Part 0 安装
采用Anaconda版本的Python可以直接使用conda install -c scrapinghub scrapy进行安装,采用pip install Scrapy有的环境需要其他的依赖,可能会报错。
Part 1 信息获取
打开番剧索引链接https://www.bilibili.com/anime/index/
F12打开浏览器控制台,inspect in,点到对应的番剧发现信息列表如图,虽然点右键可以复制Xpath,不过这样获得的Xpath经常在Scrapy里面无法获取。这里我们手工来填,就根据属性 class="bangumi-item"就行。(在使用Xpath helper输入Xpath查询之前是不带xh-highlight的,这里是因为插件高亮显示的原因)
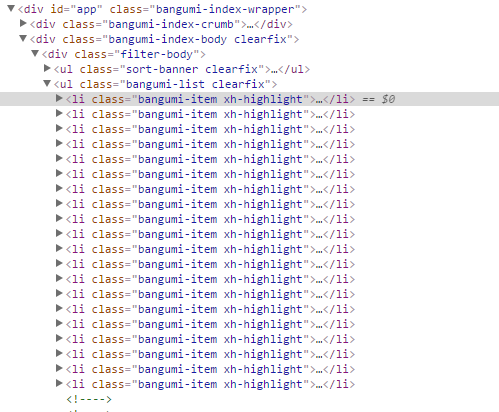
获取结果如下:

由于这里是按追番人数分的,切换到按更新时间和评分分信息又会不一样。再细分一下,各个信息Xpath如下。是否会员观看就没管了…也差不多。
- 标题
//*[@class="bangumi-item"]//*[@class="bangumi-title"] - 人数
//*[@class="bangumi-item"]//*[@class="shadow"] - 集数
//*[@class="bangumi-item"]//*[@class="pub-info"]
命令行测试
这里是在浏览器里面获得的,再来测试一下Scrapy里面能否成功获取。
开cmd输入scrapy shell "https://www.bilibili.com/anime/index",命令行方式测试一下是否能正常获取。
需要注意有的时候因为反爬虫机制不能正确返回Response,查询一下帮助scrapy shell -h,加上-s USER_AGENT='Mozilla/5.0'就可以更改对应的设置,即
scrapy shell "https://www.bilibili.com/anime/index" -s USER_AGENT='Mozilla/5.0'
In [1]: response.xpath('//*[@class="bangumi-item"]//*[@class="bangumi-title"]').extract()
Out[1]: []
获取失败了?再输入view(response),在浏览器里面看一下返回的结果是怎样的。结果发现弹出一个:“没有找到这样的番剧”。是哪里出错了?输入response.text查看一下源代码,发现里面并没有出现具体信息,所以光用这个网址来获得信息是不行的。
API获取
F12里面Network抓包看一下,为了找出是在哪里出现了具体信息,我们需要在Response里面批量搜索,比如追番人数391.9。按照网上的方法,点右键先把抓下来的包存成har,然后搜索391.9
出现在4527行

它的
request请求格式出现在与之最近的
4124行
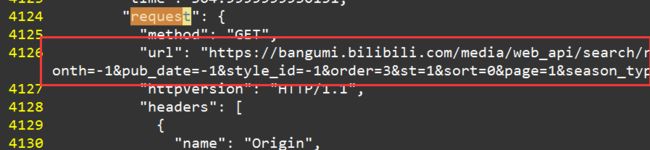
https://bangumi.bilibili.com/media/web_api/search/result?season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&pub_date=-1&style_id=-1&order=3&st=1&sort=0&page=1&season_type=1
网址扔到浏览器里面看一下,到了最后还是成了API的形式…

API格式分析
几个关键的如下:
- sort 0降序排列 1升序排列
- order 3 追番人数排列 0更新时间 4最高评分 2播放数量 5开播时间
- page 控制返回的Index
-
pagesize 20为默认,和网页上的一致 不过最多也就25
剩下的属性和网页右侧的筛选栏一致,大概也能猜出来了。
番剧详细信息获取与调试
网址详细信息在
https://www.bilibili.com/bangumi/media/md102392
这里的102392就是上一步返回的media_id
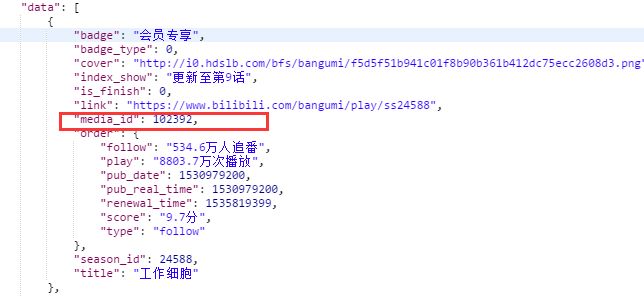
需要注意有的番剧有付费信息,有的没有;有的人数不够,没有评分信息。比如下面这个就没有
