转载自:https://www.douban.com/doulist/3440234/
学习Coursera 上台湾国立大学的《机器学习基石》
https://class.coursera.org/ntumlone-001/

第一讲:台湾国立大学的《机器学习基石》
一,什么是机器学习?
使用Machine Learning 方法的关键:
1, 存在有待学习的“隐含模式”
2, 该模式不容易准确定义(直接通过程序实现)
3, 存在关于该模式的足够数据

这里的f 表示理想的方案,g 表示我们求解的用来预测的假设。H 是假设空间。
通过算法A, 在假设空间中选择最好的假设作为g。
选择标准是 g 近似于 f。

上图增加了"unknown target function f: x->y“, 表示我们认为训练数据D 潜在地是由理想方案f 生成的。
机器学习就是通过DATA 来求解近似于f 的假设g。
二, 机器学习与数据挖掘、人工智能、统计学的关系
1, Machine Learning vs. Data Mining
数据挖掘是利用(大量的)数据来发现有趣的性质。
1.1 如果这里的”有趣的性质“刚好和我们要求解的假设相同,那么ML=DM。
1.2 如果”有趣的性质“和我们要求的假设相关,那么数据挖掘能够帮助机器学习的任务,反过来,机器学习也有可能帮助挖掘(不一定)。
1.3 传统的数据挖掘关注如果在大规模数据(数据库)上的运算效率。
目前来看,机器学习和数据挖掘重叠越来越多,通常难以分开。
2, Machine Learning vs. Artificial Intelligence(AI)
人工智能是解决(运算)一些展现人的智能行为的任务。
2.1 机器学习通常能帮助实现AI。
2.2 AI 不一定通过ML 实现。
例如电脑下棋,可以通过传统的game tree 实现AI 程序;也可以通过机器学习方法(从大量历史下棋数据中学习)来实现。
3,Machine Learning vs. Statistics
统计学:利用数据来做一些位置过程的推断(推理)。
3.1 统计学可以帮助实现ML。
3.2 传统统计学更多关注数学假设的证明,不那么关心运算。
统计学为ML 提供很多方法/工具(tools)。
第二讲: Perceptron-感知机 (台湾国立大学机器学习基石)
Learning to Answer Yes/No (二值分类)
一, Perceptron
x = (x1, x2, ..., xd) ---- features
w = (w1, w2, ..., wd) ---- 未知(待求解)的权重
对于银行是否发送信用卡问题:

perceptron 假设:

sign 是取符号函数, sign(x) = 1 if x>0, -1 otherwise
向量表示:

感知机(perceptron)是一个线性分类器(linear classifiers)。
线性分类器的几何表示:直线、平面、超平面。
二, Perceptron Learning Algorithm (PLA)
感知机求解(假设空间为无穷多个感知机;注意区分下面的普通乘法和向量内积,内积是省略了向量转置的表示,因为豆瓣不支持公式。。。)
初始w = 0 (零向量)。
第一步:找一个分错的数据(xi, yi), sign(w*xi) != yi;
第二步:调整w 的偏差,w = w + yi*xi;
循环第一、二步,直到没有任何分类错误, 返回最后得到的w。
实际操作时,寻找下一个错误数据可以按照简单的循环顺序进行(x1, x2, ..., xn);如果遍历了所有数据没有找到任何一个错误,则算法终止。注:也可以预先计算(如随机)一个数据序列作为循环顺序。
以上为最简单的PLA 算法。没有解决的一个基本问题是:该算法不一定能停止!
三, PLA 算法是否能正常终止
分两种情况讨论:数据线性可分;数据线性不可分。

注意PLA 停止的条件是,对任何数据分类都正确,显然数据线性不可分时PLA 无法停止,这个稍后研究。
1, 我们先讨论线性可分的情况。
数据线性可分时,一定存在完美的w(记为wf), 使得所有的(xi, yi), yi = sign(wf*xi).
可知:

下面证明在数据线性可分时,简单的感知机算法会收敛。

而且量向量夹角余弦值不会大于1,可知T 的值有限。由此,我们证明了简单的PLA 算法可以收敛。
四,数据线性不可分:Pocket Algorithm
当数据线性不可分时(存在噪音),简单的PLA 算法显然无法收敛。我们要讨论的是如何得到近似的结果。
我们希望尽可能将所有结果做对,即:

