索引优化是查询优化中最重要的一部分,索引是一种用于排序和搜索的结构,在查找数据时索引可以减少对I/O的需要;当计划中的某些元素需要或是可以利用经过排序的数据时,也会减少对排序的需要。某些方面的优化可以适度提高性能,而索引优化经常可以大幅度地提高查询性能。
一、表和索引的结构
1.1 页和区
页是MSSQL存储数据的基本单位,大小为8KB,是MSSQL可以读写的最小I/O单位。=> 即使只访问一行,MS SQL也会将整个页加载到缓存,再从换从中读取数据。
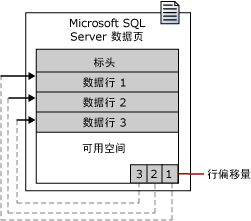
区是由8个物理上连续的页组成的单元。=> 当表或索引需要更多空间以存储数据时,MSSQL会为对象分配一个完整的区。
为了使空间分配更有效,SQL Server 不会将所有区分配给包含少量数据的表。MSSQL有两种类型的区:混合区和统一区,区别详见参考资料(4)。

PS:看来MSSQL比较喜欢8这个数字。此外,我们需要了解的就是I/O操作中开销最大的部分是磁盘臂(Disk Arm)的移动,而真正的磁盘读写操作的开销要小得多;因此,读取一个页和读取整个区所用的时间几乎一样长。
1.2 表的组织方式
堆(Heap)
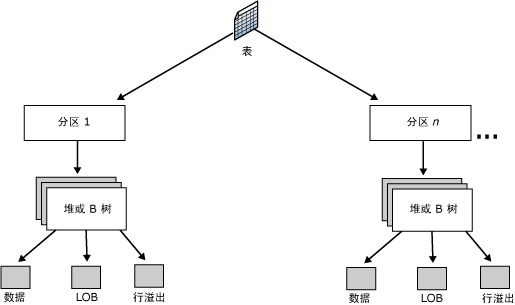
堆是不含聚集索引的表(所以只有非聚集索引的表也是堆),因为它的数据不会按照任何顺序进行组织,而是按分区组队数据进行组织。=> 当你使用SELECT语句访问堆表时,MSSQL在执行计划里会使用表扫描(Table Scan)运算符,因为你没有定义合适的聚集索引。表扫描意味着你必须扫描整张表,不以你表拥有的数据量来衡量。你的数据量越多,操作花费(时间)越长。
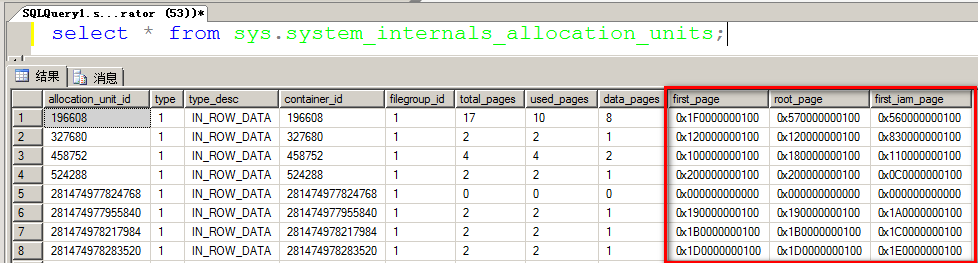
在堆中,有一个索引分配映射(IAM)的位图页用于保存数据之间的关系,在下图中,MSSQL维护着指向第一个IAM页和堆中第一个数据也的内部指针。

这些指针可以在系统视图sys.system_internals_allocation_units中找到。
B树
MSSQL中的所有聚集索引都是按照B树结构组织的,B树中的每一页称为一个索引节点。每个索引行包含一个键值和一个指针。指针指向B树上的某一中间级页(比如根节点指向中间级节点中的索引页)或叶级索引中的某个数据行(比如中间级索引页中的某个索引行指向叶子节点中的数据页)。每级索引中的页均被链接在双向链接列表中。数据链内的页和行将按聚集索引键值进行排序,聚集索引保证了表格的数据按照索引行的顺序排列。

二、索引的访问方法
2.1 表扫描/无序聚集索引扫描
表扫描/无序聚集索引扫描是对表的所有数据页进行扫描。下面的查询就对Orders表(结构化为堆,因此查询之前需要首先删除该表的聚集索引)执行表扫描:

运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:
-- clear cache dbcc dropcleanbuffers; -- statistics io set statistics io on; -- statistics time set statistics time on;

