什么是Sed
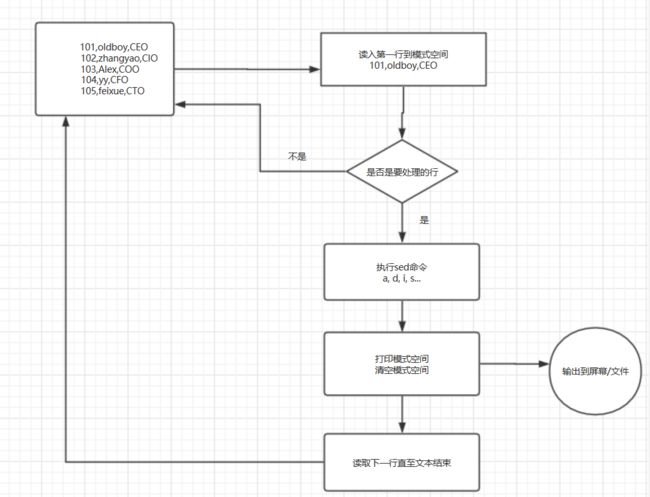
sed是一种流编辑器,它是文本处理中非常有用的工具,能够完美的配合正则表达式使用, 处理时,把当前处理的行存储在临时缓冲区中,称为『模式空间』(patternspace),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。
sed用法
功能说明
sed ----------> stream editor 流编辑 --------> 增删改查,过滤,取行
sed默认对所有行处理
语法
sed [options] [sed-commands] [input-files] ---------------> sed 语句
input-files 可以是文本,也可以是标准输入
执行流程
模式空间:sed 软件在内存里的临时的一个缓存空间,存放读取的内容
数字处理
n1[,n2][sed-commands] (n1,n2表示地址范围,n2为可选项)
10 [sed-commands] 对第10行执行sed命令
10,20 [sed-commands] 对第10到20行执行sed命令
10,+20 [sed-commands] 对第10行开始的20行执行sed 命令
1~2 [sed-commands] 对所有奇数行执行sed 命令(第一行开始,步长为2,直到最后一行)
2~2 [sed-commands] 对所有偶数行执行sed 命令 (第二行开始,步长为2,直到最后一行)
10,$ [sed-commands] 对第10行到最后一行执行sed命令正则匹配/字符串处理
/zhangyao/ [sed-commands] 匹配zhangyao这一行执行sed 命令
/zhangyao/,/Alex/ [sed-commands] 匹配zhangyao到Alex 之间的行执行sed命令
/zhangyao/,$ [sed-commands] 匹配zhangyao这一行到最后一行执行sed命令混合数字+字符串匹配
10,/Alex/ [sed-commands] 匹配第10行到包含Alex字段的这一行执行sed命令
/Alex/,10 [sed-commands] 匹配Alex字段的这一行到第10行执行sed命令
/zhangyao/,+20 [sed-commands] 匹配包含zhangyao这个字段的这一行到其后的20行执行sed命令选项说明
| 选项 | 说明 |
|---|---|
| -n | 取消默认输出 |
| -i | 修改文件 |
| -f | 后接sed脚本文件名 |
| -r | 使用扩展正则表达式 |
| -e | 执行多条sed命令 |
| -i.bak | 先备份再替换 |
sed命令说明
[sed-commands]
| 命令 | 说明 |
|---|---|
| a | 追加 |
| i | 插入 |
| d | 删除 |
| c | 替换指定的行 |
| s | 替换指定字符串 ( g 命令的替换标志-全局替换标志) |
| p | 打印 |
| $ | 结尾 |
实例
添加
$ cat person.txt
101,oldboy,CEO
102,zhangyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO单行增加
在第三行追加数据
>>>> 使用命令a
$ sed -i '2a 106,dandan,CSO' person.txt
$ sed -n '3p' person.txt
106,dandan,CSO在第二行插入数据
在第2行添加数据
>>>> 使用命令i
$ sed -i '2i 110,yyy,xxx' person.txt
$ sed -n '2p' person.txt
110,yyy,xxx多行增加
在第三行添加三条数据
$ sed -i '2a 106,dandan,CSO\n107,yyy,xxx\n108,hhpsb,mmm' person.txt
$ sed -n '3,5p' person.txt
106,dandan,CSO
107,yyy,xxx
108,hhpsb,mmm在第二行添加多条数据
$ sed -i '2i 106,dandan,CSO\n107,yyy,xxx\n108,hhpsb,mmm' person.txt
$ sed -n '2,4p' person.txt
106,dandan,CSO
107,yyy,xxx
108,hhpsb,mmm删除
全部删除
不加任何地址范围
$ sed -i 'd' person.txt删除一行
$ cat -n person.txt
1 101,oldboy,CEO
2 106,dandan,CSO
3 107,yyy,xxx
4 108,hhpsb,mmm
5 102,zhangyao,CTO
6 103,Alex,COO
7 104,yy,CFO
8 105,feixue,CIO
$ sed -i '2d' person.txt
$ cat -n person.txt
1 101,oldboy,CEO
2 107,yyy,xxx
3 108,hhpsb,mmm
4 102,zhangyao,CTO
5 103,Alex,COO
6 104,yy,CFO
7 105,feixue,CIO批量删除
$ cat -n person.txt
1 101,oldboy,CEO
2 107,yyy,xxx
3 108,hhpsb,mmm
4 102,zhangyao,CTO
5 103,Alex,COO
6 104,yy,CFO
7 105,feixue,CIO- 删除第2行到第5行
$ sed -i '2,5d' person.txt
$ cat -n person.txt
1 101,oldboy,CEO
2 104,yy,CFO
3 105,feixue,CIO- 删除第2行到最后1行
$ sed -i '2,$d' person.txt