寻找wg 是一个NP-hard 问题!
只能找到近似解。
Pocket Algorithm

与简单PLA 的区别:迭代有限次数(提前设定);随机地寻找分错的数据(而不是循环遍历);只有当新得到的w 比之前得到的最好的wg 还要好时,才更新wg(这里的好指的是分出来的错误更少)。
由于计算w 后要和之前的wg 比较错误率来决定是否更新wg, 所以pocket algorithm 比简单的PLA 方法要低效。
最后我们可以得到还不错的结果:wg。
第三讲: 机器学习的分类学 (台湾国立大学机器学习基石)
机器学习方法的分类学,通过不同的分类标准来讨论。
一,根据输出空间来分类。
1, 分类(classification)
1.1 二值分类 (binary classification):输出为 {+1, -1}。
1.2 多值分类 (multiclass classification):输出为有限个类别,{1, 2, 3, ... , K}
2, 回归(regression)
输出空间:实数集 R , 或 区间 [lower, upper]
3, 结构学习(structured learning):典型的有序列化标注问题
输出是一个结构(如句子中每个单词的词性), 可以成为 hyperclass, 通常难以显示地定义该类。
需要重点研究的是二值分类和回归。
二, 根据数据标签(label) 情况来分类。
1, 有监督学习(supervised learning):训练数据中每个xi 对应一个标签yi。
应用:分类
2, 无监督学习(unsupervised learning):没有指明每个xi 对应的是什么,即对x没有label。
应用:聚类,密度估计(density estimation), 异常检测。
3, 半监督学习(semi-supervised learning):只有少量标注数据,利用未标注数据。
应用:人脸识别;医药效果检测。
4, 增强学习(reinforcement learning):通过隐含信息学习,通常无法直接表示什么是正确的,但是可以通过”惩罚“不好的结果,”奖励“好的结果来优化学习效果。
应用:广告系统,扑克、棋类游戏。
总结:有监督学习有所有的yi;无监督学习没有yi;半监督学习有少量的yi;增强学习有隐式的yi。
三, 根据不同的协议来分类。
1, 批量学习 - Batch learning
利用所有已知训练数据来学习。
2, 在线学习 - online learning
通过序列化地接收数据来学习,逐渐提高性能。
应用:垃圾邮件, 增强学习。
3, 主动学习 - active learning
learning by asking:开始只有少量label, 通过有策略地”问问题“ 来提高性能。
比如遇到xi, 不确定输出是否正确,则主动去确认yi 是什么,依次来提高性能。
四, 通过输入空间来分类。
1, 离散特征 - concrete features
特征中通常包含了人类的智慧。例如对硬币分类需要的特征是(大小,重量);对信用分级需要的特征是客户的基本信息。这些特征中已经蕴含了人的思考。
2, 原始特征 - raw features
这些特征对于学习算法来说更加困难,通常需要人或机器(深度学习,deep learning)将这些特征转化为离散(concrete)特征。
例如,数字识别中,原始特征是图片的像素矩阵;声音识别中的声波信号;机器翻译中的每个单词。
3, 抽象特征 - abstract features
抽象特征通常没有任何真实意义,更需要认为地进行特征转化、抽取和再组织。
例如,预测某用户对电影的评分,原始数据是(userid, itemid, rating), rating 是训练数据的标签,相当于y。这里的(userid, itemid)本身对学习任务是没有任何帮助的,我们必须对数据所进一步处理、提炼、再组织。
总结:离散特征具有丰富的自然含义;原始特征有简单的自然含义;抽象特征没有自然含义。
原始特征、抽象特征都需要再处理,此过程成为特征工程(feature engineering),是机器学习、数据挖掘中及其重要的一步。离散特征一般只需要简单选取就够了。

第四讲:学习的可行性分析 (台湾国立大学机器学习基石)
机器学习的可行性分析。
一, 第一条准则: 没有免费的午餐!(no free lunch !)
给一堆数据D, 如果任何未知的f (即建立在数据D上的规则)都是有可能的,那么从这里做出有意义的推理是不可能的!! doomed !!
如下面这个问题无解(或者勉强说没有唯一解):
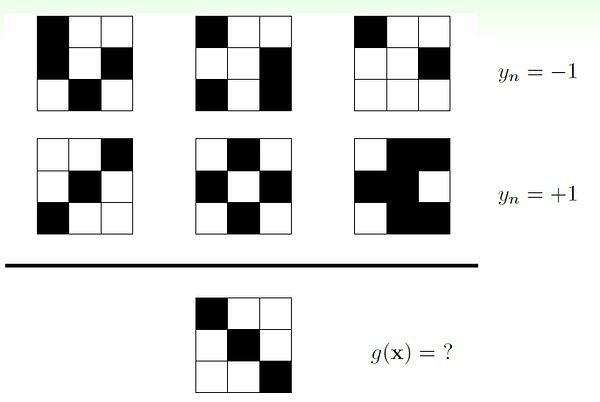
下面这题也是如此:

再来看个”大神“的例子:
已知 (5, 3, 2) => 151022, 求 (7, 2, 5) => ?
鬼才知道!! 即使给你更多已知数据也白搭!因为有多种自造的规则可以解释已知数据。
瞬间感觉小学中学做过的好多题(尤其是奥赛类的)都是扯淡的有木有!!不同的理解就会有不同的答案。
如何解决上述存在的问题? 答:做出合理的假设。
二, 关于罐子里选小球的推论(概论&统计)
这里主要去看原课件吧。
比较重要的一个霍夫丁不等式(Hoeffding’s Inequality) 。

这里v 是样本概率;u 是总体概率。
三,罐子理论与学习问题的联系

对于一个固定的假设h, 我们需要验证它的错误率;然后根据验证的结果选择最好的h。

四,Real Learning
面对多个h 做选择时,容易出现问题。比如,某个不好的h 刚好最初的”准确“ 的假象。
随着h 的增加,出现这种假象的概率会增加。
发生这种现象的原因是训练数据质量太差。

