KMeans-Cluster
Cluster the dataset of NBA Player using KMeans method
数据下载地址:https://github.com/huangtaosdt/KMeans-Cluster/tree/master/data
该项目为KMeans的实现算法,整个算法分为三部分:
1.数据准备
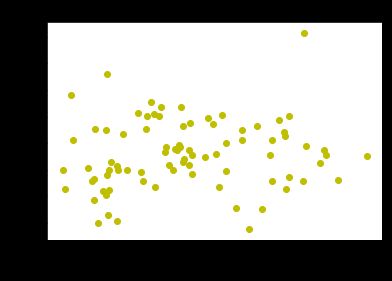
读入数据,提取控球后卫球员,新增特征列:ppg(每场得分),atr(助攻失误率)
使用scatter查看分布情况。
import pandas as pd
nba=pd.read_csv('./data/nba_2013.csv')
#Data preparing
point_guards=nba[nba['pos']=="PG"]
point_guards.head()
#Calculate Points Per Game
point_guards['ppg'] = point_guards['pts'] / point_guards['g']
# Sanity check, make sure ppg = pts/g
point_guards[['pts', 'g', 'ppg']].head(5)
#Calculate Assist Turnover Ratio
point_guards = point_guards[point_guards['tov'] != 0]
point_guards['atr']=point_guards['ast']/point_guards['tov']
#Visualize data
%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(point_guards['ppg'], point_guards['atr'], c='y')
plt.title("Point Guards")
plt.xlabel('Points Per Game', fontsize=13)
plt.ylabel('Assist Turnover Ratio', fontsize=13)
plt.show()
2.算法实现
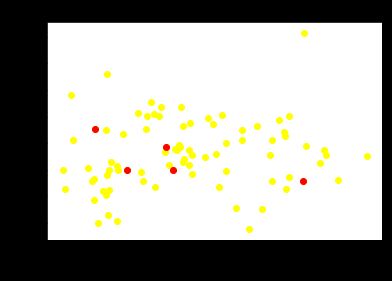
- step0
初始化簇心--为方便操作,使用dictionary存储簇心#Initialize centroids import numpy as np num_clusters=5 random_initial_points=np.random.choice(point_guards.index,size=num_clusters) centroids=point_guards.loc[random_initial_points] #Visualize Centroids plt.scatter(point_guards['ppg'], point_guards['atr'], c='yellow') plt.scatter(centroids['ppg'], centroids['atr'], c='red') plt.title("Centroids") plt.xlabel('Points Per Game', fontsize=13) plt.ylabel('Assist Turnover Ratio', fontsize=13) plt.show() #Convert centroids list as dictionary def centroids_to_dict(centroids): dictionary={} counter=0 for index,row in centroids.iterrows(): dictionary[counter]=[row['ppg'],row['atr']] counter+=1 return dictionary centroids_dict = centroids_to_dict(centroids)
簇心:
{0: [2.84, 2.7701149425287355],
1: [5.333333333333333, 2.0],
2: [8.354430379746836, 2.424],
3: [8.958333333333334, 1.9914529914529915],
4: [19.024390243902438, 1.7840909090909092]}
- step1
计算每个球员到各簇心的距离,根据其最短距离生成cluster column.# Step 1 #Calculate Euclidean Distance def calculate_distance(centroid,playerValues): distances=[] #list不能直接相减 distance=sum((np.array(centroid)-np.array(playerValues))**2) distances.append(distance) return np.sqrt(distances) #Assign each point to cluster def assign_to_cluster(row): player=[row['ppg'],row['atr']] lowest_dist=-1 clus_id=-1 for clu_id,centroid in centroids_dict.items(): distance=calculate_distance(centroid,player) if lowest_dist==-1: lowest_dist=distance clus_id=clu_id elif distance
- step2
重新计算各簇簇心,重复step1.# Step 2 Recalculate the centroids for each cluster. def recalculate_centroids(df): new_centroids_dict={} for clu_id in range(num_clusters): df_clus_id=df[df['cluster']==clu_id] mean_ppg=df_clus_id['ppg'].mean() mean_atr=df_clus_id['atr'].mean() new_centroids_dict[clu_id]=[mean_ppg,mean_atr] return new_centroids_dict centroids_dict = recalculate_centroids(point_guards) #Repeat above steps point_guards['cluster']=point_guards.apply(assign_to_cluster,axis=1) visualize_clusters(point_guards, num_clusters)
簇心:
{0: [2.6178602133875315, 2.12795670952364],
1: [5.032680887069763, 1.9577408362904933],
2: [7.587016263538343, 2.7497928951953226],
3: [10.743029331820049, 2.3538881165489767],
4: [17.993849912411445, 2.3359021336098063]}
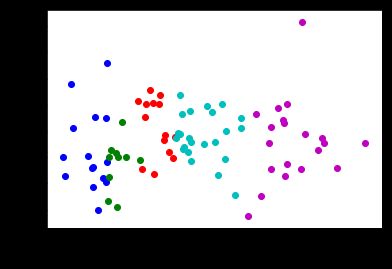
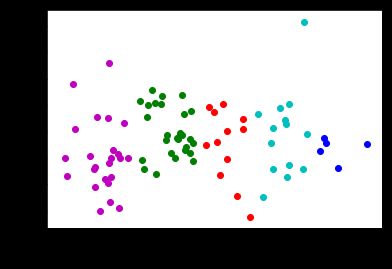
- 重复若干次step12、2,查看聚类结果
centroids_dict = recalculate_centroids(point_guards)
point_guards['cluster'] = point_guards.apply( assign_to_cluster, axis=1)
visualize_clusters(point_guards, num_clusters)
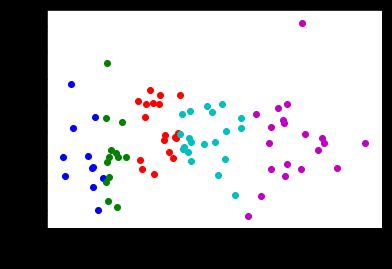
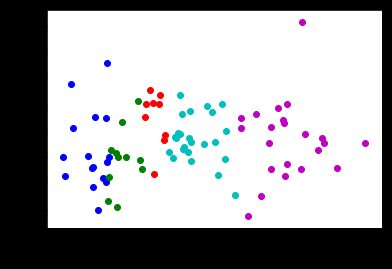
总结:
以上为KMeans实现算法,sklearn library中已经实现了KMeans。在重复聚簇时,sklearn采取的方法是每次重复聚簇时簇心均为随机产生,从而可以有效降模型出现的偏差,过程:
#Do it using sklearn library
from sklearn.cluster import KMeans
km=KMeans(n_clusters=5,random_state=1)
km.fit(point_guards[['ppg','atr']])
point_guards['cluster'] = km.labels_
visualize_clusters(point_guards, num_clusters)