1. 什么是测试效度?
测试效度这一概念源于心理计量学。美国教育研究协会、美国心理学协会和全美教育测量公会在2014年最新版本的《教育和心理测试标准》(Standards for Educational and Psychological Testing)(以下简称为《标准》)中把效度定义为:
Validity refers to the degree to which evidence and theory support the interpretations of test scores for proposed uses of tests.
其实,从20世纪30年代至今,测试效度(Testing Validity)的定义经历了多次争论。在这里,小编带大家回顾下历史上效度定义的变迁:
1930s-1940s
这一时期的测试效度属于单一概念,指测试对测量对象的测量程度,也就是某测试的分数和其他关于该项测试目标上的客观测量结果之间的相关程度(Lindquist,1942,转引自邹申2012:140)。我们都知道分数不能够完全地、准确地测量出被测者在该测量目标上的能力,但效度可以告诉我们分数在多少程度上能体现出被测者的能力。
1940s-1980s
这一时期的测试效度不再是单一概念,而是有多种分类。美国心理学协会在1954年发布的《心理测量和诊断技术的具体建议》(Technical Recommendations for Psychological Tests and Diagnostic Techniques)将效度分为4种:内容效度(content validity),构念效度(construct validity),预测效度(predictive validity)和共时效度(concurrent validity)。
内容效度:测试内容与预定要测的内容之间的一致性程度。由于某些客观因素(例如试卷篇幅、测试时间等),一项测试无法囊括所有需检测的内容,测试者只能通过取样,利用部分测试项目进行测试。考查一项测试是否具有较高的内容效度,可以参考:1)测试的内容范围是否明确;2)试题取样是否具有代表性。其中,第二点是内容效度的主要考查方面。如果考试题目是所学内容的最佳或有效取样,则可以推论内容效度较高;如果选题考查要求的范围,或内容重复过多,则可以推论内容效度较低(霍敏,2002)。
构念效度:测试成绩能够解释心理学上的某种结构或特质的程度。所谓构念,是指心理学理论所涉及的抽象而属假设性的理念、特质或变量,如智力、能力倾向、行为习惯、成就动机、人格结构等。语言测试的作用是测出人的语言能力,这就要求我们首先要提出关于“语言能力”的构想,即我们要说明所谓的“语言能力”是什么?有什么特性?由于语言能力处于人的大脑里,到目前为止我们既看不到它,也不能直接测量它。所以,关于语言能力的构想是带有假说性质的。构念效度主要关注一项测试考查了哪一种或哪些种语言能力,以及是否测试了应该考查的能力(霍敏,2002)。
预测效度:测试结果是否能够反映出未来将要发生的事情或者预测被测者未来的行为。举个例子,高考的预测效度,一般是以被录取考生在大学一年级各门学科的平均成绩作为效度标准分数,这些考生高考与大学一年级各门学科的平均成绩的相关系数, 即为预测效度(许之所,张丽芳,2004)。
共时效度:待检验的测试成绩与受试在几乎同一时间参加的其他测试的成绩的相关性(刘芹,2004)。也就是把本次测试与另一个公认的、标准化的测试进行比较,计算两者相关系数,若相关系数大于0.7,那么两者的关系十分密切,说明这场测试是标准化的,具有较高的共时效度。
然而,种类分类也不是一成不变的。美国教育研究协会、美国心理学协会和全美教育测量公会在1966年版和1974年版的《标准》中又把预测效度和共时效度合二为一,称为效标关联效度(criterion-related validity)。此外,还有其他分类方式,例如因子效度(factorial validity),区别效度(discriminant validity)等等,这里就不再赘述。
since 1980s
以Samuel Messick为代表的研究者们把效度看作为一个整体概念,即整体效度概念(unitary concept of validity)。效度不再是某个单一的概念,也不再专注于区分各个种类,而是应当从各个方面尽可能地收集证据,运用不同的测量手段来保证测试的结果能够得到合理的使用(邹申,2012)。Messick认为效度是:
(Validity is)an integrated evaluative judgement of the degree to which empirical evidence and theoretical rationales support the adequacy and appropriateness of inferences and actions based on test scores or other modes of assessment.