对于某个假设h, 当训练数据对于h 是BAD sample 时, 就可能出现问题。
因此,我们希望对于我们面对的假设空间,训练数据对于其中的任何假设h 都不是BAD sample。
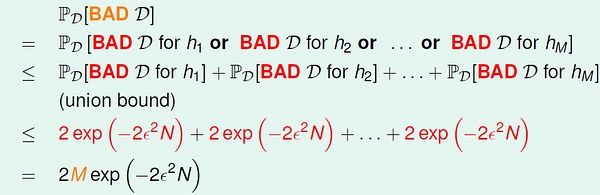
所以,当假设空间有限时(大小为M)时, 当N 足够大,发生BAD sample 的概率非常小。
此时学习是有效的。
当假设空间无穷大时(例如感知机空间),我们下一次继续讨论。(提示:不同假设遇到BAD sample 的情况会有重叠)
第五讲: 学习的可行性分析(一些概念和思想) (台湾国立大学机器学习基石)
Training versus Testing
1,回顾:学习的可行性?
最重要的是公式:
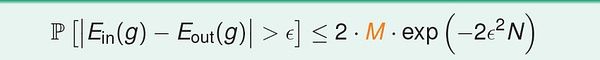
(1) 假设空间H有限(M),且训练数据足够大,则可以保证测试错误率Eout 约等于训练错误率Ein;
(2)如果能得到Ein 接近于零,根据(1),Eout 趋向于零。
以上两条保证的学习的可能性。
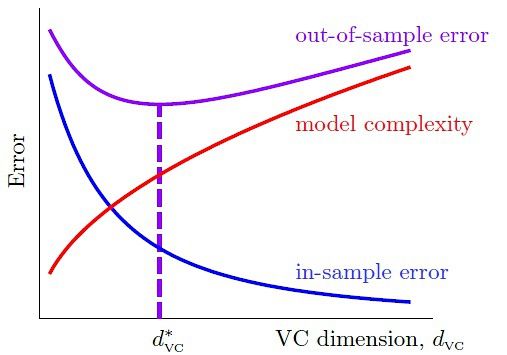
可知,假设空间H 的大小M 至关重要,我们接下来会力求找一个H 大小的上界。
M存在重要的trade-off 思想:
(1)当M 很小,那么坏数据出现的概率非常小(见第四讲分析),学习是有效的;但是由于假设空间过小,我们不一定能找到一个方案,可以使训练误差接近零;
(2)反之,若M 很大,坏数据出现的概率会变大。
若假设空间无限大(比如感知机),学习一定是无效的吗?这门在下面力图回答这个问题。
2, 假设空间H 大小:M
根据上面的公式,当M 无限大时是无法有效学习的;主要是我们在计算M 是通过UNION BOUND 的方式,这样得到的上界太宽松了;实际上,由于不同假设下发生坏事情是有很多重叠的,其实我们可以得到比M小得多的上界。
我们希望将这么多的假设进行分组,根据组数来考虑假设空间大小。
接下来的讨论需要脑子转个弯儿,去看台大林轩田的视频和讲义应该更清楚些,我这里解释的看不懂没关系~
后面的讨论都是针对批量的二值分类问题。
这个思想的关键是,我们从有限个输入数据的角度来看待假设的种类。
(1)最简单的情形,只有一个输入数据时,我们最多只有两种假设:h1(x) = +1 or h2(x) = -1 。
(2)输入数据增加到两个,最多可以有四种假设:
h1(x1)=1, h1(x2)=1;
h2(x1)=-1, h2(x2)=1;
h3(x1)=1, h3(x2)=-1;
h4(x1)=-1, h4(x2)=-1.
依次类推, 对于k 个输入数据,最多有2^k 种假设。
上面阐述的是理想、极端情况,实际上,在实际学习中我们得不到如此之多的假设。例如,对于2维感知机(输入为平面上的点),输入数据为3个时,下面这种假设是不存在的:

