吴甘沙:天外飞“厕”、红绿灯消失,未来无人驾驶将被重新定义 | AI ProCon 2019

2019 年9 月 5 日至 7 日,由新一代人工智能产业技术创新战略联盟(AITISA)指导,鹏城实验室、北京智源人工智能研究院支持,专业中文 IT 技术社区 CSDN 主办的 2019 中国 AI 开发者大会(AI ProCon 2019)在北京顺利举行。短短 3 天之内,60+ 人工智能领域专家和领导者相聚北京,加入了这场属于 AI 开发者的盛大狂欢,探讨机器学习、自然语言处理、计算机视觉、AI+DevOps 和 AI+ 小程序等多个不同技术专题里开发者最关心的问题。
在主会场上,驭势科技联合创始人、董事长、CEO 吴甘沙为大家分享了题为《无人驾驶产业化的 AI 挑战和机遇》的演讲。吴甘沙从产业化的角度,从无人驾驶从业和研究的世界观谈到无人驾驶技术发展和变迁历史,再到无人驾驶商业化场景的探讨,全方位分析了当前和未来无人驾驶产业化的现状、挑战和机遇。
整理 | 夕颜
出品 | AI科技大本营(ID:rgznai100)
以下为演讲实录:
非常感谢CSDN的邀请,让我与大家相遇在 AI 开发者大会。
无人驾驶是 AI 密集型产业,也是未来 AI 落地的一个重要的大市场,今天我将更多地与大家分享无人驾驶真正实现产业化会遇到的 AI 挑战和机遇。
我们做任何东西一定要有世界观,我向大家分享一下驭势科技做无人驾驶的世界观。
2005 年,我当时还在英特尔,公司参与了 DARPA 无人驾驶挑战赛,赞助了两辆车,一辆是来自 CMU 的夺冠热门车 ,一辆是来自斯坦佛的黑马,但斯坦福的车身上 LOGO 位置全被占满了,没有给我们放 LOGO 的空间。这时,一个天才提出可以在这辆车两侧后视镜边上的空窗上放 LOGO,反正没有驾驶员了。这件事给了我一个启示:无人驾驶是新物种,每个功能都被重新定义了,包括这面窗子,我们应该用重新定义的思路去思考,此后,这成为我们世界观的一部分。
到后面的比赛中,CMU 这辆车领先大半程,但在最后一刻却失速,被斯坦佛这辆车反超。13 年以后,我们才知道原来是 CMU 这辆车因为引擎控制模块和燃油喷嘴间的过滤器坏掉了。这件事让我有了关于世界观的第二部分的思考,即无人驾驶要尊重汽车产业长期存在的规律 ,要有敬畏之心。
我先说一下世界观的第一部分,一切重新定义。
我们如何重新定义?未来有了 AI、车联网以后,车在路上会编队出行,单个车道的使用效率会提升 3-4 倍,我们不再需要十字路口的红绿灯,因为在全局调度算法下,所有的车都能够高效通过十字路口。停车也不再是问题,到目的地之后可以直接下车,出租车将会川流不息,晚上它可以默默地停到五环外,不用担心停车的问题。

高速公路上的大货车不再有车头。末端配送会由一些小机器人完成,快递母舰开到社区以后,我们可以放出密密麻麻的小机器人出来挨家挨户送货。
我们很少在网上买鞋,因为脚是非标的。未来鞋店可以开到你门口,你上车试鞋,下车买单,这使得未来物的流动更加自由。
更广义地说,很多今天的东西都可以动起来,比如你缺钱时一个无人驾驶 ATM 机可以突然现身。在外面玩内急时一个无人驾驶厕所可以飞速驶来。未来,车变成了空间,可以安营扎寨,车的底盘可以离开,在你需要时它自己开过来。这些商业场景可以改变现在的很多产业,比如钟点房、汽车旅馆、支线航空等。
