的实时监控和控制、对跨中心数据传输的严格策略把控。例如:优先保障存储和数据库通讯的优先级和带宽,严格的规则算法和优先级限定VMOTION、DRS等行为的跨中心随意性,从LTM负载分发上尽可能保障正常情况下纵向IO的单中心效率策略,故障情况下保障跨中心访问的科学性。DWDM上设置双中心间通讯带宽的逻辑隔离以及实时可控。
3)存储网络故障泛滥
这是两种架构都会面临的问题,只是ASM冗余设计架构可能性相对高一些。
如果我们把两个中心的SAN环境整合为一张大网,物理上没有任何隔离的大网,那么可能会因为局部的存储网络故障而波及到整个存储网络。尽管我们通过SAN交换机上的逻辑隔离能够解决大部分的安全问题,但是这样的风险毕竟还是存在的。
所以我们可以通过对数据中心内部SAN环境前后物理隔离,双中心之间靠专一SAN交换机实现存储后端网络的联通来解决该问题。这样的话,单中心内前段SAN环境故障不会波及存储后端,更不会波及整个基础架构的存储网络。
4)串联深度带来的性能问题
这个问题是针对分布式存储卷架构的问题。
架构深度越深,那么IO的性能就会越差,因为IO每经过一层设备就会有一定的延时消耗,纵向深度越深经历的设备越多,那么IO的延时也就越高。如果我们的架构在纵向上越复杂,那么这个问题应该说从本质上是无法消除的,只能通过一定的方法来减少和优化。
从存储层来看,一般存储侧在对物理卷进行虚拟化的时候都会有几种策略。为了增加管理的灵活性及扩展性,虚拟化的时候可能会经过多层映射。另外一种策略是为了提高性能,在虚拟化的时候尽量较少映射。我们在规划存储卷的时候,尽量采用后一种策略。例如VPLEX就会有(1:1map、Raid等策略),我们可以选择1:1map这种策略,仅仅利用它的镜像聚合,而舍弃它的灵活伸缩特性。
四、从RPO和RTO角度来看RAC和ADG
1)从RPO角度来看,RAC方案可以做到理论上的绝对同步。ADG可以做到近似同步,但是一般用在异步场合。
2)从RTO角度来看,RAC方案可以做到理论上的秒级自动故障转移。ADG一般需要人工去实现备库切换,而且需要应用改变连接IP地址,重新启动。
3)从风险角度来看,RAC方案一旦实现距离拉伸,最大的风险在于远距离光纤条件下的节点之间的数据交互。而ADG方案就没有该风险存在。
4)从方案的复杂度来看,RAC方案理论上需要第三点的仲裁,需要双中心二层打通等复杂环境条件。而ADG和OGG方案只需要网络三层可达即可。
5)从投资成本来看,RAC方案实现距离的拉伸之后,需要的环境成本(网络条件、仲裁条件)等都需要较高的成本。ADG和OGG方案没有这些成本。
由此可以看出,实际上从容灾角度考虑(RTO/RPO),那么RAC方案一定是比ADG方案能实现RTO和RPO的更高目标,但是从成本和风险角度考虑,ADG又是最佳的选择。
补充:
Oracle 网络&磁盘心跳机制
网络心跳
网络心跳(Network Hearbeat)是RAC的内部通信机制,每隔一秒钟,CSSD的一个线程(sending进程)发送一个TCP网络心跳包给自己和集群中的其他节点,同时CSSD的另外一个进程(receiving进程)接收到心跳。如果网络传输包被drop或者出现错误,那么TCP的错误纠正机制会重传这个数据包,Oracle在这种场景下不参与网络包的重传。如果一个节点在15秒(50% of misscount)内都接收不到来自其它节点的心跳信息,那么在CSSD日志中会发现关于心跳丢失的“WARNING”信息。同样当该节点在22秒(75% of misscount)以及在27秒(90% of misscount)都没有接收到其他节点的心跳信息时,在CSSD日志中会依次发生警告。一直到30秒(Oracle 默认是30秒,可调节)为心跳丢失的完整周期,该节点会被驱逐。
磁盘心跳
磁盘心跳(Disk Heartbeat)是发生在集群间以及仲裁盘间的心跳。每个RAC节点中的CSSD进程会在仲裁盘(voting disk)上面通过读写方式进行磁盘心跳维护,通过调用操作系统层pread/pwrite进程对1个操作系统block块进行一定偏移量的读写操作。除了维护自己的磁盘心跳(读写磁盘的偏移块),CSSD进程还会监控集群中其他节点CSSD进程维护的磁盘心跳。/这个不断被刷新的数据库头部记录节点名称和计数位,该计数位会在发生心跳探测时被集群中其他节点刷新(通过pwrite)。磁盘心跳是通过CSSD进程维护在心跳盘(vote disk)上面,如果存在某一节点由于IO超时没有刷新磁盘心跳,那么该节点会被宣布死掉。如果一个节点处于未知状态,没有真正的死掉,但是没有在存活的群组里,那么该节点会被驱逐,该节点会被在vote磁盘磁盘上更新为kill,被驱逐掉。
总而言之,网络心跳每秒钟会相互ping一次,集群节点必须在css_miscount(默认值是30s)设置的时间内响应,如果规定时间内未响应,则会导致被驱逐。同时,对于磁盘心跳,每秒钟集群节点会通过vote盘读写进行集群通信,节点必须在disk timeout时间内响应。
补充:基于ASM冗余设计架构实现的数据库双活方案,如何规划ASM?
ASM使用独特的镜像算法:不镜像磁盘,而是镜像盘区。作为结果,为了在产生故障时提供连续的保护,只需要磁盘组中的空间容量,而不需要预备一个热备(hot spare)磁盘。不建议用户创建不同尺寸的故障组,因为这将会导致在分配辅助盘区时产生问题。ASM将文件的主盘区分配给磁盘组中的一个磁盘时,它会将该盘区的镜像副本分配给磁盘组中的另一个磁盘。给定磁盘上的主盘区将在磁盘组中的某个伙伴磁盘上具有各自的镜像盘区。ASM确保主盘区和其镜像副本不会驻留在相同的故障组中。
磁盘组的冗余可以有如下的形式:双向镜像文件(至少需要两个故障组)的普通冗余(默认冗余)和使用三向镜像(至少需要3个故障组)提供较高保护程度的高冗余。 一旦创建磁盘组,就不可以改变它的冗余级别。为了改变磁盘组的冗余,必须创建具有适当冗余的另一个磁盘组,然后必须使用RMAN还原或DBMS_FILE_TRANSFER将数据文件移动到这个新创建的磁盘组。三种不同的冗余方式如下:
1、 外部冗余(external redundancy):表示Oracle不帮你管理镜像,功能由外部存储系统实现,比如通过RAID技术;有效磁盘空间是所有磁盘设备空间的大小之和。
2、 默认冗余(normal redundancy):表示Oracle提供2份镜像来保护数据,有效磁盘空间是所有磁盘设备大小之和的1/2 (使用最多)
3、 高度冗余(high redundancy):表示Oracle提供3份镜像来保护数据,以提高性能和数据的安全,最少需要三块磁盘(三个failure group);有效磁盘空间是所有磁盘设备大小之和的1/3,虽然冗余级别高了,但是硬件的代价也最高。