GitHub
Part1:PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 1200 | 1500 |
| Developm | 开发 | 300 | 500 |
| Analysis | 需求分析(包括学习新技术) | 170 | 180 |
| Design Spec | 生成设计文档 | 50 | 60+ |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 15 | 15 |
| Design | 具体设计 | 50 | 100 |
| Coding | 具体编码 | 250 | 500 |
| Code Review | 代码复审 | 20 | 40 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 200 |
| Reporting | 报告 | 50 | 50 |
| Test Report | 测试报告 | 100 | 100 |
| Size Measurement | 计算工作量 | 100 | 100 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 20 |
| 合计 | 1385 | 1655+ |
Part2:计算模块接口的设计与实现过程
设计过程:
看到这个题目的一瞬间,很容易就能想到用正则表达式去弄,写py的小伙伴们应该是最轻松的。
但是这样搞不就显得有些无聊了吗?所以我果断选择用上我最爱的C++。(虽然写这道题的C++代码相比起Java和Py简直是噩梦难度......
首先第一关就是文件的读写。题目要求在utf-8格式下读写文件,而C++不支持直接使用utf-8格式,读进来的全是乱码。但是这个问题说难也不难,百度一下,花点时间上网查一查库函数就能搞定了。
然后第二关就是地址的解析。因为想好了不用正则的,regex啥的就算了吧。那么此时又有一种很简单的做法,就是特判,疯狂特判。考虑到只有前两级的地址后缀会出现缺失,所以最裸的特判思路就只要打出省市的表即可。当然这种做法甚至比正则表达式还无聊而且费力。所以考虑上一些字符串匹配算法,最开始想的是Trie,但是内存可能会爆炸(虽然后来发现并没有问题),所以先用KMP试了试宽字符类型的匹配,是可以的,于是就去找了据说对于随机数据效果最优的Sunday算法。
第三关当然就是附加题的解决方法了。有了匹配算法,那么还需要一个地址信息库才能做补全。既然用了C++就得追求效率对吧?所以联网调用API啥就算了(其实是因为我不会),于是先爬来一个国家统计局的行政区划json文件。看着这个json我又陷入了沉思,要自动解析json的话得用第三方库,而且远不如Py和Java方便,当时负责评测的ymz大佬又在疯狂改需求,说什么没有动态链接库,没有本地文件之类的,于是就放弃了jsoncpp,决定自己造轮子搞一搞。
最开始因为不支持本地文件,所以很自然的想到打表存到代码里的操作,每次启动程序就初始化整个层级的结构,然后从根开始直接查。(甚至可以直接map)但这样的话代码文件会非常巨大,而且每次重新编译都要花费很多时间,虽然很省事,但我还是放弃了。之后的转机是杰哥在群里和ymz进行了一番深♂入的交流,终于让ymz重构评测代码,取消了没有本地文件的限制。如此一来,我根据json的递归性想到了一个很奇葩的操作,可以不通过漫长的初始化,就可以进行层次结构的查询。
算法关键:
为什么不把数据结构存在文本里呢?XD
对文件名进行编码。0代表根节点,0.X代表省级行政区,0.X.X代表市级行政区,0.X.X.X代表县/区级行政区,0.X.X.X.X代表街道/镇/乡级行政区。每个文件的内容就算对应编码的若干层子节点。
