1.JDBC是怎么访问数据库的?
答:JDBC编程有6步,分别是1.加载sql驱动,2.使用DriverManager获取数据库连接,3.使用Connecttion来创建一个Statement对象 Statement对象用来执行SQL语句,4.执行SQL语句,5.操作结果集,6.回收数据库资源
2.MyBatis是怎么访问数据库的?
答:1导入架包;
2创建实体类对象;
3 创建mybatis的配置文件mybatis-config.xml;
4创建上面的TuserMapper.xml(Sql映射文件);
5 创建test类进行测试;
3.MyBatis和JDBC访问数据库有什么区别?
答:MyBatis具有以下一些特点:简单易用、性能高效、保留SQL、开源框架。
2可以自定义SQL、存储过程和高级映射的持久层框架
3. 优化获取和释放;SQL统一管理,对数据库进行存取操作;生成动态SQL语句;能够对结果集进行映射
总结:
一:
当dataSource的类型是POOLED时,还额外有以下常用属性。
poolMaximumActiveConnections,连接池最大活动连接数,默认值10
poolMaximumIdleConnections,连接池最大闲置连接数
poolMaximumCheckoutTime,连接“离开”连接池的最大时间,默认20秒
二:
MyBatis编程实现数据访问,关键步骤如下:
编写MyBatis配置文件mybatis-config.xml
编写接口映射文件XxxMapper.xml文件
使用Resources工具类读取mybatis-config.xml配置文件
实例化SqlSessionFactoryBuilder对象并调用build方法初始化MyBatis框架
通过SqlSessionFactory打开SqlSession会话对象
使用SqlSession对象的数据操作方法完成数据操作
关闭SqlSession会话对象

自定义配置别名:
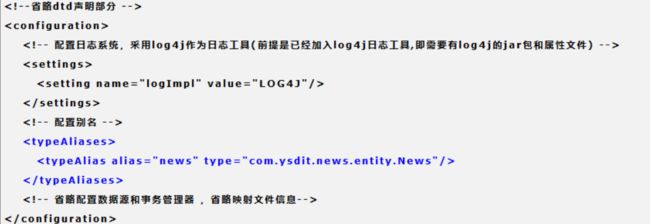
如果要引用类的别名:要用注解@Alias("");