$ cat -n person.txt
1 101,oldboy,CEO$ cat -n person.txt
1 1101,oldboy,CEO
2 2107,yyy,xxx
3 3108,hhpsb,mmm
4 4102,zhangyao,CTO
5 5103,Alex,COO
6 6104,yy,CFO
7 7105,feixue,CIO删除奇数行 (隔行删除~)
$ sed -i '1~2d' person.txt
$ cat -n person.txt
1 2107,yyy,xxx
2 4102,zhangyao,CTO
3 6104,yy,CFO打印文件内容(排除oldboy)
$ sed '/oldboy/d' person.txt
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO替换
- c选项
$ sed -i '2c 106,dandan,CSO' person.txt
$ sed -n '2p' person.txt
106,dandan,CSOs 选项
g为全局替换标志
替换模型
sed -i 's# # #g' person.txtsed -i 's/ / /g' person.txt替换模型完整版
Ms# # #NgMs对第M行操作 无g标志,对匹配的第1列处理;如果有g,对这一行操作Ng从第N处/列开始往后全部替换MsNg对第M行从第N处匹配替换
替换指定的行
$ cat person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO不区分大小写替换i
$ sed 's#ceo#coo#ig' person.txt
1101,oldboy,coo
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO永久关闭SELINUX
$ sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
$ grep -v '^#' /etc/selinux/config|grep -wi 'selinux'
SELINUX=disabled优化ssh配置
$ grep -wn 'PermitRootLogin' /etc/ssh/sshd_config
38:#PermitRootLogin yes
90:# the setting of "PermitRootLogin without-password".
$ grep -wn 'Port' /etc/ssh/sshd_config
17:#Port 22
$ grep -wn 'PermitEmptyPasswords' /etc/ssh/sshd_config
64:#PermitEmptyPasswords no
$ grep -wn 'UseDNS' /etc/ssh/sshd_config
115:#UseDNS yes
$ grep -wn 'GSSAPIAuthentication' /etc/ssh/sshd_config
79:GSSAPIAuthentication yes
>>>> 优化
sed -i.bak 's#GSSAPIAuthentication yes#GSSAPIAuthentication no#' /etc/ssh/sshd_config
sed -i '20a # ssh configure better\nPort 52113\nPermitRootLogin no\nPermitEmptyPasswords no\nUseDNS no' /etc/ssh/sshd_config获取ip地址
$ ip a s eth0
2: eth0: mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:bf:09:c9 brd ff:ff:ff:ff:ff:ff
inet 192.168.142.40/24 brd 192.168.142.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
>>> 方法1
$ ip a s eth0 |sed -n '3p'|sed -r 's/.*t (.*)\/.*/\1/g'
>>> 方法2
$ ip a s eth0|awk 'NR==3{print $2}'|sed -r 's/(.*)\/.*/\1/g'
>>>> 方法3
$ hostname -I
192.168.142.40
>>>> 方法4
$ hostname -i
192.168.142.40 分组替换
s#\(\)# \1#g 匹配小括号里的元素
$ echo "I am oldboy teacher" |sed -r 's#.*am (.*) .*#\1#g'
oldboy系统开机启动项优化
>>>> 将服务名弄出来
$ systemctl list-unit-files|awk '/sshd/{print $1}'
sshd-keygen.service
sshd.service
[email protected]
sshd.socket
>>>> 通过分组替换拼字符串
$ systemctl list-unit-files|awk '/sshd/{print $1}'|sed -r 's/(.*)/systemctl enable \1/g'
systemctl enable sshd-keygen.service
systemctl enable sshd.service
systemctl enable [email protected]
systemctl enable sshd.socket
>>>> 通过bash命令将字符串当成命令执行
$ systemctl list-unit-files|awk '/sshd/{print $1}'|sed -r 's/(.*)/systemctl enable \1/g'|bash批量重命名文件