例如: 0a0文件存着所有省级行政区,0a1文件存着所有市级行政区,0.12a0文件存着福建省所有的市级行政区,0.12a1文件存着福建省所有县级行政区。
(a表示该层相对向下a层的位置)
文件内的存放格式如下;父亲编号+地址名称+地址编号;
例:;0.12.0鼓楼区0.12.0.0;
写了个dfs去处理这些文件(跑完之后生成了3000+文件):
int searchFiles(const wstring& wstr, int curIdx, int curLev, int curId, string preId) {
for (int i = curIdx; i < (int)wstr.size(); i++) {
if (wstr[i] == '[') {
string nowId;
if (curLev) nowId = preId + "." + intToString(curId - 1);
else nowId = "0";
for (int a = 0; a <= 3 - curLev; a++) {
if (wfout[curLev][a]) wfout[curLev][a].close();
wfout[curLev][a].open(tableFileName + nowId + "a" + intToString(a) + ".in");
wfout[curLev][a].imbue(locale("chs"));
wfout[curLev][a] << L';';
}
i = searchFiles(wstr, i + 1, curLev + 1, 0, nowId);
}
else if (wstr[i] == ']') {
return i;
}
else {
if (wstr[i] > 255) {
int len = 0;
wstring addr;
while (wstr[i + len] > 255) {
addr.push_back(wstr[i + len++]);
}
wstring nowId = stringToWString(preId) + L"." + stringToWString(intToString(curId));
for (int a = curLev - 1; a >= 0; a--) {
wfout[a][curLev - a - 1] << stringToWString(preId) << addr << nowId << L';';
}
curId++;
i += len;
}
}
}
return -1;
}有了编码之后我们就可以在程序运行的时候通过查文件的方式去搜索,甚至不用初始化,唯一影响效率的地方可能就算文件读写的开销了,估计也不会很大,因为只有前4层需要调用文件进行搜索。(然而被之后的性能分析教育了)
搜索时使用到的Sunday算法:(平均时间复杂度O(N))
Sunday算法由Daniel M.Sunday在1990年提出,是一种思想和BM算法很相似的字符串匹配算法。
Sunday算法和BM算法最大的不同在于从前往后进行匹配,匹配失败时跳转到文本串中进行匹配的最后一位字符的下一位。
这个算法的思想其实很简单,下面是匹配过程:
+ 若当前字符未在模式串中出现则跳过,移动位数W = 模式串长度LenP + 1
+ 否则,移动位数W = 模式串长度LenP - 该字符最右出现的位置Bit[S[i]]总体算法简略流程图:
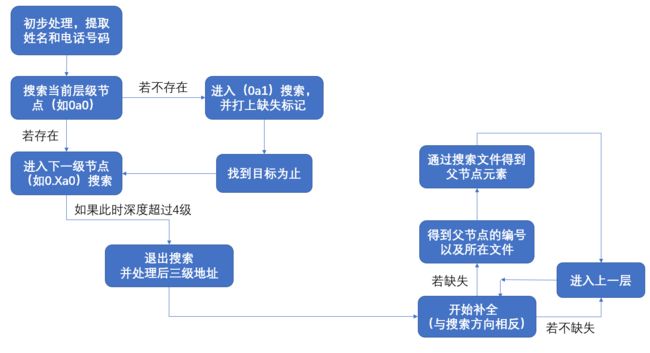
处理两个例子的流程图:
**输入:**
2!王五,福建鼓楼18960221533区五一北路123号福州鼓楼医院.
**初步处理出地址部分:**
福建鼓楼区五一北路123号福州鼓楼医院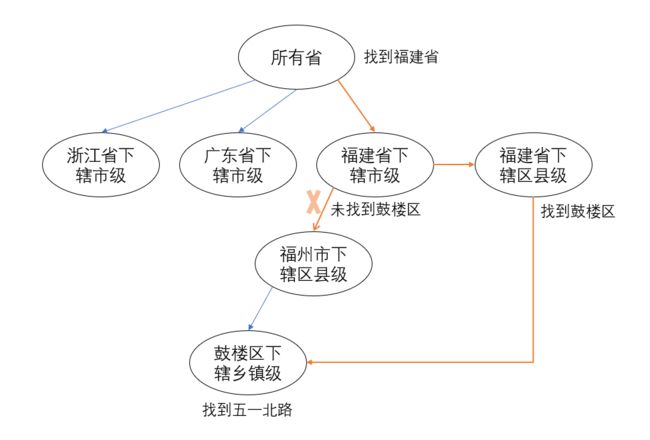
**输入:**
3!王五,18960221533五一北路123号福州鼓楼医院.