什么是单向多对一?请举出一个现实例子。
答:以班级有多少学生 ;
什么是双向一对多?请举出一个现实例子。
答:一个学校有多少个班级;,

Mybatis在增删改操作的时候需要注意什么?与之前的JDBC相比发现了什么优点?
答:表之间的数据关系;以及数据与数据之间的关系 ;
返回类型的以及参数的配置问题;
代码中最重要的一点,可扩展性,mybatis连接数据库的用户密码等都是写在配置文件中,即使数据库有更改,java代码也不需要重新编译。
mybatis的连接池管理,缓存管理等对于数据库的访问优化更好
只需要一个接口,一个xml就可以访问
哪些标签?各有什么需要注意的地方?
答:if where;choose分支结构 otherwise
trim、where和set替换 :foreach
MyBatis提供了更智能化的动态SQL标签支持,那就是
prefix:前缀替换或新增内容,即替换后的前缀
prefixOverrides:前缀匹配条件,即要被替换掉的前缀
suffix:后缀替换或新增内容,即替换后的后缀
suffixOverrides:后缀匹配条件,即要被替换掉的后缀
执行原理:当trim标签内容SQL不为空时,对SQL的前后缀处理是,首先会删除前后缀匹配条件匹配到的内容,然后增加替换后的前后缀内容。
set元素将动态的配置SET关键字,也用来剔除追加到条件末尾的任何不相关的逗号。可以简单的理解为set标签内容不为空,则给内容前加set 内容后去逗号(,)。
比如上述步骤二中的蓝色加粗标注代码中trim的写法全等于where标签。可以简单的理解为where标签内容不为空,则先去掉内容前的and,or等,再在内容前加where。
四:foreach循环
collection:需要遍历的集合,其取值有三个:array,list,map
item:迭代过程中每个元素的别名
index:在迭代过程中,当前位置的索引下标
open:开始
separator:分割符
close:结束
集合由collection属性指定,而如果传入参数是java.util.List 这里固定写法 collection="list" 或者 collection="collection"。内容可以被前后包围,其开始符号由open属性指定,结束符号用close属性指定,多个单值参数内容的分隔符由separator指定。如果需要产生IN子查询,那么以“(”符号开始,“)”符号结束,内容用“,”号分隔。
做添加、修改、删除、查询的时候会用到哪些标签?
答: insert update select delete
1 什么是缓存?
答:缓存在数据库密集访问型的应用系统中被广泛采用,基本思想是,为了减少数据库的负荷,使用缓存存储热点数据,使得上层应用在不需要访问数据库的情况下通过缓存直接获得数据,对用户做出快速响应
缓存分为几种?分别是什么?工作原理大概是什么?
答:缓存分为本地缓存和分布式缓存。如果缓存在应用内部,部署在应用所在的硬件服务器上,那么称此类缓存为本地缓存;反之,缓存是独立部署的,并且与应用系统不再相同的硬件服务器上,则称为分布式缓存。
二级缓存是跨多个会话的,MyBatis内置了一个二级缓存(PerpetualCache),可以直接使用。也可以使用其他缓存产品作为二级缓存,例如EhCache。如果选用的二级缓存产品是独立部署的,例如是Redis服务器,那么此时的二级缓存又是分布式缓存。
如果想用到缓存技术,应该怎么去配置?
答:
Redis安装:
字符串类型数据的常用操作命令如下所示。
♦set key value,添加或替换(修改)字符串键值对,例如set uname tomcat
♦ get key,查询一个键的数据,例如get uname
♦ del key,删除一个键数据
散列(Hash)类型,值是键值对的类型,适合在Redis中存储含有多个属性的对象。对于散列类型的操作命令如下所示。
♦ hset/hget,存取散列值,例如hset stu01 name 'tom',stu01具有name字段,值分别为tom。
♦ hmset/hmget,一次存取多个字段,例如hmset stu name 'abc' age 10。
♦ hgetall,读取所有字段。
♦ hdel,删除某个字段。
步骤1,服务器端 安装及启动
1.解压缩windows绿色版redis压缩包到D盘下,并重命名为redis
2,使用命令窗口启动redis数据库
切换到 D盘下 d: 或者 cd /d d:
切换到redis目录下 cd redis
启动数据库 redis-server.exe 或者 redis-server.exe redis.windows.conf
当显示数据库和等待连接的端口号,说明启动成功.保持该命令窗不要关闭.
步骤2,客户端连接测试
新打开一个命令窗口.使用客户端验证启动成功.(这时候另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了。)
切换到 D盘下 d: 或者 cd /d d:
切换到redis目录下 cd redis
登录客户端 redis-cli.exe 或者 redis-cli.exe -h 127.0.0.1 -p 6379
新增数据 set myKey abc
查询数据 get myKey
以上是Redis数据库服务器和客户端在命令行窗口中的操作指令。
其它一些删除数据的指令:
del myKey:删除一个键
flushdb:删除这个db下的。
flushall:删除所有
select index 切换数据库
MyBatis默认是开启二级缓存的,可以通过全局参数cacheEnabled进行开关。如果需要关闭二级缓存,可以在mybatis-config.xml文件中编写如下配置代码。
仅仅在mybatis-config.xml配置文件中开启二级缓存还不够,还需要在接口隐射文件中使用
4.二级缓存的池化技术?
答:添加jedis库、mybatis-redis库以及commons-pool2库,共三个jar。
其中jedis库是java对Redis数据库的jdbc驱动,是Java程序访问Redis的库文件。
mybatis-redis是MyBatis框架访问Redis的库,它需要依赖jedis。
commons-pool2是对象池技术,对象池化主要用于减少对象在创建和销毁上面的开销,
如果是小对象则不需要池化,如果是大对象可以考虑池化,对于像数据库连接、网络之类的重对象来说是很有必要的

♦type,指定缓存产品,本例为org.mybatis.caches.redis.RedisCache。如果缺省,则使用MyBatis内置的PerpetualCache。
♦eviction,被缓存对象的清除算法。常见的有LRU – Least Recently Used,最近最少使用算法;FIFO – First In First Out,先进先出算法。默认值为LRU。
♦flushInterval,按照某种清除算法执行缓存清除的时间间隔,单位为毫秒。无默认值,缺省该值说明缓存不会在制定的时间内刷新,只有到SQL语句执行完毕后才刷新。
♦size,缓存大小,任意正整数。默认值为1024。
♦readOnly,只读缓存。如果是只读缓存,所有数据使用者均得到相同的缓存对象。存在对象数据被破坏的情况,但是效率最高。默认值为false,说明是读写缓存,数据使用者得到的是缓存对象的一个副本,数据比较安全。
5.索引的使用情况来总结一些优化经验;
经验1,尽量避免在where子句中使用is null比较,即使比较字段建立了索引,数据库也会放弃使用索引,因为索引中没有null值。所以在设计表时,尽可能不要有null字段。例如奖金字段,如果用null来表示未发放,可以考虑定义一个-1表示未发放。
经验2,尽量避免在where子句中使用not、<>或者!=操作,否则数据库也会放弃使用索引。
经验3,尽量避免在where子句中使用or操作,如果有未建立索引的列参与or运算,数据库会放弃使用索引。可以考虑union合并结果
经验4,尽量避免使用in、not in操作,数据库会放弃使用索引,可以用union、between...and或者exists替代,。
经验5,尽量避免使用百分符号在前的like查询,如like ‘%abc%’。
经验6,尽量避免在where子句中对查询字段进行类型转换、函数计算和表达式计算,否则数据库会放弃使用索引。
经验7,谨慎使用复合索引,如果where子句中,条件字段不是复合索引的首字段,数据库会放弃使用索引。
经验8,尽量避免使用count(*),应该把主键字段作为count函数的参数。