Github链接
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 35 | 40 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 120 | 200 |
| Analysis | 需求分析(包括学习新技术) | 100 | 50 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 50 | 60 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 30 | |
| Design | 具体设计 | 60 | 70 |
| Coding | 具体编码 | 260 | 270 |
| Code Review | 代码复审 | 30 | 50 |
| Test | 测试(自我测试,修改,提交修改) | 110 | |
| Reporting | 报告 | 40 | 45 |
| Test Report | 测试报告 | 60 | |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结并提出过程改进计划 | 50 | 40 |
| 合计 | 995 | 1085 |
程序设计及实现过程
任务注意事项:
每行一个输入数据,带有前缀x!
其中x表示难度级别,根据题目所成三个难度
输入输出文件采用UTF-8编码
地址一定从大到小排序
省/市级行政区如后缀为“省”/“市”,则有可能省略后缀
若县级行政区后缀为“县”,则可能缺失整个市级行政区
县/乡级行政区可能缺失
前两级难度缺失的部分,无需补全,相应位置保留空字符
2!难度中后三级地址至多缺失两级,且若门牌号不缺失,则路名不会缺失
3!难度中前四级地址可能缺失且需要补全
设计与实现:
设计与实现
设计过程
首先对名字和手机号处理,其中名字一定在字符串前面且有逗号隔开,可用正则表达式将名字取出来,而手机号是11位数字串,也可根据正则表达式取出;
其次对省市进行处理,因为有四个直辖市的特殊存在,要进一步讨论:
从网上爬取到省和市的相关数据,生成定义两个列表,方便之后匹配;
将四个直辖市放在列表前四个,进行省级匹配时,只需判断当前匹配到省级所对应的位置即可;
由于爬取不到之后的完整数据,我太菜了 只好慢慢分割地址,一步步进行讨论:
先将难度等级也用正则表达式取出,根据等级分别进行讨论;
第一级只有五级地址,匹配到县级之后要和二三级分开讨论,第二级只需正常匹配,第三级到最后面用高德地图地理/逆地理编码的API接口进行补充直接替换前四级即可。
流程图
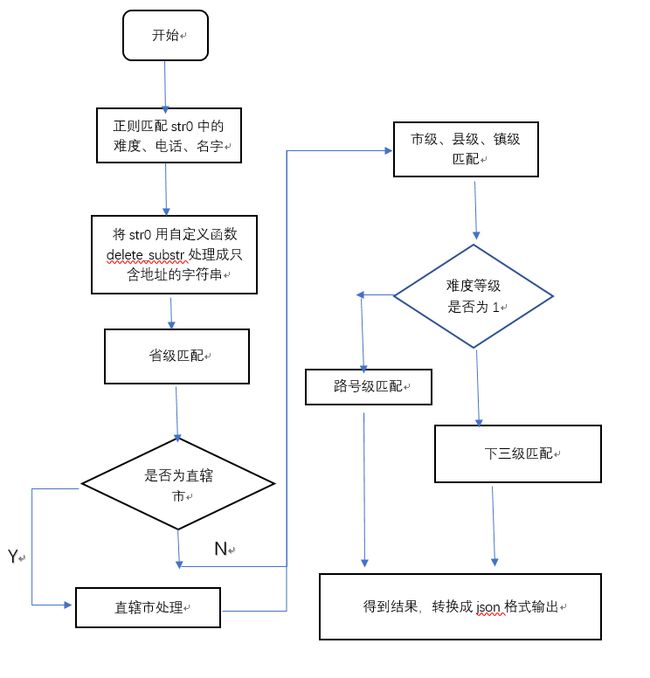
实现过程
难度等级匹配
p=re.compile('(.+?)!')