在新销售、新零售、新商业上也有很多创意,比如无人货架可以出现在车里,车还可以是 mini KTV,还可以是模拟按摩椅,它可以是一个个人健身房,车在路上跑,你在车上的跑步机上跑,甚至是个人影院,为你定制内容 。经过测算以后我们发现,待无人驾驶产业发达之后还是要买茅台股票,因为酒类销售量可以增加 30%,不用担心酒价。
所以,一切可以重新定义。

再看世界观的第二部分,我们为何要对汽车产业有敬畏之心?我们把 AI 分成 4 个象限:实体、虚拟 、关键任务和非关键任务。比如小冰是虚拟的非关键任务,炒股机器人是虚拟的关键任务,如果处理不好会导致指数骤然下跌 。扫地机器人是实体的非关键任务,而无人驾驶是实体的关键任务,也是最难的AI。
我们简单看一下训练一个无人驾驶“老司机”要做哪些事情。
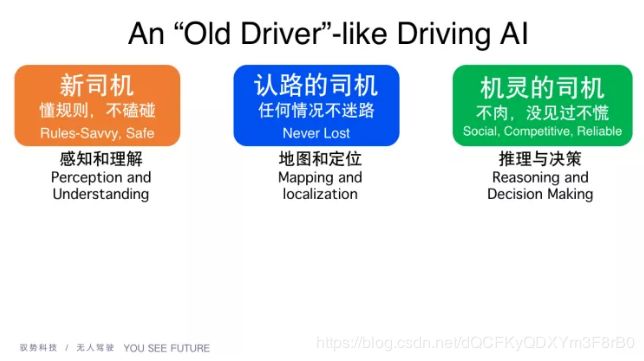
首先是感知和理解,就像一个新司机一样,无人车要懂得规矩和规则,车不能撞到别人;第二是要认路,这里面涉及地图和定位;第三是更高的要求,司机要机灵,有一定的决策能力,才能保证开得不“肉”,同时在见到没见过的东西时不会慌。这是 AI 中重要的三块,但是要达到老司机水平还需要开得平稳,这又涉及很多非AI的传统控制算法。
在感知领域,使用最多的是激光雷达和视觉。前者基于 3D 点云对多个目标进行检测和跟踪。典型的视觉算法采用一个多任务网络,多任务网络能够检测无限延伸的车道线,同时检测可行驶区域,以及路面上的各种物体和标识,特别是将所有车用立体的框标识出来,对其跟踪、测速、测距。此外,无人车还需要一点预测和想象能力,比如道路蜿蜒延伸的方式。
除了感知,无人车还需要一点认知能力和理解能力。理解有很多层面,比如在理解了这是一个车道线之后,下一步还要对车道线的语义有更多理解。特斯拉曾发生一起车祸,这次车祸的原因在于两条车道线组成的并不是一个车道,而是主路与匝道之间的分隔区域,但是视觉算法不能理解这个语义,把这个区域认成车道,一路向前开,结果撞到水泥墩上了。
往往理解还需要配合高精度地图,告诉无人车这不是车道而是分隔区。高精度地图涉及到如何用今天的传感器,比如激光雷达和摄像头采图并进行语义标注。
有了高精地图以后,下一步要处理在复杂空间中的定位。这时不能只靠 GPS定位,在没有 GPS 时也需要高清地图和其他的定位手段,比如SLAM,配合使用。
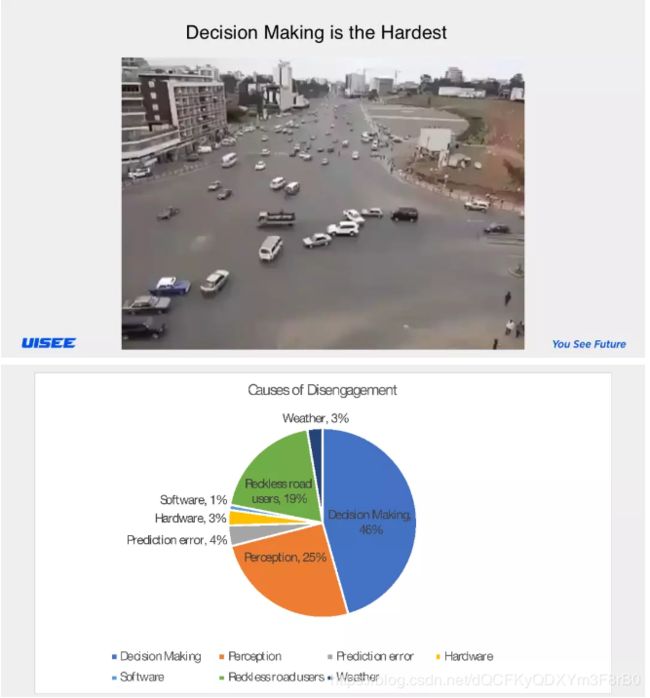
无人车最大的难点在于决策,那么决策难在哪里呢?维基百科上的事故数据显示,中国每 10 万辆车每年造成 105 人死亡,但是在美国这个数据只有 13 个人。我们在看Waymo的人工接管数据,感知错误导致事故发生的比例是 25%, 基本决策错误占 46%,预测错误占 4%,碰到不讲理的司机和行人占 19%,跟决策相关的错误达到了69%,也就是说感知不再是重要的问题,决策才是最关键的难点。
再看另一个数据,在对 10500 起Waymo试乘的乘客调研发现,乘客不满的问题包括不舒服、陷入在车流动不了、碰到自行车和行人紧急刹车等,其实这些情况都涉及到决策 。与中国相比,美国 Waymo 的工作环境相对简单,人少车少,而中国的无人驾驶汽车环境更复杂,存在各种“中国特色”问题。另外,数量级的不同也要求中国的无人车进行不同的算法处理。