(圆圈和叉代表两种不同分类,这种情形也就是线性不可分)。
我们尝试猜测,当k 很大时,有效假设的数量远小于 2^k ?
定义"dichotomy": hypothesis 'limited' to the eyes if x1, x2, ..., xn
也就是相当于我们前面描述的,从输入数据的角度看,有效假设的种类。
输入规模为N时,dichotomies 的一个宽的上界是 2^N.
后面这部分内容,如果想理解清楚,还是建议看林轩田的讲解。:-)
定义关于数据规模N 的生长函数(growth function):数据规模为N 时,可能的dichotomy 的数量,记为m(N)。
下面列举几种生长函数:
(1)X=R(一维实数空间),h(x) = sign(x-a), a 是参数。
它的生长函数: m(N) = N + 1 ; 当N > 1时,m(N) < 2^N
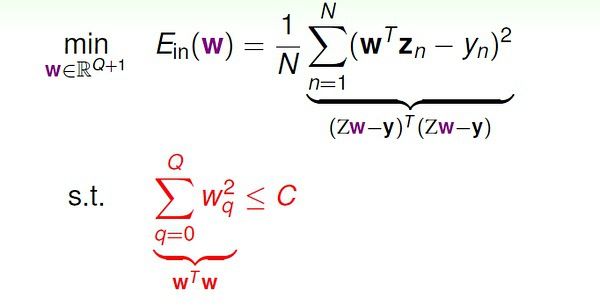
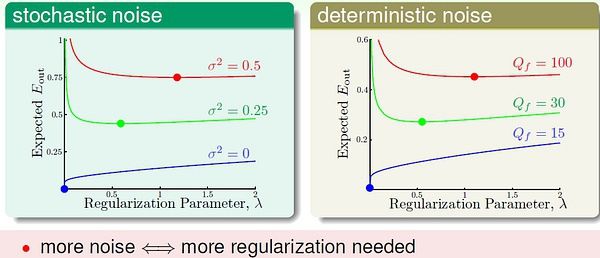
(2)X=R, h(x) = 1 iff x>=a or x 它的生长函数:m(N) = 0.5N^2 + 0.5N + 1; 当 N>2 时, m(N) < 2^N (3)X=R^2(二维实数空间),h是一个任意凸多边形,多边形内部的为1,外部的为-1。 它的生长函数:m(N) = 2^N 我们引入一个重要概念:突破点(break point):对于某种假设空间H,如果m(k)<2^k, 则k 是它的突破点。 对于上面提到的三个例子,(1)的突破点是2,3,4... (2)的图破点是3,4,... (3)没有突破点。 注意:如果k 是突破点,那么k+1, k+2, ... 都是突破点。 对于感知机,我们不知道它的生长函数,但是我们知道它的第一个突破点是4, m(4)=14 < 16 对于后面的证明,突破点是一个很重要的概念。 第六讲: 归纳理论(台大机器学习) 这一讲开篇再介绍一个界函数(bounding function)的概念:是指当(最小)突破点为k 时,生长函数m(N) 可能的最大值,记为B(N, k)。 显然,当k=1时,B(N, 1) = 1; 当k > N 时,B(N,k) = 2^N; 当k = N 时,B(N,k)=2^N - 1. 于是很容易得到Bounding function table: 需要重点考虑 k < N 的情况。 林轩田在课程中是通过图示的方法来猜想可能的递推不等式,没有严谨证明。 我这里根据林老师的图示进一步理解下,希望能给出一个相对更严谨的解释。 我们考虑B(4, 3),对应的数据量是4 (x1, x2, x3, x4),从这四个数据的角度看应该有B(4,3)个有效的dichotomies。 如果我们遮住其中一个 数据(比如x4),余下的dichotomies去重后,不超过B(3,3) 个。(否则就违背了突破点在3)。显然, B(4,3) <= 2 * B(3,3)。 也就是说,当扩展为(x1,x2,x3,x4)时,(x1,x2,x3)上的dichotomies 只有部分被重复复制了(最多一次)。 于是可以设 被复制的dichotomies 数量为a,未被复制的数量为b。(0 <= a,b <= B(3,3) ) 可以知道,B(3,3) = a+b; B(4,3) = 2*a + b. 我们假设a > B(3,2),这样,当扩展到(x1,x2,x3,x4) 时,有大于B(3,2) 的(x1,x2,x3) 上的dichotomies 被复制。此时在(x1,x2,x3) 中一定能够找到两个点被打散(shatter)而且被复制了,由于被复制,对月这些dichotomies,x4可以取两个不同类别的值,因此在(x1,x2,x3,x4) 中一定能找到3个点被打散了。这与"3"是突破点相违背。假设不成立,所以a <= B(3,2)。 所以,我们得到:B(4,3) = 2*a + b <= B(3,3) + B(3,2). 对于任意N > k, 利用上述思路,可以证明 B(N,k) <= B(N-1, k) + B(N-1,k-1). 有了递推不等式,通过数学归纳法,我们证明下面的Bounding Function (N > k) : 这个式子显然是多项式的,最高次幂是 k-1。 所以我们得到结论:如果突破点存在(有限的正整数),生长函数m(N) 是多项式的。 既然得到了m(N) 的多项式上界,我们希望对之前的不等式(如下图)中M 进行替换。 然而直接替换是存在问题的,具体解释和替换方法这里不多说了,可以去看林老师的课程。主要问题就是Eout(h),out 的空间是无穷大的,通过将Eout 替换为验证集(verification set) 的Ein' 来解决这个问题。最后我们得到下面的VC bound: VC 界是机器学习中很重要的理论基础,我们在后面还会对VC 维有详细解释。 到了这里,我们可以说,2维感知机的学习是可行的! 这一阶段大功告成! :-) 上一讲的最后得到了VC bound,这一讲对VC维理论进行理解,这是机器学习(最)重要的理论基础。 我们先对前面得到的生长函数和VC bound 做一点小的修改。 1,VC 维的定义 VC Demension: 对于假设空间H,满足生长函数m(N) = 2^N 的最大的N, 记为dvc(H). 可知,dvc(H) 比H 的最小突破点k 小1,即 dvc(H) = k-1. 2维感知机的VC维是3. 2,感知机的VC维 我们已经知道,2维感知机的VC维是3. 对于d 维感知机,我们猜测它的VC 维是 d+1 ? 对此,我们只要证明 dvc >= d+1 && dvc <= d+1. (1) 证明 dvc >= d+1 对于d 维空间的任意输入数据x1, 都增加一个分量x10, 取值恒为1. 即 x1 = (1, x11, x12, ... , x1d)。 (x1 是一个向量) 取组特殊的输入数据: 对于上面的d+1 个输入数据,我们可以求得向量w : 也就是说,这样的d+1 个输入数据可以被d 维感知机打散(shattered), 所以有 dvc >= d+1. (2) 证明 dvc <= d+1 对于d 维空间的输入数据: 也就是说,不可能存在d+2 个线性独立的输入数据。其中,线性组合中的系数可能为正、负或零,但是不全为零。 等式两边都乘以 w 向量: 假设这d+2 个数据都可以被打散。那么我们可以对 wx 随意取值(-1 或 +1),上式都应该能够满足。