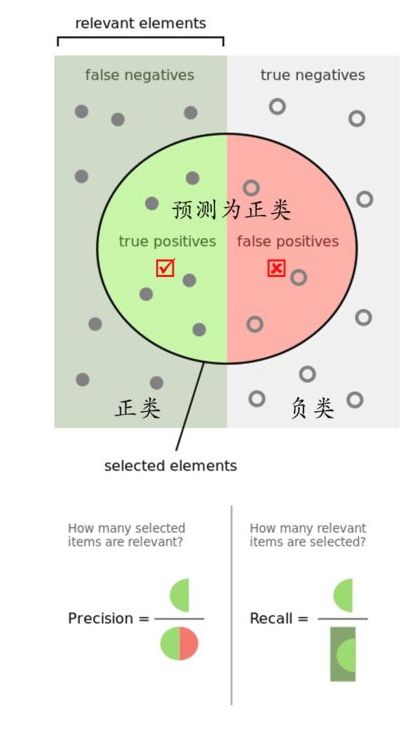
首先明确几个概念,精确率,召回率,准确率
- 精确率precision
- 召回率recall
- 准确率accuracy
以一个实际例子入手,假设我们有100个肿瘤病人. 95个良性肿瘤病人,5个恶性肿瘤病人. 我们有一个检测系统,去检测一个肿瘤病人是否为恶性.
那么,对我们的系统来说,有100个样本,5个正样本,95个负样本.假设分布为1,1,1,1,1,0,0,.......(即前5个人为恶性,后95个为良性).
假设我们的系统预测如下1,0,0,1,1,1,0.......,可以看到我们把第二个第三个恶性预测为了良性,第6个良性预测成了恶性.
我们一共做出了100个预测,错误3个,正确97个.一共预测4个恶性,其中3个正确,1个错误.
先看最简单的指标,准确率accuracy.即所有预测的正确率=97/100=97%.
再看精确率precision,对于我们预测结果为恶性的来说,我们共做出了4个恶性的预测,对了三个,精确率=3/4=75%.
再看召回率recall,对于真正的恶性病人(共5人)来说,我们做出了5个预测,其中对了三个,召回率=3/5=60%.
从上面的例子可以看出来,precision是针对我们的有意义预测而言(这个表述不是很准确,用以通俗的理解.什么叫有意义的预测?,比如对癌症预测系统而言,这个系统的目标是检测出患癌症的,所以预测结果为患癌就叫做有意义预测)的,在所有的有意义的预测里,正确的比例就叫precision.
recall是针对样本的,即所有的患癌症患者,被检出的概率就叫recall.
总结一下就是:
precision就是你以为的正样本,到底猜对了多少.
recall就是真正的正样本,到底找出了多少.
到底是precision高好还是recall高好,要看你的检测系统的具体目标.比如:
垃圾邮件检测
我们希望做出的检测都是足够精确的,尽可能的检出的垃圾邮件都是真的垃圾邮件,不要把有用的邮件检测为垃圾邮件!,比如一封十分重要的工作邮件被检测成了垃圾邮件,这是不能容忍的. 而一个真正的垃圾邮件,我们没有检测出来,没有关系,我手动删掉就好了. 这种情况下,precision就要尽可能高.癌症检测
我们希望真正的癌症病人要尽可能第被检测到,比如,一个人患了癌症,但是我们没检测到,耽误了治疗的最佳时机,这是不能容忍的. 而一个良性的病人被误检测为癌症,没有关系,我们后续还有更多的医疗手段确定这个人是不是真的癌症. 这种情况下,recall就要尽可能的高.
上面假设了2个比较极端的例子,实际上,很多时候我们需要在precision和recall之间找到一个折中和平衡.
mAP
先来说AP (Average Precision)
以一个实际例子,来说明AP的计算.比如我们有1000张图片,其中5张是苹果,我们预测的结果是其中某十张是苹果.目标检测系统不光会给出某张图的类别,还会给出相应的概率.
我们按照概率从大到小对我们的预测降序排列.
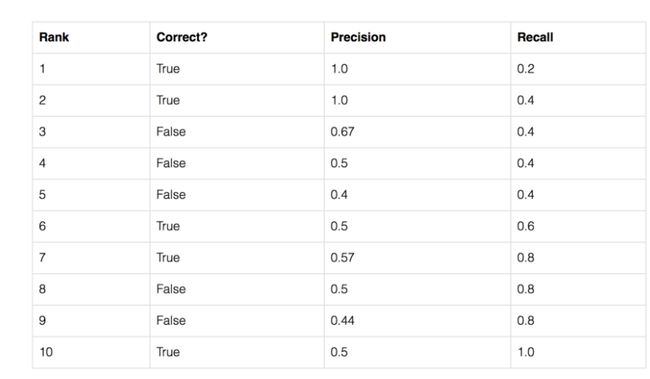
以第三行为例,解释一下,当做出第三行的预测时,此时预测对了2个,预测了3次,真正的苹果图片一共5个,所以precision=2/3=0.67, recall=2/5=0.4.
这样的话,我们可以绘制出下图:
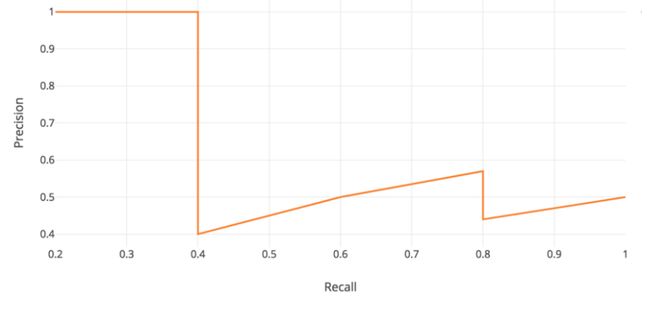
此时的曲线是"之"字型下降的.结合上表,很好理解,recall肯定是不断增大的.precision会有"抖动".
AP的定义即为recall-precision下的面积.
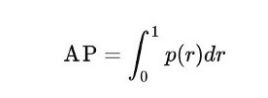
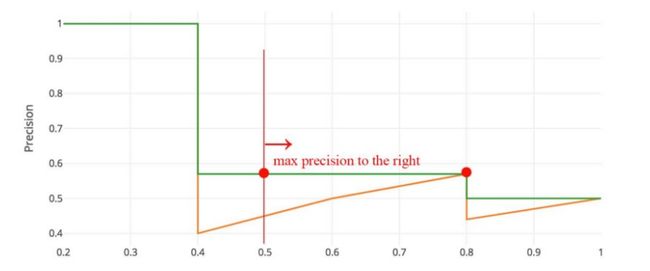
实际计算的时候,我们通常先调整某个recall点对应的precision为其右侧的最大值.
即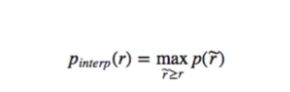
PASCAL Visual Objects Challenge从2007年开始就是用这一度量制度,他们认为这一方法能有效地减少Precision-recall 曲线中的抖动.
AP的意义:AP综合考量了recall和precision的影响,反映了模型对某个类别识别的好坏.
mAP是取所有类别AP的平均值,衡量的是在所有类别上的平均好坏程度。