>>>> 创建文件
$ for i in `seq 1 5`;do touch stu_10299_${i}.jpg;done
$ ll *.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_10299_1.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_10299_2.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_10299_3.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_10299_4.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_10299_5.jpg
>>>> 拼字符串
$ ls *.jpg |sed -r 's#([a-Z]+)_[0-9]+_([0-9])+(.*)#mv & \1_\2\3#g'
mv stu_10299_1.jpg stu_1.jpg
mv stu_10299_2.jpg stu_2.jpg
mv stu_10299_3.jpg stu_3.jpg
mv stu_10299_4.jpg stu_4.jpg
mv stu_10299_5.jpg stu_5.jpg
>>>> 通过bash命令将字符串当成命令执行
>>>>方法1
$ ls *.jpg |sed -r 's#([a-Z]+)_[0-9]+_([0-9])+(.*)#mv & \1_\2\3#g'|bash
>>>>方法2
$ ls *.jpg |sed -r 's#(.*_).*_(.*)#mv & \1\2#g'|bash
$ ll *jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_1.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_2.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_3.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_4.jpg
-rw-r--r--. 1 root root 0 9月 23 16:05 stu_5.jpg给2行相同的数据中的其中一行加注释
$ cat fstab
derot2npchs03-hcpsc01fi2222:/vol1_HH001QC/q_sysfiles/sapmnt /sapmnt/A2X nfs rw,nolock,proto=tcp,rsize=32768,wsize=32768 0 0
derot2npchs03-hcpsc01fi2222:/vol1_HH001QC/q_sysfiles/sapmnt /sapmnt/A2X nfs rw,nolock,proto=tcp,rsize=32768,wsize=32768 0 0
$ sed -i '1s/derot2npchs03-hcpsc01fi2222.*/#&/1' fstab
$ grep '^#' fstab
#derot2npchs03-hcpsc01fi2222:/vol1_HH001QC/q_sysfiles/sapmnt /sapmnt/A2X nfs rw,nolock,proto=tcp,rsize=32768,wsize=32768 0 0执行命令
$ cat file.txt
/etc/passwd
/etc/vimrc
/etc/hostname
$ sed 's#^#ls -ld #e' file.txt
-rw-r--r--. 1 root root 989 9月 16 17:27 /etc/passwd
-rw-r--r--. 1 root root 1982 8月 9 11:17 /etc/vimrc
-rw-r--r--. 1 root root 5 9月 22 09:18 /etc/hostname说明: 这里就是拼凑字符串, ^每读入file.txt中的一行一行就匹配,然后 执行第二个#后的命令, 命令后面一定要有空格, 相当于从文件读入参数给到命令ls -ld
获取行号(=)
$ sed '=' person.txt
1
1101,oldboy,CEO
2
2107,yyy,xxx
3
3108,hhpsb,mmm
4
4102,zhangyao,CTO
5
5103,Alex,COO
6
6104,yy,CFO
7
7105,feixue,CIO单行输出行号
$ sed '=' person.txt|sed 'N;s#\n#-->#g'
1-->1101,oldboy,CEO
2-->2107,yyy,xxx
3-->3108,hhpsb,mmm
4-->4102,zhangyao,CTO
5-->5103,Alex,COO
6-->6104,yy,CFO
7-->7105,feixue,CIO取出/etc/services中的5,35,70行
$ sed -n '5p;35p;70p' /etc/services |sed '='|sed 'N;s#\n#-->#g'
1--># IANA services version: last updated 2013-04-10
2-->qotd 17/tcp quote
3-->whois++ 63/udp whoispp不清空数据读入下一行(N)
不清空模式空间的数据, 以\n分隔2行
$ sed '=' person.txt |sed 'N;s#\n# #'
1 1101,oldboy,CEO
2 2107,yyy,xxx
3 3108,hhpsb,mmm
4 4102,zhangyao,CTO