然而,对于这样的情况:当系数a 为正数时,wx 取+1,反之w*x 取-1,式子右边一定大于0;此时式子左边就无法取-1,与假设矛盾。 所以d 维感知机无法打散 d+2 个点,也就是说VC 维最大只能是 d+1. 综合(1)(2),证得 dvc = d+1. 3,VC 维的物理意义 VC维可以反映假设H 的强大程度(powerfulness),VC 维越大,H也越强,因为它可以打散更多的点。 通过对常见几种假设的VC 维的分析,我们可以得到规律:VC 维与假设参数w 的自由变量数目大约相等。 例如,对于2维感知机,w = (w0, w1, w2),有三个自由变量,dvc = 3. 4,VC 维的解释 VC 维反映了假设H 的强大程度,然而VC 维并不是越大越好。 通过一些列数学推导,我们得到: 上面的”模型复杂度“ 的惩罚(penalty),基本表达了模型越复杂(VC维大),Eout 可能距离Ein 越远。 下面的曲线可以更直观地表示这一点: 模型较复杂时(dvc 较大),需要更多的训练数据。 理论上,数据规模N 约等于 10000dvc(称为采样复杂性,sample complexity);然而,实际经验是,只需要 N = 10dvc. 造成理论值与实际值之差如此之大的最大原因是,VC Bound 过于宽松了,我们得到的是一个比实际大得多的上界。 即便如此,VC Dimension & VC bound 依然是分析机器学习模型的最重要的理论工具。 当我们面对的问题不是完美的(无噪音)二值分类问题,VC 理论还有效吗? 1,噪音和非确定性目标 几种错误:(1) noise in y: mislabeled data; (2) noise in y: different labels for same x; (3) noise in x: error x. 将包含噪音的y 看作是概率分布的,y ~ P(y|x)。 学习的目标变为预测最有可能出现的y,max {P(y|x)}。 2, 错误的测量 (error measure) 对错误不同的测量方法将对学习过程有不同的指导。 如下面的0/1 error 和 squared error. 我们在学习之前,需要告诉模型我们所关心的指标或衡量错误的方法。 3,衡量方法的选择 图中的false accept 和 false reject 就是我们在分类中常说的 false positive 和 false negative,只是台湾和大陆的叫法不同而已。 采用0/1 error 时,对于每种错误,都会有相同程度的惩罚(panalize)。 然而,在实际应用中,两种错误带来的影响可能很不一样。 例如(讲义中的例子),一个商场对顾客进行分类,老顾客可以拿到折扣,新顾客没有折扣;这时,如果发生false reject(将老顾客错分为新顾客)而不给其打折,那么会严重影响用户体验,对商家口碑造成损失,影响较坏;而如果发生false accept (将新顾客错分为老顾客)而给其打折,也没什么大不了的。 另一个例子,CIA 的安全系统身份验证,如果发生false accept(将入侵者错分为合法雇员),后果非常严重。 通过上述两个例子,我们知道,对于不同application,两类错误的影响是完全不同的,因此在学习时应该通过赋予不同的权重来区分二者。比如对于第二个例子,当发生false accept : f(x)=-1, g(x)=+1, 对Ein 加一个很大的值。 Just remember: error is application/user-dependent. 4,带权重的分类 依然是借助CIA 身份验证的例子来说明什么是weighted classification: 通过感知机模型解决CIA 分类问题。如果数据时线性可分的,那么带权重与否对结果没有影响,我们总能得到理想结果。 如果输入数据有噪音(线性不可分),像前面学习感知机时一样,采用Pocket 方法,然而计算错误时对待两种错误(false reject/false accept) 不再一视同仁,false acceot 比false reject 严重1000倍。通过下面方法解决: 即,在训练开始前,我们将{(x,y) | y=-1} 的数据复制1000倍之后再开始学习,后面的步骤与传统的pocket 方法一模一样。 然而,从效率、计算资源的角度考虑,通常不会真的将y=-1 的数据拷贝1000倍,实际中一般采用"virtual copying"。只要保证: randomly check -1 example mistakes with 1000 times more probability. (这句大家还是看英文比较好,以免理解有歧义) 总之,我们选择好适合特定应用的error measure: err,然后在训练时力求最小化err,即,我们要让最后的预测发生错误的可能性最小(错误测量值最小),这样的学习是有效的。 1, 线性回归问题 例如,信用卡额度预测问题:特征是用户的信息(年龄,性别,年薪,当前债务,...),我们要预测可以给该客户多大的信用额度。 这样的问题就是回归问题。 目标值y 是实数空间R。 线性回归假设: 线性回归假设的思想是:寻找这样的直线/平面/超平面,使得输入数据的残差最小。 通常采用的error measure 是squared error: 2,线性回归算法 squared error 的矩阵表示: Ein 是连续可微的凸函数,可以通过偏微分求极值的方法来求参数向量w。 求得Ein(w) 的偏微分: 另上式等于0,即可以得到向量w。 上面分两种情况来求解w。当XTX(X 的转置乘以X) 可逆时,可以通过矩阵运算直接求得w;不可逆时,直观来看情况就没这么简单。 实际上,无论哪种情况,我们都可以很容易得到结果。因为许多现成的机器学习/数学库帮我们处理好了这个问题,只要我们直接调用相应的计算函数即可。有些库中把这种广义求逆矩阵运算成为 pseudo-inverse。 到此,我们可以总结线性回归算法的步骤(非常简单清晰): 3,线性回归是一个“学习算法” 吗? 乍一看,线性回归“不算是”机器学习算法,更像是分析型方法,而且我们有确定的公式来求解w。 实际上,线性回归属于机器学习算法: (1) 对Ein 进行优化。 (2)得到Eout 约等于 Ein。 (3)本质上还是迭代提高的:pseudo-inverse 内部实际是迭代进行的。 