**初步处理出地址部分:**
五一北路123号福州鼓楼医院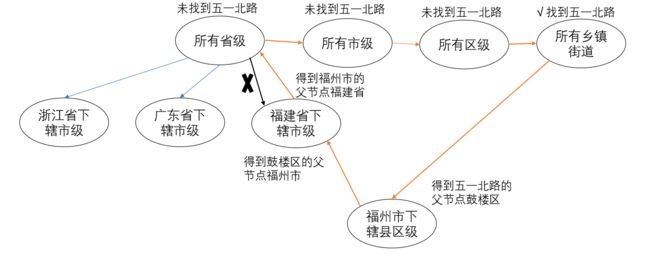
类图:
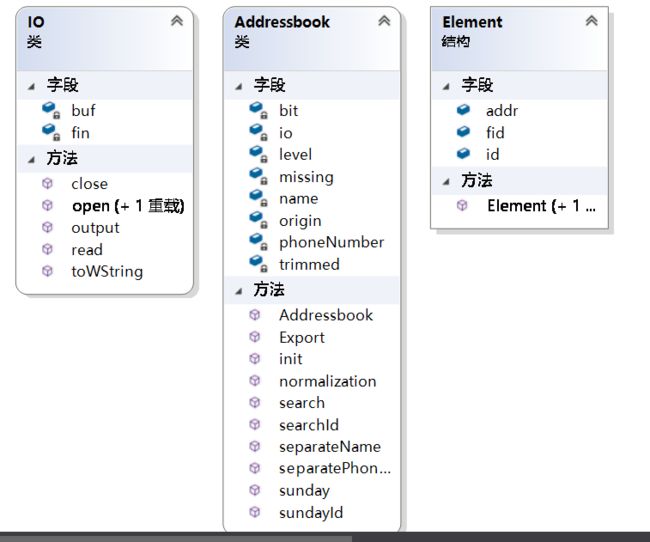
关于代码组织与关系:
IO负责搞定烦人的utf8, Addressbook负责搞定地址信息的存储和补全。
Element则是定义文件里存储的元素
Addressbook里的normalization为全部的规范化操作。separateXX函数负责进行名字和电话号码的分离。search和sunday为算法核心,因为要大量使用本地文件,所以内部也一直在使用IO类的实例方法。
另外还有一个全局功能性函数文件fun.cpp,里面提供了一些类型转换的函数,以及我生成数据的dfs代码,因为类型较杂就不聚合成类了。
这样一来,跑完一遍就处理出所有的三个难度的答案了,之后按需输出即可。可惜如果正好缺失了第四级,我的程序就无法进行补全了,因为这需要第五级的信息,而国家统计局没有第五级之后的信息。
所以最后用yf大佬的数据跑出来的结果是1094/1130,果然还是错了36个点,应该几乎都是第四级缺失并要求补全的情况了。
Part3:计算模块接口部分的性能改进
跑大概100组数据的性能分析图:
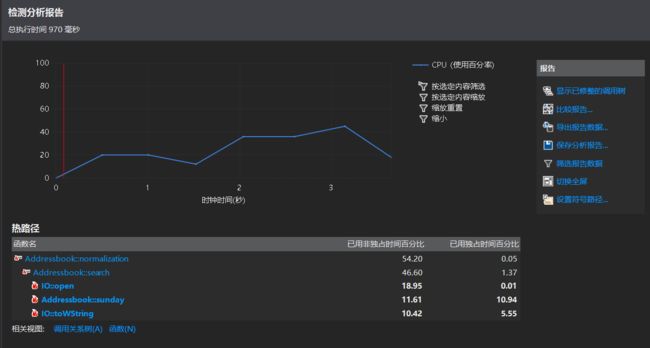
首先测试数据的读入和答案的输出肯定是开销里的大头,然而真的没想到搜索过程中文件操作(IO::open)是花费最大的函数。比我的匹配算法(sunday)运行的时间还要久。而且string的各种转换也占了很大的开销(IO::toWString)。
于是尝试进行了一些常数优化,其实也就是减少拷贝构造,减少string和wstring的转化,尽量统一使用宽字符等等。
在IO部分,最主要的开销在读取文件中的内容上,而且对于多组数据会需要重复读入,这显然不合理。于是解决方法也很简单,就用wstring数组先保存下来,记录一下,但需要访问已经读取过的文件时,直接调用对应的wstring。