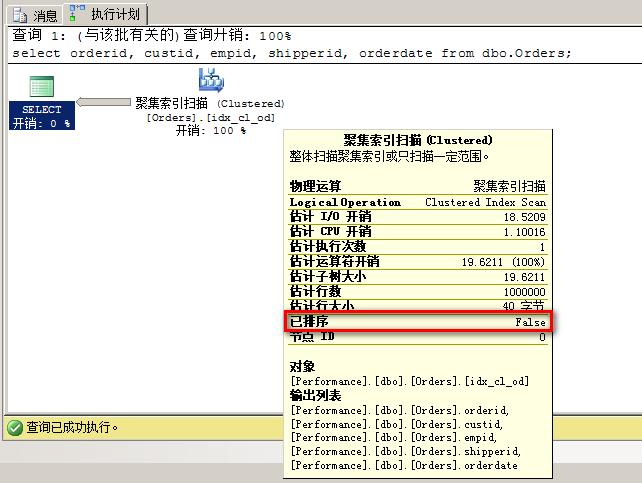
如果该表包含聚集索引,那么采用的访问方法将会是无序聚集索引扫描(Clustered Index Scan运算符,其Ordered属性为False)。下图展示了优化器为该查询将生成的执行计划。
这里首先给Orders表加一个聚集索引。
-- add clustered index for Orders create clustered index idx_cl_od on dbo.Orders(orderdate);
再次查看执行计划,从表扫描变成了聚集索引扫描。这里可以看到其中已排序这个属性为False,就关系引擎来说,该运算符不需要返回有序的数据。(即返回任何顺序的数据都没有问题)
运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:

可以看到,表扫描和无序聚集索引扫描的查询效率差不多的。
2.2 无序覆盖非聚集索引扫描
无序覆盖非聚集索引扫描类似于无序聚集索引扫描,覆盖索引的概念表示非聚集索引包含在查询中指定的所有列中。MSSQL只需要访问索引数据就可以找到满足查询所需的全部数据。
这里我们来看看下面的查询,假设我们之前在Orders表的orderid列上建立了一个非聚集索引PK_Orders(主键),即所有orderid都处于索引的叶级。因此,索引覆盖了这个查询。
-- pk_orders select orderid from dbo.Orders;
其执行计划如下图所示:
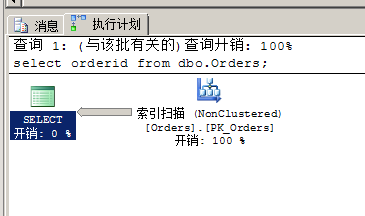
运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:

可以看到,逻辑读取次数减少了近10倍,而执行时间减少了一半。
2.3 有序聚集索引扫描
有序聚集索引扫描是针对聚集索引的叶级执行的一种完整扫描,可以确保按照索引顺序为下一个运算符返回数据。
例如,下面的查询请求按orderdate排序的所有订单:
-- ordered clustered index scan select orderid, custid, empid, shipperid, orderdate from dbo.Orders order by orderdate;
其执行计划如下图所示,可以看到这次已排序属性值变成了True。这就表示,从运算符返回来的数据应该是有序的,而且存储引擎只能以索引顺序扫描。
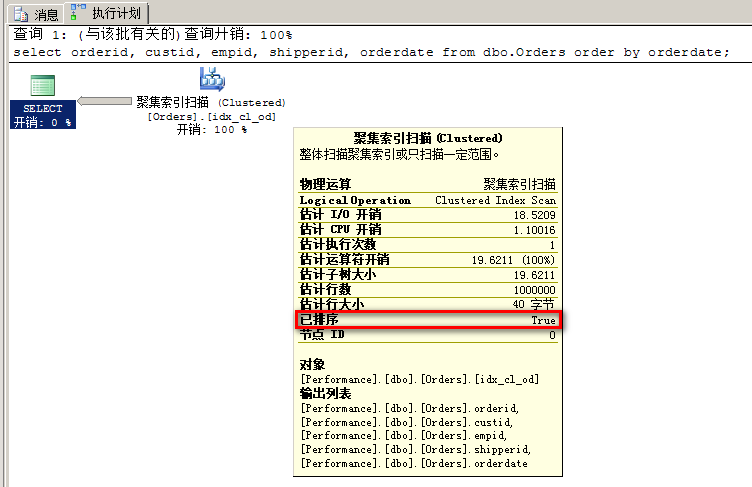
运行这个查询后,通过STATISTICS IO, STATISTICS TIME得到的性能指标如下所示:

可以看到,查询效率和表扫描、无序聚集索引扫描差不多,执行时间略多于前两者。
参考资料

(1)[美] Itzik Ben-Gan 著,成保栋 译,《Microsoft SQL Server 2008技术内幕:T-SQL查询》
(2)Hyber Wang,《重新理解SQL Server的聚集索引表与堆表》
(3)悉路,《SQL Server性能优化(8)堆表结构介绍》
(4)Microsoft TechNet,《TN 页和区》
(5)xwdreamer,《Sql Server中的表组织和索引组织(聚集索引结构,非聚集索引结构,堆结构)》
作者:周旭龙
出处:http://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。