这对我们是很大的挑战,传统上 无人驾驶是基于规则做决策,以后更多地是需要基于学习,甚至基于搏弈,比如学习 Model-based、model-free。现在,我们要加入两个新的东西,一个是竞争性,因为在中国,竞争性不够是无法获得路权的;另一个是社会性,不要让人在车流中一眼就看出是很笨很傻的无人车。
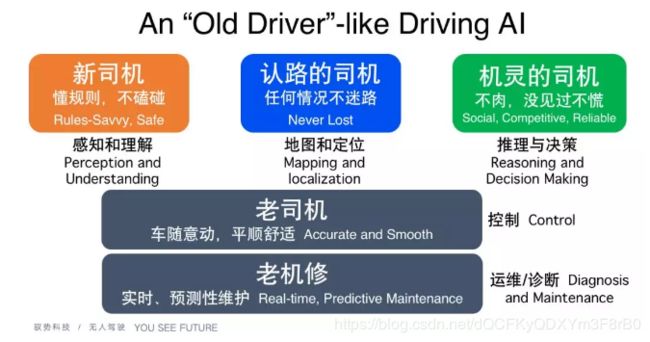
最后,无人车的诊断能力非常重要,这涉及很多后台数据分析,前台数据回传以后实时分析车的零部件工作是否正常,是否可以做预测性、实时性的维护等。
过去10年,上述这些技术都有了长足的发展,但为什么自动驾驶这么难呢?

首先是木桶效应或者短板效应,只要一个零部件还不成熟,整个无人驾驶就无法发挥效用。其次,关键任务开发有一个规律,叫做“90/10”原则,指的是完成了 90% 的任务,但是剩下的 10% 还需要 90% 的时间和精力,无人驾驶不能简单地依靠资本堆砌。第三,还有一个类似于“鸡和蛋”的问题,量上不去,供应链就不会随之优化,便宜不下来,所以量还是上不去。
无人驾驶如何进行产业化?无人驾驶领域的前两个难点意味着它的商业化周期非常长,这需要我们采用“撸串”的策略。一台很大的自动烤串烤台不可能只烤一根串,Robo-taxi是一根要烤 5-7 年的串,烤台空着是没有意义的,所以你可以烤多根串,也就是寻找多种场景进行商业化,让研发平台适应多场景。但是另一方面,我们也需要专注,因为烤串时所有精力会聚焦在快熟的那根串上,要注意别烤焦了,因为产品化资源会放在最先熟的那根串上。

什么串最先熟?要先找场景,我认为这些规律对于所有 AI 普遍适用:第一,它是否是高频刚需,是否能解决客户的痛点,而不是弄两台车秀科技感;第二,法律上和技术上是否实现无人化运营;第三,是否能算得过来账,是替换掉 1 个驾驶员还是 3 个驾驶员?一个地方有 5 台车还是有 500 台车?这些都会影响算账。
无人驾驶的商业化场景包括高速公路巡航,停车场的自动代客泊车等。自动泊车这套系统不用激光雷达,只要 6 个摄像头和 12 个超声波,用小几千元的成本基本就能够实现停车场无人泊车。去年,我们已经把这套系统交付了 50 个种子用户。它们一旦进入真实世界,可能会遭遇很多人的“挑逗“,这是非常危险的,因此这项技术需要足够可靠。目前,我们已经运营这套系统 10 个月,支持 10 多个停车场,成功率非常高。
另外,无人驾驶的高频场景还包括机场的物流拖车,现在一个典型的国际机场有近千辆拖车,而为了运营这近千辆拖车需要 3000 多个司机。在这个场景中应用无人车有很多挑战,比如如何真正实现无人化。今年开始,我们实现了机场物流拖车的无人化运营,无人车可以端到端地从停机坪或码头开到行李中心,再调个头往行李中心室内开下去。
另外一个场景是无人小巴,今年博鳌论坛上,我们与宇通和一汽合作做了两款无人小巴,与宇通合作的这款今年 5 月17 号开始在郑州的一条公交线上运营,这是无人化公交系统最早应用到现实世界的案例之一。
这几个场景要求一套源代码和一套工具链,未来将会面临巨大的挑战。我们做这个系统经常要与两个“R”搏斗,一个是 Reliability,在指定边界里它是非常可靠、不出错的,一个是Robustness,就是在未知情况、开放不收敛的环境里做到可靠。这是最大的挑战。