Part4:计算模块部分单元测试展示

先简单地测试一下电话号码的分离。
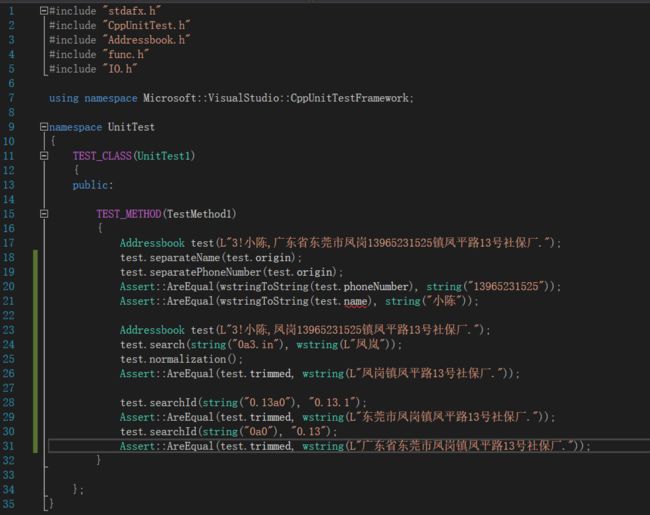
再让姓名和电话同时进行分离测试。
另外对于每一层级的搜索都依次对应测试,这样构造测试数据的思路是为了测评每一层级的具体开销与实际运行情况,测试的函数也是Addressbook类的相应处理方法。
在单元测试中,居然出现了std::bad_alloc错误,而且内存使用量很奇怪,翻了翻代码,原来是搜索算法函数里的一个new出来的数组忘了delete,之前都没有问题,怀疑是VS自动智能释放了内存。bug++
代码覆盖率:
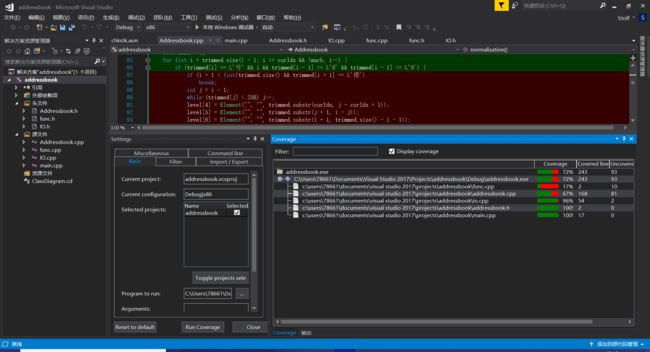
可以看到重要的几个类中的函数在测试中都有被很大程度上覆盖到,而func.cpp中的是一些全局的功能性函数,一般只在读取数据写入答案时用到,所以覆盖率较低。
Part5:计算模块部分异常处理说明
因为中国地名的规则多样性确实很强,我不得不一次次去打扰yf大佬问数据。虽然他保证不会有很奇怪的数据,但我还是想到了好多例子,下课回宿舍的路上走一步就能想到一个的程度。这时候就很怀念ACM的题了,数据范围清晰,需求明确。
举一个例子:
小知识:中国唯一一个省市同名的吉林省吉林市。
**输入:**
3!我是谁,吉林乌林朝鲜族乡13365031138北京路203号社保厂.
**输出:**
[{
"姓名": "我是谁",
"手机": "13365031138",
"地址": ["吉林省", "吉林市", "蛟河市", "乌林朝鲜族乡", "北京路", "203号", "社保厂"]
}]这个样例中,如果是1或者2的难度,就存在多解,反而是3难度下可以有答案。我可以在代码里进行一些有歧义情况下异常处理(其实问题大多出在歧义上),比如访问到下级节点的时候再往下搜索一级,看看是否还有结果。
再举一个例子:
某一层的地址名包含前一层地址名的前缀:
**(非真实数据)输入:**
3!我是谁,福建福州闽侯县经济开发区13365031138南京路213号社保厂.