badge
badge_type等信息
{'cover': 'http://i0.hdslb.com/bfs/bangumi/152c536f8ecaad8f3d7d568d33da81c963a4a722.png',
'index_show': '全12话',
'is_finish': 1,
'link': 'https://www.bilibili.com/bangumi/play/ss23850',
'media_id': 78352,
'order': {'follow': '202.4万人追番',
'play': '4704.6万次播放',
'pub_date': 1522944000,
'pub_real_time': 1522944000,
'renewal_time': 1532966400,
'score': '9.6分',
'type': 'follow'},
'season_id': 23850,
'title': '超能力女儿'}
不过对详细信息来说就不再是API形式返回的了,用我们最开头失败了的Xpath方法来获取。方法还是差不多,我就直接列结果了。
- Tags
//*[@class="media-tag"]/text() - 简介
//*[@name="description"]/attribute::content
有一点比较奇怪,在网页里面审查元素,Staff表 //*[@class="mic-evaluate"] 第一个元素为声优表 第二个为编剧等Staff表
然而,Scrapy命令行里面测试一下
In [5]: response.xpath('//*[@class="media-tag"]/text()').extract()
Out[5]: ['搞笑', '战斗', '日常', '声控', '漫改']
Tags 简介是没问题的,Staff就获取不到了。response.text查看一下,果然Scrapy和浏览器打开的不一样,发现CV表和Staff表在一大串json里面(执行text=response.xpath('//script')[4].extract()得到),太多了就不贴了,非常详细,还包括评论、每集的标题等等,用正则表达式提出来好了。
In [66]: actor_p=re.compile('actors":(.*?),')
In [67]: re.findall(actor_p,text)
Out[67]: ['"扎克:冈本信彦\\n蕾:千菅春香\\n丹尼:樱井孝宏\\n艾迪:藤原夏海\\n凯西:伊濑茉莉也"']
In [71]: ratings_count_p=re.compile('count":(.*?),')
In [72]: re.findall(ratings_count_p,text)
Out[72]: ['20853']
n [73]: staff_p=re.compile('staff":(.*?),')
In [74]: re.findall(staff_p,text)
Out[74]: ['"原作:真田まこと\\n监督:铃木健太郎\\n系列构成:藤冈美畅\\n角色设计&总作画监督:松元美季\\n美术监督:魏斯曼(スタジオちゅーりっぷ)\\n色彩设计:田边香奈\\n摄影监督:高桥昭裕\\n编集:近藤勇二(Real-T)\\n音响监督:岩浪美和\\n 音响效果:小山恭正\\n音乐:ノイジークローク\\n音乐制作:Lantis\\n动画制作:J.C.STAFF\\n制作:「杀戮天使」制作委员会"']
Part 2 爬虫编写
本次编写一个仅用于分析文本数据、不下载番剧封面图片的爬虫。
命令行下输入scrapy startproject bilibili,Pycharm新建Project,打开该目录。
items.py定义要爬的字段,我自己定义的列在文末。
spider文件夹下新建一个bilibili_spider.py,用来定义具体的行为。比较麻烦的是API每页包含20个子页面,API中还有这20个番剧的信息,并且需要根据API来判断是否把所有番剧爬完了。
这些爬取行为的问题可以参考如下文章:
Scrapy框架之带有分页的详情页面抓取
Scrapy研究探索(五)——自动多网页爬取(抓取某人博客所有文章)
Scrapy中的scrapy.Spider.parse()如何被调用?