解决Robustness,目前仍然需要更多的数据。我们可以通过哪些更好的办法获得数据?其中一个方法是通过众包获得丰富多元的数据,有了数据下一步是大规模的标注能力 ,而且需要进行细粒度标注,而不是简单的bounding box。现在有很多支持半自动标注的方法,比如谷歌推出的流体标注等。既有激光雷达数据,又有视觉数据时还可以用自标注法。再下一步是大规模的快速训练,数据经过实时训练后回到车里,形成一个永不停止的数据闭环 。
值得注意的是,对数据的关注点在不断变化。
-
最早是 Bounding Boxes,后来慢慢演变成分割,从粗粒度进化到细粒度,最开始只需要认出是车即可,现在细粒度标注需要知道车型(是否大型车、警车、救护车)和车辆的状态(是否打开转向灯、门是否开着)等;
-
从静态图片到动态视频,原来只关注静态图片里的对象,现在要关注动态视频里的时空关系、比例动态情况;
-
从简单的物体识别到行为的识别;
-
从行为识别和跟踪到理解和预测;
Robustness,对测试有很高的要求,我们用实体化的结构性测试来模拟现实世界的各种corner case,但这种测试方法既危险,成本又高。接下来,我们要思考的是如何加速这样的测试,最好的方法其实就是仿真,通过生成性对抗网络等技术,我们可以构建出逼真的仿真模拟环境,从而降低风险。
有了结构性测试,还需要路测,在真实的状况下经受考验。到底经过多少路测,能够证明无人驾驶比人好20%呢?兰德公司推导出来需要110亿英里,如果有100辆车,一天到晚不吃不喝不休息不停地跑,要跑500年。
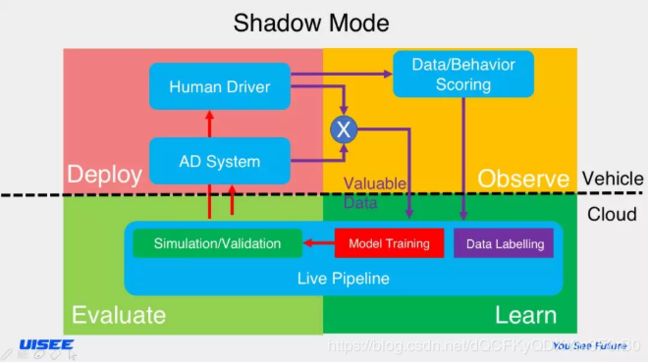
解决这一难题的办法是Shadow mode,即“影子模式”,在已经大量部署的车上进行“影子”下的AI驾驶,把人类驾驶的情况与 AI 驾驶的结果进行比较,如果不同,就把数据发回来,在云端进行标注 、训练、仿真、训练、验证,再把模型送回去。有了它,1000 万辆车装着“影子模式”,每辆车只需要开1100英里,就能达到110亿英里,而这只需要不到一个月,根本不需要 500 年。
最后,我想与分享未来 AI 发展的一些看法。今天的 AI 训练出来的是标注的框框和线条,根本不懂其中的含义是什么。人类在驾校学开车几十天就可以学会,因为我们有 18 岁前的社会阅历知识图谱。第二,我们会不断模仿,熟能生巧,这就是强化学习和模仿学习的能力。第三,我们永远会见到未知的事物,但是可以通过推理、解释理解新事物,知其然,也知其所以然。第四,我们永远会遇到未见过的场景,人类处理这些场景依靠举一反三,这类似于迁移学习。
未来,我们将在这几个方面的研究上发力,我们在与包括Berkeley DeepDrive在内的一些顶尖研究机构研发下一代算法。
谢谢大家!
(*本文为AI科技大本营整理文章,转载请微信联系1092722531)
精彩推荐
2019 中国大数据技术大会(BDTC)历经十一载,再度火热来袭!豪华主席阵容及百位技术专家齐聚,15 场精选专题技术和行业论坛,超强干货+技术剖析+行业实践立体解读,深入解析热门技术在行业中的实践落地。【早鸟票】与【特惠学生票】限时抢购,扫码了解详情!