经过简单的分析证明可以得到Ein,Eout 的平均范围(过程见林轩田视频),画出学习曲线: 4, 线性回归与线性分类器 比较一下线性分类与线性回归: 之所以能够通过线程回归的方法来进行二值分类,是由于回归的squared error 是分类的0/1 error 的上界,我们通过优化squared error,一定程度上也能得到不错的分类结果;或者,更好的选择是,将回归方法得到的w 作为二值分类模型的初始w 值。 上一讲是关于线性回归,重点是求解w 的解析方案(通过pseudo-inverse 求解w)。 这一讲关注另一个很重要的方法,逻辑斯蒂回归(logistic regression)。 林轩田对逻辑斯蒂回归的解释思路和Andrew Ng 还是有明显区别的,都十分有助于我们的理解;但要深究其数学意义,还要自己多钻研。 1,逻辑斯蒂回归问题 有一组病人的数据,我们需要预测他们在一段时间后患上心脏病的“可能性”,就是我们要考虑的问题。 通过二值分类,我们仅仅能够预测病人是否会患上心脏病,不同于此的是,现在我们还关心患病的可能性,即 f(x) = P(+1|x),取值范围是区间 [0,1]。 然而,我们能够获取的训练数据却与二值分类完全一样,x 是病人的基本属性,y 是+1(患心脏病)或 -1(没有患心脏病)。输入数据并没有告诉我们有关“概率” 的信息。 在二值分类中,我们通过w*x 得到一个"score" 后,通过取符号运算sign 来预测y 是+1 或 -1。而对于当前问题,我们如同能够将这个score 映射到[0,1] 区间,问题似乎就迎刃而解了。 逻辑斯蒂回归选择的映射函数是S型的sigmoid 函数。 sigmoid 函数: f(s) = 1 / (1 + exp(-s)), s 取值范围是整个实数域, f(x) 单调递增,0 <= f(x) <= 1。 于是,我们有: 2,逻辑斯蒂回归的优化方法 对于上面的公式,如何定义Ein(w) 呢? logistic regression 的目标是 f(x) = P(+1|x): 当y = +1 时, P(y|x) = f(x); 当y = -1 时, P(y|x) = 1 - f(x). 在机器学习假设中,数据集D 是由f 产生的,我们可以按照这个思路,考虑f 和假设 h 生成训练数据D的概率: 训练数据的客观存在的,显然越有可能生成该数据集的假设越好。 通过一些列简单转换,我们得到最终的优化目标函数: 注意上图中"cross-entropy error" 的定义。 3,LR Error 的梯度 Ein(w) 的微分结果是: 想要上式等于零,或者sigmoid 项恒为0,这时要求数据时线性可分的(不能有噪音)。 否则,需要迭代优化。直观的优化方法: 4, 梯度下降法 梯度下降法是最经典、最常见的优化方法之一。 要寻找目标函数曲线的波谷,采用贪心法:想象一个小人站在半山腰,他朝哪个方向跨一步,可以使他距离谷底更近(位置更低),就朝这个方向前进。这个方向可以通过微分得到。 选择足够小的一段曲线,可以将这段看做直线段,那么有: 梯度下降的精髓: 之所以说最优的v 是与梯度相反的方向,想象一下:如果一条直线的斜率k>0,说明向右是上升的方向,应该向左走;反之,斜率k<0,向右走。 解决的方向问题,步幅也很重要。步子太小的话,速度太慢;过大的话,容易发生抖动,可能到不了谷底。 显然,距离谷底较远(位置较高)时,步幅大些比较好;接近谷底时,步幅小些比较好(以免跨过界)。距离谷底的远近可以通过梯度(斜率)的数值大小间接反映,接近谷底时,坡度会减小。 因此,我们希望步幅与梯度数值大小正相关。 原式子可以改写为: 最后,完整的Logistic Regression Algorithm: 在上一讲中,我们了解到线性回归和逻辑斯蒂回归一定程度上都可以用于线性二值分类,因为它们对应的错误衡量(square error, cross-entropy) 都是“0/1 error” 的上界。 1, 三个模型的比较 1.1 分析Error Function 只是三个model 对其做了不同处理: 为了更方便地比较三个model,对其error function 做一定处理: 这样,三个error function 都变成只有y*s 这一项“变量”。 很容易通过比较三个error function 来得到分类的0/1 error 的上界: 这样,我们就理解了通过逻辑斯蒂回归或线性回归进行分类的意义。 1.2 优缺点比较 实际中,逻辑斯蒂回归用于分类的效果优于线性回归的方法和POCKET 算法。线性回归得到的结果w 有时作为其他几种算法的初值。 2,随机梯度下降 (Stochastic Gradient Descent) 每次更新都需要遍历所有data,当数据量太大或者一次无法获取全部数据时,这种方法并不可行。 我们希望用更高效的方法解决这个问题,基本思路是:只通过一个随机选取的数据(xn,yn) 来获取“梯度”,以此对w 进行更新。这种优化方法叫做随机梯度下降。 这种方法在统计上的意义是:进行足够多的更新后,平均的随机梯度与平均的真实梯度近似相等。 3,多类别分类 (multiclass classification) 一种直观的解决方法是将其转化为多轮的二值分类问题:任意选择一个类作为+1,其他类都看做-1,在此条件下对原数据进行训练,得到w;经过多轮训练之后,得到多个w。对于某个x,将其分到可能性最大的那个类。(例如逻辑斯蒂回归对于x 属于某个类会有一个概率估计) 它的最大缺点是,目标类很多时,每轮训练面对的数据往往非常不平衡(unbalanced),会严重影响训练准确性。multinomial (‘coupled’) logistic regression 考虑了这个问题,感兴趣的话自学下吧。 4,另一种多值分类方法 基本方法:每轮训练时,任取两个类别,一个作为+1,另一个作为-1,其他类别的数据不考虑,这样,同样用二值分类的方法进行训练;目标类有k个时,需要 k(k-1)/2 轮训练,得到 k(k-1)/2 个分类器。 显然,这种方法的优点是每轮训练面对更少、更平衡的数据,而且可以用任意二值分类方法进行训练;缺点是需要的轮数太多(k*(k-1)/2),占用更多的存储空间,而且预测也更慢。 前面的分析都是基于“线性假设“,它的优点是实际中简单有效,而且理论上有VC 维的保证;然而,面对线性不可分的数据时(实际中也有许多这样的例子),线性方法不那么有效。 1,二次假设 对于下面的例子,线性假设显然不奏效: 我们可以看出,二次曲线(比如圆)可以解决这个问题。 接下来就分析如何通过二次曲线假设解决线性方法无法处理的问题,进而推广到多次假设。 