如何获取http://a.com中的url,同时也获取http://a.com页面中的数据?
可以直接在parse方法中将request和item一起“返回”,并不需要再指定一个parse_item例如:
def parse(self, response):
#do something
yield scrapy.Request(url, callback=self.parse)
#item[key] = value
yield item
如果想使用-o out.csv输出,需要注意设定编码,在设置settings.py中添加一行
FEED_EXPORT_ENCODING = 'utf-8'
然后启动爬虫scrapy crawl bilibili -o out.csv,虽然用Excel打开仍然是乱码,但是记事本打开就是正常的了。这是因为Excel是ANSI编码,记事本另存为该编码就好。
最终效果如图,后续就可以对分数、CV、类型等等进行分析了。

附
items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BilibiliItem(scrapy.Item):
# define the fields for your item here like:
badge= scrapy.Field()
badge_type= scrapy.Field()
is_finish= scrapy.Field()
media_id= scrapy.Field()
index_show= scrapy.Field()
follow= scrapy.Field()
play= scrapy.Field()
pub_date= scrapy.Field()
pub_real_time= scrapy.Field()
renewal_time= scrapy.Field()
score= scrapy.Field()
season_id= scrapy.Field()
title = scrapy.Field()
tags= scrapy.Field()
brief= scrapy.Field()
cv= scrapy.Field()
staff= scrapy.Field()
count= scrapy.Field()
pass
bilibili_spider.py
import scrapy
import logging
from scrapy import Request
from bilibili.items import BilibiliItem
import re
import json
class MySpider(scrapy.Spider):
name = 'bilibili'
allowed_domains = ['bilibili.com']
url_head = 'https://bangumi.bilibili.com/media/web_api/search/result?season_version=-1&area=-1&is_finish=-1©right=-1&season_status=-1&season_month=-1&pub_date=-1&style_id=-1&order=3&st=1&sort=0&season_type=1'
start_urls = [url_head+"&page=1"]
# 先处理列表中的番剧信息
def parse(self, response):
self.log('Main page %s' % response.url,level=logging.INFO)
data=json.loads(response.text)
next_index=int(response.url[response.url.rfind("=")-len(response.url)+1:])+1
if(len(data['result']['data'])>0):
# 发出Request 处理下一个网址
next_url = self.url_head+"&page="+str(next_index)
yield Request(next_url, callback=self.parse)
medias=data['result']['data']
for m in medias:
media_id=m['media_id']
detail_url='https://www.bilibili.com/bangumi/media/md'+str(media_id)
yield Request(detail_url,callback=self.parse_detail,meta=m)
# 再处理每个番剧的详细信息
def parse_detail(self, response):
item = BilibiliItem()
item_brief_list=['badge','badge_type','is_finish','media_id','index_show','season_id','title']
item_order_list=['follow','play','pub_date','pub_real_time','renewal_time','score']
m=response.meta
for key in item_brief_list:
if (key in m):
item[key]=m[key]
else:
item[key]=""
for key in item_order_list:
if (key in m['order']):
item[key]=m['order'][key]
else:
item[key]=""
tags=response.xpath('//*[@class="media-tag"]/text()').extract()
tags_string=''
for t in tags:
tags_string=tags_string+" "+t
item['tags']=tags_string
item['brief'] = response.xpath('//*[@name="description"]/attribute::content').extract()
detail_text = response.xpath('//script')[4].extract()
actor_p = re.compile('actors":(.*?),')
ratings_count_p = re.compile('count":(.*?),')
staff_p = re.compile('staff":(.*?),')
item['cv'] = re.findall(actor_p,detail_text)[0]
item['staff'] = re.findall(staff_p,detail_text)[0]
count_list=re.findall(ratings_count_p,detail_text)
if(len(count_list)>0):
item['count'] = count_list[0]
else:
item['count']=0
# self.log(item)
return item