num=p.findall(str0)[0]
num=int(num)手机号匹配
p1=re.compile('\d{11}')
pp1=p1.findall(str0)
tele=str(pp1[0])名字匹配
p2=re.compile('!(.+?),')
pp2=p2.findall(str0)[0]
name=pp2各级地址匹配具体方面代码有点多,这边就不写了。
高德地址划分API,只用作第三难度,所以只取对应地址的经纬度
url = 'https://restapi.amap.com/v3/geocode/geo? address='+str1+'&output=XML&key=46b59533e5942f662c8201f2df21a7d9'
res = requests.get(url).text
#print(res)
res=str(res)
p=re.compile('(.+?) ')#取得地址对应的经纬度
location=p.findall(res)[0]高德地图逆地理编码,将得到的地址经纬度转换成实际地址,总体会稍有偏差,但是前四级是不会错的
url = 'https://restapi.amap.com/v3/geocode/regeo?output=xml&location='+location+'&key=46b59533e5942f662c8201f2df21a7d9&radius=50&extensions=base'
res = requests.get(url).text
#print(res)主要函数
正则匹配re.search() re.compile .findall()
Json格式转换函数json.dumps
调用request模块
性能分析与改进
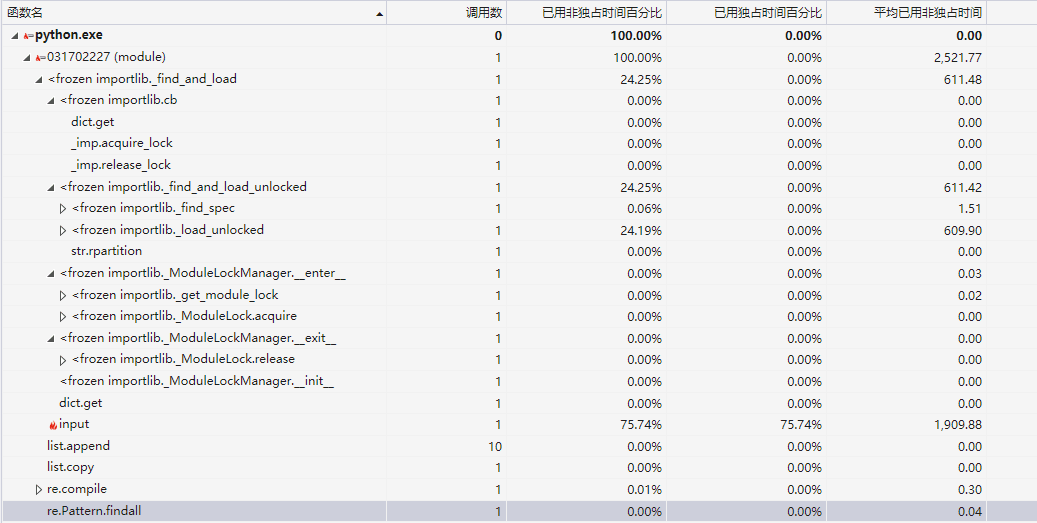
从性能分析图可以看出耗时最长的是输入数据,之前三个小题都用高德地图api来做,而api请求时间太长,所以改进后只在第三小题调用api,数据输入所占时间只有百分之62,改进后性能有明显改善。
单元测试
测试样例
1!安搜,13299595391北京市门头沟区东辛房街道建设街160号.
1!第五昌因,黑龙江省鸡西市15109633363密山市裴德镇兴利村农机服务站.
1!墨失,江苏13504338907徐州市新沂市双塘镇大东线新沂市双塘镇丁集村民委员会.
2!从宁屡,吉林长春13970881959市二道区东站街道通安街566号十委市场.
2!濮婚时,广西壮13602947448族自治区桂林七星区七星区街道育才路15号北院广西师大育才校区.
2!边眉,广东省珠海市斗门区井岸镇工业18938327523大道1号新鸿酒店.
2!华壳腰,福建省龙15072977042岩新罗区西陂街道西陂路286号西山小区.
3!巢盒,河北省衡水市13287435790桃城区永兴西路122号赵家庄居民1区.
3!佘器,福建莆田市仙游县仙东13327922135村仙东小学.
3!李危刊,固原市泾源县兴盛乡13043995904园兴路下金村卫生室.测试结果
{"level": 1, "姓名": "安搜", "手机": "13299595391", "地址": ["北京", "北京市", "门头沟区", "东辛房街道", "建设街160号"]}
{"level": 1, "姓名": "第五昌因", "手机": "15109633363", "地址": ["黑龙江省", "鸡西市", "", "密山裴德镇", "兴利村农机服务站"]}
{"level": 1, "姓名": "墨失", "手机": "13504338907", "地址": ["江苏省", "徐州市", "", "新沂双塘镇", "大东线新沂市双塘镇丁集村民委员会"]}
{"level": 2, "姓名": "从宁屡", "手机": "13970881959", "地址": ["吉林省", "长春市", "二道区", "东站街道", "通安街", "566号", "十委市场"]}
{"level": 2, "姓名": "濮婚时", "手机": "13602947448", "地址": ["广西壮族自治区", "桂林市", "七星区", "七星区街道", "育才路", "15号", "北院广西师大育才校区"]}
{"level": 2, "姓名": "边眉", "手机": "18938327523", "地址": ["广东省", "珠海市", "斗门区", "井岸镇", "工业大道", "1号", "新鸿酒店"]}
{"level": 2, "姓名": "华壳腰", "手机": "15072977042", "地址": ["福建省", "龙岩市", "新罗区", "西陂街道", "西陂路", "286号", "西山小区"]}
{"level": 3, "姓名": "巢盒", "手机": "13287435790", "地址": ["河北省", "衡水市", "桃城区", "中华街道", "永兴西路", "122号", "赵家庄居民1区"]}
{"level": 3, "姓名": "佘器", "手机": "13327922135", "地址": ["福建省", "莆田市", "仙游县", "西苑乡", "", "", "仙东村仙东小学"]}
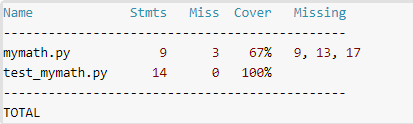
覆盖率
异常处理
名字、手机号省缺情况处理,难度等级省缺好像没法分类就没搞了。
手机号省缺处理:
try:
pp1 = p1.findall(str0)
tele = str(pp1[0])
except IndexError:
pass名字省缺处理
try:
pp2=p2.findall(str0)[0]
name = pp2
except IndexError:
pass总结
有一点点爬虫经验,我只是用了比较简单方法对地址进行匹配,有些情况还是没考虑到,但是太难了不想弄啦。。。难度三主要还是靠API,帮忙测试的同学麻烦下一下requests库,不然运行不了。。
request模块安装教程