5 5103,Alex,COO
6 6104,yy,CFO
7 7105,feixue,CIO将文件的内容横向输出
$ cat 1.txt
vsa5228517
vsa5890477
vsa5890477
vsa5890477
vsa6283258
$ sed ':a;N;s#\n# #;ta' 1.txt
vsa5228517 vsa5890477 vsa5890477 vsa5890477 vsa6283258说明 : :a和ta 是一对符号,:a是先做一个标记,然后如果ta之前执行成功,则跳转到:a标识符继续执行,达到了循环的效果, 可以理解为 :a与ta之间是 for循环语法中的do和done之间的命令
横向输出postfix的PID
$ ps aux |grep postfix|awk 'NR!=1{print $2}'|sed ':a;N;s#\n# #;ta'
7337 14523 14879不常用选项
先执行命令, 再过滤({})
$ cat person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO
>>>> 不加{}, 所有的行号都显示
$ sed -n '2,4p;=' person.txt
1
2107,yyy,xxx
2
3108,hhpsb,mmm
3
4102,zhangyao,CTO
4
5
6
7
>>>> 将命令放在{}里, 则先执行命令, 然后多条命令的结果再次进行筛选
>>>> 只显示限制条件的行号
$ sed '2,4{p;=}' person.txt
1101,oldboy,CEO
2107,yyy,xxx
2
2107,yyy,xxx
3108,hhpsb,mmm
3
3108,hhpsb,mmm
4102,zhangyao,CTO
4
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO打印不可见字符
格式:sed 'l'
$ sed 'l' person.txt
1101,oldboy,CEO$
1101,oldboy,CEO
2107,yyy,xxx$
2107,yyy,xxx
3108,hhpsb,mmm$
3108,hhpsb,mmm
4102,zhangyao,CTO$
4102,zhangyao,CTO
5103,Alex,COO$
5103,Alex,COO
6104,yy,CFO$
6104,yy,CFO
7105,feixue,CIO$
7105,feixue,CIO转换字符
格式: sed 'y#待替换字符串#替换字符串#' person.txt
$ sed 'y#abc#ABC#' person.txt
1101,oldBoy,CEO
2107,yyy,xxx
3108,hhpsB,mmm
4102,zhAngyAo,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO退出sed 软件 q
sed Nq
N代表行号, Nq代表在第几行停止读取
$ sed '3q' person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm合并文件
$ cat num.txt
1 1 0 1 0
1 1 0 1 0
1 1 0 1 0
1 1 0 1 0
1 1 0 1 0
$ cat person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO
>>>> 合并文件
$ sed '$r num.txt' person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO
1 1 0 1 0
1 1 0 1 0
1 1 0 1 0
1 1 0 1 0
1 1 0 1 0清空数据读入下一行(n)
当使用命令n, 则清空, 直接读入下一行
$ sed -n 'p' person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO
$ sed -n 'n;p' person.txt
2107,yyy,xxx
4102,zhangyao,CTO
6104,yy,CFO说明:读取第一行 1101,oldboy,CEO, 碰到n命令, 直接丢弃, 读下一行 2107,yyy,xxx, 遇到p命令打印, 以此类推
模拟其他命令
$ cat person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO模拟cat命令
$ cat person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO
$ sed "" person.txt
1101,oldboy,CEO
2107,yyy,xxx
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO模拟grep -v
$ grep -v 'yyy' person.txt
1101,oldboy,CEO
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO
$ sed -n '/yyy/ !p' person.txt
1101,oldboy,CEO
3108,hhpsb,mmm
4102,zhangyao,CTO
5103,Alex,COO
6104,yy,CFO
7105,feixue,CIO模拟head 命令
$ head -2 person.txt
1101,oldboy,CEO
2107,yyy,xxx
$ sed '3,$d' person.txt
1101,oldboy,CEO
2107,yyy,xxx模拟wc 命令
$ wc -l person.txt
7 person.txt
$ sed -n '$=' person.txt
7