**(假设)输出:**
[{
"姓名": "我是谁",
"手机": "13365031138",
"地址": ["福建省", "福州市", "闽侯县", "经济开发区", "南京路", "213号", "社保厂"]
}]这也是一种歧义情况(因为我们假设闽侯县经济开发区是四级行政区划),但却是可以解决的,我们可以搜索一下闽侯县的下级节点,看看是否真的有“经济开发区”,如果没有那第三级就是空的了。(不过yf大佬说没有这种数据,我就不管了)
不过这个例子也让我想到另一种情况,于是设计了搜索部分的一种异常处理,即当搜索出来的结果和接下来的字符不对应时进行错误报告。本来我以为应该没什么问题,因为如果该层搜索结果唯一对应某一地址名,那应该就是答案啊,但我果然还是太天真了。测试的时候发现,福州闽侯县上街镇这样的数据里的福州居然跑到省级上去了。瞬间发现是我蠢了,福字在省级里唯一对应福建省,于是福州就取代了福建的位置XD~ 然后特判一下就解决了
还有一个例子:
新疆的自治区直辖县以及东莞的市直辖镇等等中间直接空掉一级的特殊情况。
**输入:**
3!小陈,广东省东莞市凤岗13965231525镇凤平路13号社保厂.
3!我是谁,石河子市13365031138南京路213号社保厂.
**输出:**
[{
"姓名": "小陈",
"手机": "13965231525",
"地址": ["广东省", "东莞市", "", "凤岗镇", "凤平路", "13号", "社保厂"]
}, {
"姓名": "我是谁",
"手机": "13365031138",
"地址": ["新疆维吾尔自治区", "", "石河子市", "", "南京路", "213号", "社保厂"]
}]
这里新疆下面直接没有市级,东莞下面直接没有了县级。分别属于省直辖县和市直辖镇,我在搜索的时候因为下级节点缺失直接跳过,导致凤岗镇出现在第五级。通过在处理后三级地址部分设置的异常处理,对后三级在0a3这个保存全中国前四级行政区划的文件中搜索,发现有匹配成功的,发现了该错误。另外新疆这个数据存在第四级缺失,所以我的程序无法补全这一级。
以及一些没说清楚的例子:
因为后三级定义不明确,所以存在没说清楚,无法确定唯一的情况。处理起来就只能多进行特判。
**输入:**
3!荣户掂,春华街道华腾里9号楼13708570358.
**输出:**
[{
"姓名": "荣户掂",
"手机": "13708570358",
"地址": ["天津", "天津市", "河东区", "春华街道", "", "", "华腾里9号楼"]
}]
**输入:**
3!娄伤囚,所前13592755594镇袄庄陈村工业园区5号楼.
**输出:**
[{
"姓名": "娄伤囚",
"手机": "13592755594",
"地址": ["浙江省", "杭州市", "", "所前镇", "袄庄陈村工业园区5号楼"]
}]那么华腾里到底是道路还是详细地址呢?如果我把里这个后缀作为道路的判断,那么很容易出现错误,比如东华路213号八里屯娱乐中心,继而也能联想到,后缀可能本身就作为道路的名称存在,所以最好还是从后往前的遍历寻找。
要完美的解决这个问题还是得完完整整地爬下全部的中国地图数据啊~
总结
感觉这次作业最大的收获不是代码能力,而是对中国行政区划的深入了解。。。
本来是抱着C++效率高的心态来玩一玩的,结果最后千辛万苦写好了发现效率远不如预期,真的难受,下次还是用开发效率高的python吧(当然少用点string大概还是有救的)
总而言之每次想要认真去做点什么,都会发现自己要学的东西还有很多啊。但不得不说敲代码是真的敲得很爽,即使连续两天看到凌晨五点半点的福大,累到想吐,也确实挺满足的。
特别是最后跑出49.3/50的分数的时候XD