对于上面的例子,我们可以假设分类器是一个圆心在原点的正圆,圆内的点被分为+1,圆外的被分为-1,于是有: 在上面的式子中,将(0.6, -1, -1) 看做向量w,将(1, x1^2, x2^2) 看做向量z,这个形式和传统的线性假设很像。可以这样理解,原来的x 变量都映射到了z-空间,这样,在x-空间中线性不可分的数据,在z-空间中变得线性可分;然后,我们在新的z-空间中进行线性假设。 Linear Hypotheses in Z-Space 在数学上,通过参数w 的取值不同,上面的假设可以得到正圆、椭圆、双曲线、常数分类器,它们的中心都必须在原点。如果想要得到跟一般的二次曲线,如圆心不在原点的圆、斜的椭圆、抛物线等,则需要更一般的二次假设。 2,非线性转换 进行非线性转换的学习步骤: 这里的非线性转换其实也是特征转换(feature transform),在特征工程里很常见。 3,非线性转换的代价 所谓”有得必有失“,将特征转换到高次空间,我们需要付出学习代价(更高的模型复杂度)。 x-空间的数据转换到z-空间之后,新的假设中的参数数量也比传统线性假设多了许多: 根据之前分析过的,vc 维约等于自由变量(参数)的数量,所以新假设的dvc 急速变大,也就是模型复杂大大大增加。 回顾机器学习前几讲的内容,我们可以有效学习的条件是:(1)Ein(g) 约等于 Eout(g);(2)Ein(g) 足够小。 当模型很简单时(dvc 很小),我们更容易满足(1)而不容易满足(2);反之,模型很复杂时(dvc很大),更容易满足(2)而不容易满足(1)。 看来选择合适复杂度的model 非常trick :-) 4,假设集 前面我们分析的非线性转换都是多项式转换(polynomial transform)。 我们将二次假设记为H2,k次假设记为Hk。显然,高次假设的模型复杂度更高。 也就是说,高次假设对数据拟合得更充分,Ein 更小;然而,由于付出的模型复杂度代价逐渐增加,Eout 并不是一直随着Ein 减小。 上图我们在前面也见过。实际工作中,通常采用的方法是:先通过最简单的模型(线性模型)去学习数据,如果Ein 很小了,那么我们就认为得到了很有效的模型;否则,转而进行更高次的假设,一旦获得满意的Ein 就停止学习(不再进行更高次的学习)。 总结为一句话:linear/simpler model first ! 1,什么是过拟合(overfitting) 上图中,竖直的虚线左侧是"underfitting", 左侧是"overfitting”。 发生overfitting 的主要原因是:(1)使用过于复杂的模型(dvc 很大);(2)数据噪音;(3)有限的训练数据。 2,噪音与数据规模 还有一种情况,如果数据是由我们不知道的某个非常非常复杂的模型产生的,实际上有限的数据很难去“代表”这个复杂模型曲线。我们采用不恰当的假设去尽量拟合这些数据,效果一样会很差,因为部分数据对于我们不恰当的复杂假设就像是“噪音”,误导我们进行过拟合。 3,随机噪音与确定性噪音 (Deterministic Noise) 上图是关于2次曲线和10次曲线对数据的拟合情况,我们将overfit measure 表示为Eout(g10) - Eout(g2)。 下图左右两边分别表示了随机噪音和确定性噪音对于Overfitting 的影响。 可见,数据规模一定时,随机噪音越大,或者确定性噪音越大(即目标函数越复杂),越容易发生overfitting。总之,容易导致overfitting 的因素是:数据过少;随机噪音过多;确定性噪音过多;假设过于复杂(excessive power)。 如果我们的假设空间不包含真正的目标函数f(X)(未知的),那么无论如何H 无法描述f(X) 的全部特征。这时就会发生确定性噪音。它与随机噪音是不同的。 4,解决过拟合问题 4.1 数据清洗(data ckeaning/Pruning) 4.2 Data Hinting: “伪造”更多数据, add "virtual examples" 其他解决过拟合的方法在后面几讲介绍。 1,正规化:Regularization 发生overfitting 的一个重要原因可能是假设过于复杂了,我们希望在假设上做出让步,用稍简单的模型来学习,避免overfitting。例如,原来的假设空间是10次曲线,很容易对数据过拟合;我们希望它变得简单些,比如w 向量只保持三个分量(其他分量为零)。 图中的优化问题是NP-Hard 的。如果对w 进行更soft/smooth 的约束,可以使其更容易优化: 我们将此时的假设空间记为H(C),这是“正则化的假设空间”。 2,Weight Decay Regularization 通过前面的分析,我们已经把优化问题变为: 接下来是通过一些几何解释,用lambda 替换常数C,便于优化问题的描述和求解。这个说起来很绕,就不多说了,以免误导各位。其实,这只是林轩田解释regularization 的一种方式,其他课程不一定从这个角度进行讲解的,这里模糊的话不必深究。个人觉得lambda 的表示方式本身就很直观了。 :-) 最后得到的优化目标是: lambda 的大小对于拟合的影响,一个直观例子: 总之,lambda 越大,对应的常数C 越小,模型越倾向于选择更小的w 向量。 这种正规化成为 weight-decay regularization,它对于线性模型以及进行了非线性转换的线性假设都是有效的。 3,正规化与VC 理论 根据VC Bound 理论,Ein 与 Eout 的差距是模型的复杂度。也就是说,假设越复杂(dvc 越大),Eout 与 Ein 相差就越大,违背了我们学习的意愿。 对于某个复杂的假设空间H,dvc 可能很大;通过正规化,原假设空间变为正规化的假设空间H(C)。与H 相比,H(C) 是受正规化的“约束”的,因此实际上H(C) 没有H 那么大,也就是说H(C) 的VC维比原H 的VC维要小。因此,Eout 与 Ein 的差距变小。:-) 4,泛化的正规项 (General Regularizers) 指导我们更好地设计正规项的原则:target-dependent, plausible, friendly. L2 and L1 Regularizer: L2 and L1 Regularizer lambda 当然不是越大越好!选择合适的lambda 也很重要,它收到随机噪音和确定性噪音的影响。
上一讲重点是一些分析机器学习可行性的重要思想和概念,尤其是生长函数(growth function) 和突破点(break point) 的理解。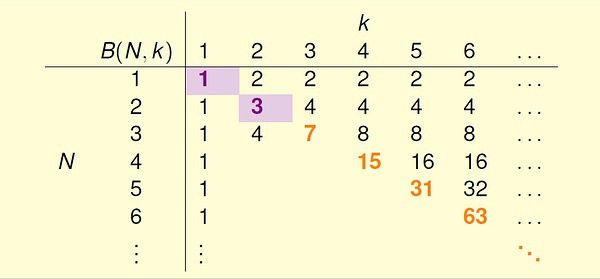



