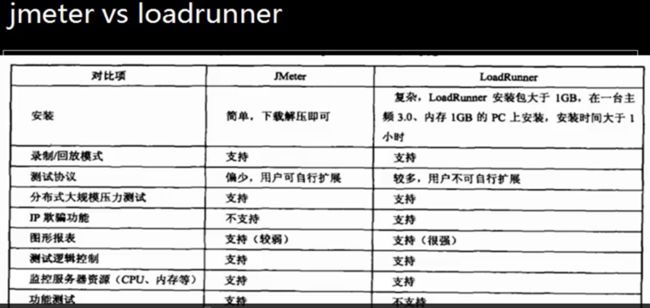
1、工作原理

为Jmeter安装PerfMon插件
JMeter本身对这些信息是不做收集的,这个时候PerfMon就应运而生了。没错,他就是用来收集被压服务器的各种性能指标,例如:CPU,
Memory, Swap, Disks I/O and Networks I/O……
进入正题:
环境搭建
1、下载jmeter,进行解压
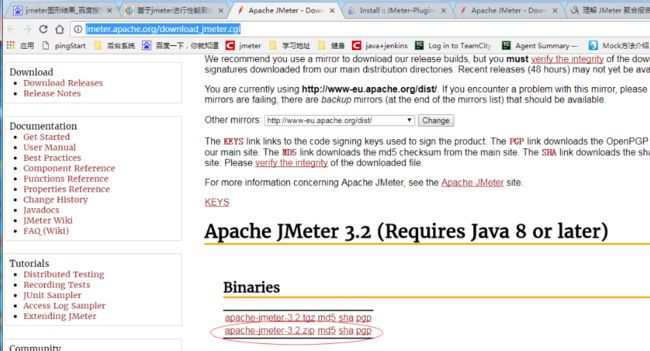
2、安装Jmeter插件:http://www.jmeter-plugins.org/install/Install/,下载后将plugins-manager.jar放到jmeter客户端的jmeter/lib/ext下
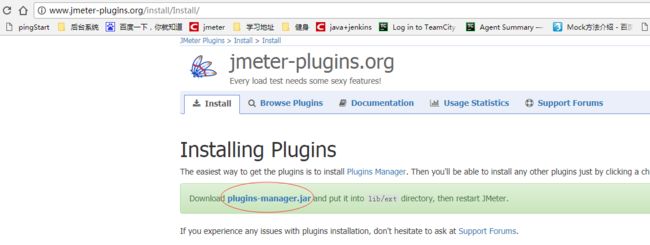
2、将plugins-manager.jar放到jmeter客户端的jmeter/lib/ext下
运行jmeter,查看插件是否安装成功
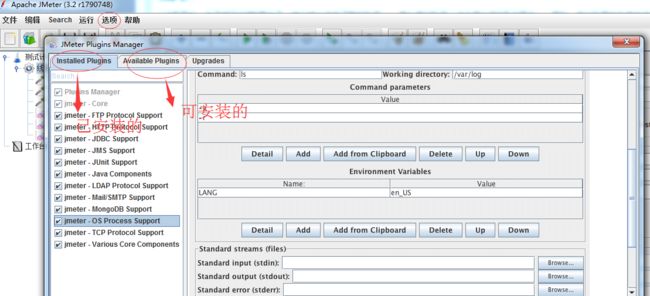
3、安装集群收集服务器信息的插件
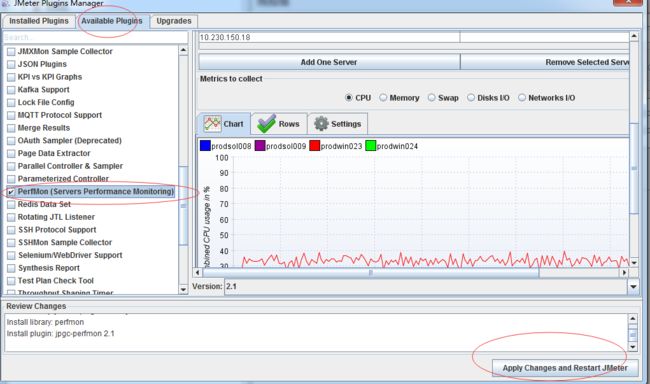
4、安装成功后会自己启动jmeter,查看是否安装成功,如图所示:
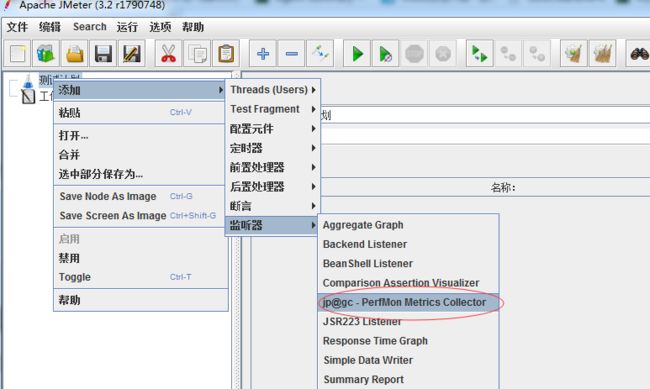
4.下载https://jmeter-plugins.org/wiki/PerfMonAgent/将下载的zip包解压到服务器上面,
如果你是linux(需要jre环境),就进入serverAgent目录,运行startAgent.sh命令,
如下:启动:>>./startAgent.sh --udp-port 0 --tcp-port port(agent起来之后所监听的端口)
停止:>>./startAgent.sh --udp-port 0 --auto-shutdown
接着修改:jmeter.save.saveservice.thread_counts=true
如果你是windows环境:进入serverAgent目录,直接双击startAgent.bat,启动agent
注:agent启动默认监听的端口是4444
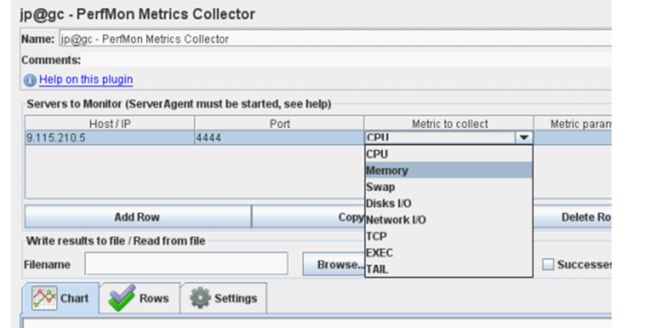
认识PerfMon
里面具体参数参考一下文档:
http://code.google.com/p/jmeter-plugins/wiki/PerfMon
http://code.google.com/p/jmeter-plugins/wiki/PerfMonMetrics
2、概念:Threads:这个组件主要用来控制Jmeter并发时产生线程的数量,在它的下一级菜单下只有一个组件(线程组),可以这么理解每个线程就是一个虚拟的用户。所有的其他类型组件必须是(线程组)节点的子节点。
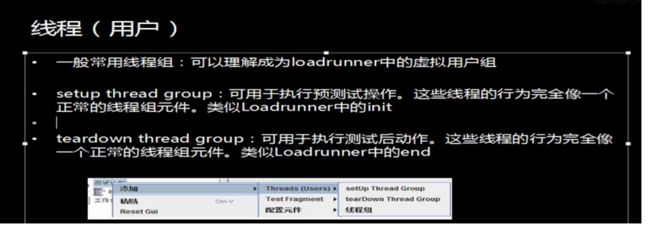
每个线程均独立运行测试计划。因此,线程组常用来模拟并发用户访问。假如客户机没有足够的能力来模拟较重的负载,可以使用Jmeter的分布式测试功能来通过一个Jmeter控制台来远程控制多个Jmeter引擎完成测试。
参数ramp-up
period用于告知JMeter要在多长时间内建立全部的线程。默认值是0。假如未指定ramp-up period,也就是说ramp-up period为零,JMeter将立即建立所有线程,假设ramp-up period设置成T秒,全部线程数设置成N个,JMeter将每隔T/N秒建立一个线程。
线程组的大部分参数是不言自明的,只有ramp-up period有些难以理解,因为如何设置适当的值并不轻易。首先,假如要使用大量线程的话,ramp-up period一般不要设置成零。因为假如设置成零,Jmeter将会在测试的开始就建立全部线程并立即发送访问请求,这样一来就很轻易使服务器饱和,更重要的是会隐性地增加了负载,这就意味着服务器将可能过载,不是因为平均访问率高而是因为所有线程的第一次并发访问而引起的不正常的初始访问峰值,可以通过Jmeter的聚合报告监听器看到这种现象。
这种异常不是我们需要的,因此,确定一个合理的ramp-up period的规则就是让初始点击率接近平均点击率。当然,也许需要运行一些测试来确定合理访问量。
基于同样的原因,过大的ramp-up period也是不恰当的,因为将会降低访问峰值的负载,换句话说,在一些线程还未启动时,初期启动的部分线程可能已经结束了。
那么,如何检验ramp-up
period I太小了或者太大了呢?首先,推测一下平均点击率并用总线程除点击率来计算初始的ramp-up period。例如,假设线程数为100,估计的点击率为每秒10次,那么估计的理想ramp-up period就是100/10 = 10秒。那么,应怎样来提出一个合理的估算点击率呢?没有什么好办法,必须通过运行一次测试脚本来获得。