效度是关于经验证据和理论论证对建立在测试分数和其他方式评估结果之上的种种推断与行动的充分性与合适性支持程度的综合评价性判断。
(Messick,1989,转引自邹申,2012)
同时,Messick发现基于分类方法而对效度进行验证所得到的结果过于分散,且忽视了测试成绩的价值含义及社会影响。他提出效度只有一个,即构念效度,但不是传统的构念效度,而是包括六大方面:内容方面(content),理论方面(substantive),结构方面(structural),普遍性方面(generalizability),外部方面(external)和结果方面(consequential)(Messick,1994)。Messick指出,证明效度的证据可来自多方面,效度验证不仅仅是对测试本身及分数的评价,还包括对测试结果解释和使用的评价(姜秀娟,2018)。
至此,受Messick效度观的影响,效度验证不再是以结果为导向的研究,而是一个持续不断的拷问过程。
值得一提的是,现在的效度验证非常注重公平性。1999年版的《标准》和2014年版的《标准》都专门开辟了一个章节Fairness in Testing,将公平性定义为无偏颇、考试过程公平、基于考试结果的决策公平以及学习机会均等。具体来讲,“无偏颇”就是消除影响构念效度的偏颇,比如要保证内容样本的覆盖面、所有考生都熟悉答题形式等;“考试过程公平”指在施考过程中平等对待所有考生,考生要有相同的机会展示自己的能力;“基于考试结果的决策公平”指不同考生群体的考试结果具有可比性,能力相同的考生应享有同等的选拔机会;“学习机会均等”主要指在标准参照考试中,考生有相同的机会学习考试内容和接触复习资料,尤其是考试成绩用于决定是否留级或颁发证书时,学习机会均等更显重要(姜秀娟,2018)。
2. 如何衡量测试效度?
有时候老师们在使用了某些测量工具或手段(例如各种考试等)后会说,“这场考试看不出学生们的阅读水平”,这句话实际体现了老师们对测试效度的检验,即效验。效验就是在较为公认的理论框架下,对特定的测试结果的使用、解释以及根据该结果可能做出的推断或决策提供一些可以参考的理论和经验证据(邹申,2012:143)。
学术界关于考查测试效度的讨论也很多,这里篇幅有限,就简单介绍两个效度证据收集的框架:一个是上文出现过的2014年颁布《标准》中规定的证据来源,另一个是目前较为完善也是学术界讨论比较热烈的AUA框架。
2014年版《标准》规定的证据来源
根据2014年版的《标准》,效度证据主要来自五个方面(关丹丹,2017):
1. 基于考试内容的证据
考试内容与欲测构念之间是否匹配,即测验题目与测验要求的一致性。
2. 基于答题过程的证据
基于对考生反应过程的观察,检验考生在回答题目时是否使用或表现出测验开发者所要求使用或表现的能力或策略,有声思维是搜集这一证据的主要方法。
3. 基于试卷结构的证据
对试卷结构本身的检验,与题目的同质性有关,可以通过内部一致性信度、因素分析、多维尺度分析和结构方程模型等方法来评价。
4. 基于与其他变量关系的证据
在该测验上的得分与测量同一构念的相近测验上得分的相关程度,相关分析与回归分析是常用的方法。
5. 基于考试结果的证据
与测试项目有关的后果是积极的还是消极的,也可称之为测验的反拨作用。
AUA理论框架
目前比较热门的测试理论是“测试使用论证”框架(Assessment Use Argument,简称AUA),该框架由Bachman和Palmer在2010年提出。它尝试解释了测试开发与使用的整个过程,并对开发者和使用者都具有指导意义(韩宝成、罗凯洲,2013)。整个AUA的运行机制如下图所示:
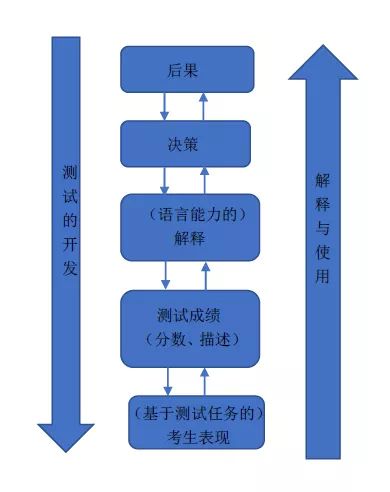
AUA框架(韩宝成、罗凯洲,2013)
测试的使用以及基于测试的决策都会给相关人员(如考生、家长、教师、机构等)带来影响,高风险测试的影响尤大(韩宝成、罗凯洲,2013),所以AUA看重对测试(测试分数、决策及测试本身)使用合理性的论证,并非仅仅解读分数。同时,AUA强调在现实世界中(特别是通过衡量“后果”)评价一项测试的有用性,测试者不能仅凭冰冷的统计数字就对学生能力盖棺定论。