第七讲: VC维理论 (台大机器学习)






第八讲: 噪音和错误 (台大机器学习)




第九讲: 线性回归 (台大机器学习)




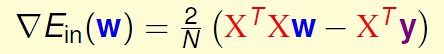





第十讲: 逻辑斯蒂回归 (台大机器学习)








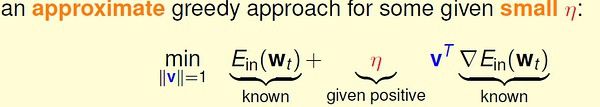



第十一讲: 线性分类模型 (台大机器学习)
本质上讲,线性分类(感知机)、线性回归、逻辑斯蒂回归都属于线性模型,因为它们的核心都是一个线性score 函数:

线性分类对s 取符号;线性回归直接使用s 的值;逻辑斯蒂回归将s 映射到(0,1) 区间。

通过曲线来比较三个error function (注意:cross-entropy 变为以2为底的scaled cross-entropy)


线性分类(PLA)、线性回归、逻辑斯蒂回归的优缺点比较:
(1)PLA
优点:在数据线性可分时高效且准确。
缺点:只有在数据线性可分时才可行,否则需要借助POCKET 算法(没有理论保证)。
(2)线性回归
优点:最简单的优化(直接利用矩阵运算工具)
缺点:ys 的值较大时,与0/1 error 相差较大(loose bound)。
(3)逻辑斯蒂回归
优点:比较容易优化(梯度下降)
缺点:ys 是非常小的负数时,与0/1 error 相差较大。
传统的随机梯度下降更新方法:


注意:在这种优化方法中,一般设定一个足够大的迭代次数,算法执行这么多的次数时我们就认为已经收敛。(防止不收敛的情况)
与二值分类不同的是,我们的target 有多个类别(>2)。
如果target 是k 个类标签,我们需要k 轮训练,得到k 个w。
这种方法叫做One-Versus-All (OVA):
这种方法叫做One-Versus-One(OVO),对比上面的OVA 方法。
预测:对于某个x,用训练得到的 k*(k-1)/2 个分类器分别对其进行预测,哪个类别被预测的次数最多,就把它作为最终结果。即通过“循环赛”的方式来决定哪个“类”是冠军。
OVA 和 OVO 方法的思想都很简单,可以作为以后面对多值分类问题时的备选方案,并且可以为我们提供解决问题的思路。第十二讲: 非线性转换 (台大机器学习)



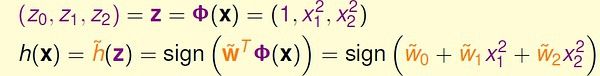




第十三讲: 过拟合 - Overfitting (台大机器学习)
简单的说就是这样一种学习现象:Ein 很小,Eout 却很大。
而Ein 和 Eout 都很大的情况叫做 underfitting。
这是机器学习中两种常见的问题。

我们可以理解地简单些:有噪音时,更复杂的模型会尽量去覆盖噪音点,即对数据过拟合!
这样,即使训练误差Ein 很小(接近于零),由于没有描绘真实的数据趋势,Eout 反而会更大。
即噪音严重误导了我们的假设。
如下面的例子,假设数据是由50次幂的曲线产生的(下图右边),与其通过10次幂的假设曲线去拟合它们,还不如采用简单的2次幂曲线来描绘它的趋势。
之前说的噪音一般指随机噪音(stochastic noise),服从高斯分布;还有另一种“噪音”,就是前面提到的由未知的复杂函数f(X) 产生的数据,对于我们的假设也是噪音,这种是确定性噪音。


我们可以类比的理解它:在计算机中随机数实际上是“伪随机数”,是通过某个复杂的伪随机数算法产生的,因为它对于一般的程序都是杂乱无章的,我们可以把伪随机数当做随机数来使用。确定性噪音的哲学思想与之类似。:-)
对应导致过拟合发生的几种条件,我们可以想办法来避免过拟合。
(1) 假设过于复杂(excessive dvc) => start from simple model
(2) 随机噪音 => 数据清洗
(3) 数据规模太小 => 收集更多数据,或根据某种规律“伪造”更多数据
正规化(regularization) 也是限制模型复杂度的,在下一讲介绍。
将错误的label 纠正或者删除错误的数据。
例如,在数字识别的学习中,将已有的数字通过平移、旋转等,变换出更多的数据。第十四讲: 正规化-Regularization (台大机器学习)