其次,在测试计划(testplan)中增加一个聚合报告监听器,如图2所示,其中包含了所有独立的访问请求(一个samplers)的平均点击率。第一次取样的点击率(如http请求)与ramp-up period和线程数量密切相关。通过调整ramp-up period可以使首次取样的奠基率接近平均取样的点击率。

http://www.cnblogs.com/fnng/archive/2012/12/21/2828440.html基础原件介绍
http://www.cnblogs.com/puresoul/p/4886574.html控制器的介绍
JMeter的主要测试组件总结如下:
1.测试计划是使用JMeter进行测试的起点,它是其它JMeter测试元件的容器。
2.线程组代表一定数量的并发用户,它可以用来模拟并发用户发送请求。实际的请求内容在Sampler中定义,它被线程组包含。
3.监听器负责收集测试结果,同时也被告知了结果显示的方式。
4.逻辑控制器可以自定义JMeter发送请求的行为逻辑,它与Sampler结合使用可以模拟复杂的请求序列。
5.断言可以用来判断请求响应的结果是否如用户所期望的。它可以用来隔离问题域,即在确保功能正确的前提下执行压力测试。这个限制对于有效的测试是非常有用的。
6.配置元件维护Sampler需要的配置信息,并根据实际的需要会修改请求的内容。
7.前置处理器和后置处理器负责在生成请求之前和之后完成工作。前置处理器常常用来修改请求的设置,后置处理器则常常用来处理响应的数据。
8.定时器负责定义请求之间的延迟间隔。
jmeter分布式集群
jmeter分布式集群注意3问题
(1)集群的机器安装的jmeter版本一致
(2)调度机(master)和执行机(slave)最好分开,由于master需要发送信息给slave并且会接收slave回传回来的测试数据,所以mater自身会有消耗,所以建议单独用一台机器作为mater
(3)参数文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样的
(4)每台机器上安装的Jmeter版本和插件最好都一致,否则会出一些意外的问题
分布式集群原理
1、Jmeter分布式测试时,选择其中一台作为调度机(master),其它机器做为执行机(slave)。
2、执行时,master会把脚本发送到每台slave上,slave拿到脚本后就开
始执行,slave执行时不需要启动GUI,我理解它应该是通过命令行模式执行的。
3、执行完成后,slave会把结果回传给master,master会收集所有slave的信息并汇总。
集群配置
执行机
(1)执行机启动bin目录下的:jmeter-server.bat,启动成功如下图:

(2)参数文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路
调度机
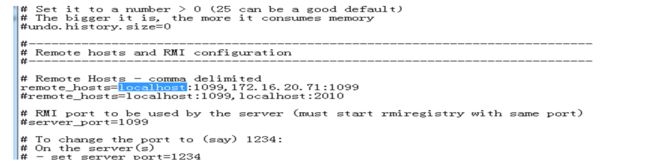
(1)找到Jmeter的bin目录下jmeter.properties文件,修改如下配置,IP和Port是slave机的IP以及自定义的端口
多台slave之前用","隔开,我这配置了2台,如图所示:一台是自己的,另一台是同事的
(2)执行机启动bin目录下的:jmeter-server.bat
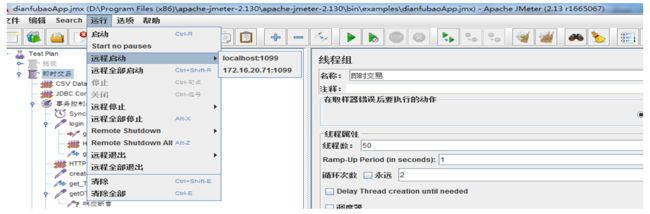
(3)打开Jmeter,选择运行,有运程启动、运程全部启动两个选项:
自定义端口:
上面其实已经实现了Jmeter的分布式测试,这部分主要介绍下如何自定义slave端口:
1、slave:在slave机的Jmeter的bin目录下,找到jmeter.properties文件,修改如下两个配置项,比如我这里修改为1888:
server_port=1888
server.rmi.localport=1888
2、启动slave机上的jmeter-server.bat,验证端口是否已经修改为:1888
3、master:修改master机器的jmeter.properties文件:
remote_hosts=10.13.223.202:1000,10.13.225.12:1888
4、重启jmeter.bat,验证端口是否已经变了:
通过ServerAgent监控服务器的cpu memory等信息,监听的服务器必须先运行startAgent服务

软件测试交流群
